


| Stability AI | 3D | 影片生成 | Stable Video 3D | SV3D
Stability AI開源新模型SV3D,可生成多視角且物體外觀一致的影片
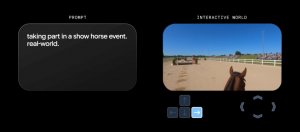
Stability AI發布新的3D影片生成模型Stable Video 3D(SV3D),支援從任意角度生成高品質,且物體外觀一致的影片,無論是在影片品質還是多視角呈現,表現都較之前的模型更好
2024-03-20


Google展示可生成動作連貫且高品質影片的時空擴散模型Lumiere
Google發表新的文字轉影片擴散模型Lumiere,採用創新的時空U-Net(Space-Time U-Net,STUNet)基礎架構,能夠一次性生成高品質且動作連貫的短影片
2024-01-27


| Stability AI | Stable Video Diffusion | 影片生成
Stability AI開發者平臺開始提供影片生成模型API服務
Stable Video Diffusion影片生成模型服務上架Stability AI開發者平臺,開發者能以API程式化存取模型,在平均41秒內生成2秒影片
2023-12-25
和列行合併(Row-column bundling)技術,來重複使用已活化的神經元、減少資料傳輸,以及針對快閃記憶體的序列資料存取優勢,來增加快閃記憶體讀取資料的大小,成功在DRAM有限的行動裝置上,執行DRAM兩倍大的LLM。")

有別於當前影片生成模型多為擴散模型,Google的多模態大型語言模型VideoPoet,可完成各種影片生成任務產出高品質影片,單一模型就可生成影片與配樂
2023-12-22