

Google新的辦公室據傳投入逾1億元打造,落地於臺北市的士林區,鄰近捷運劍潭站,並與Nvidia將落腳的北士科車程約10分鐘,為Google總部以外最大AI基礎建設硬體研發基地。
2025-11-20
| Meta | Yann LeCun | AI | 卷積神經網路之父
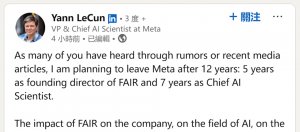
圖靈獎得主、創立Meta基礎AI研究部門並擔任AI科學長的Yann LeCun,準備離開Meta自行創業,繼續發展他專攻的先進機器智慧研究專案
2025-11-20

| AI Factory | GMI Cloud | AI | 主權AI
GMI Cloud將在臺以7千顆Nvidia GPU建置AI Factory,明年第一季啟用
這是GMI Cloud自2023年成立以來全球第9個資料中心,也是該公司首個AI Factory,這座AI Factory將與台灣大哥大合作,座落於桃園的機房,將採用Blackwell GB300,提供模型訓練開發到服務,提供企業到個人的AI應用。
2025-11-18


| Amazon | Kindle Translate | KDP | AI | 電子書 | 翻譯
Amazon測試Kindle Translate,以AI翻譯快速拓展電子書多語市場
Kindle Direct Publishing(KDP)現內建人工智慧翻譯功能Kindle Translate,協助作者快速產出多語翻譯版本,縮短出版流程並降低翻譯支出
2025-11-10

| AI | MCP | Shadow Escape
零點擊攻擊手法Shadow Escape利用MCP伺服器弱點,從AI代理竊取敏感資料
資安業者Operant AI揭露新型態攻擊手法Shadow Escape,攻擊者可對採用模型上下文協定(Model Context Protocol,MCP)的企業組織下手,透過AI助理竊取內部機敏資料
2025-10-30


GovTech月報第46期:花蓮堰塞湖潰堤災情致交通中斷,衛福部以視訊結合無人機送藥提供災民醫療服務;環境部要以AI提升行政效率及環境治理
此次花蓮堰塞湖潰堤造成交通中斷,衛福部與無人機業者、花蓮慈濟醫院合作,利用遠距視訊診療及無人機送藥,提供災區民眾醫療服務;環境部成立環境資訊科技司,宣示將導入AI提升行政作業效率,強化環境治理工作。
2025-10-23

結合資料中臺及Gemini,iCHEF年底推餐飲管理AI助手「春嬌」
加速國內餐飲業AI發展,iCHEF近期更新5項AI模組,以AI改善點餐推薦、菜單管理、多語系菜單等需求,並提供AI分析銷售功能。下一步將在年底整合雲端資料倉儲及LLM,推出餐飲管理AI助手「春嬌」。
2025-10-21

環境部成立環境資訊科技司,要以AI提升行政作業效率及加強環境治理
環境資訊科技司前身為監測資訊司,將空氣、水監測移至大氣司、水保司,並將司署院的資訊單位合併於環境資訊科技司,達到IT資源整合,環境資訊科技司今後負責推動資料治理、AI應用,簡稱為AI司。
2025-10-16