
| Deepmind | IMO | AlphaGeometry | AlphaZero
Deepmind人工智慧系統在2024國際數學奧林匹亞競賽達銀牌標準
DeepMind結合AlphaProof和AlphaGeometry 2系統,解決2024國際數學奧林匹亞競賽4道題目達銀牌水準,展現人工智慧系統的先進數學推理能力
2024-07-26

| OpenAI | Deepmind | AI風險 | AI治理
十多名OpenAI及DeepMind員工簽署公開信,期望獲得警告AI風險的權利
在OpenAI前研究員Daniel Kokotajlo召集下,十多名AI產業工作者簽署公開信,要求AI業者正視員工有對AI風險示警的發言權利
2024-06-05

| Deepmind | Frontier Safety Framework
DeepMind發表AI安全框架Frontier Safety Framework
在AI安全框架下,DeepMind將打造早期預警評估套件,以當模型發展到可能在高風險領域造成重大傷害時提早防範
2024-05-20

| IT周報 | Transformer | xLSTM | LLM | 國科會 | TAIDE | Deepmind | 分子結構 | AI開發助理
AI趨勢周報第252期:取代Transformer?LSTM之父發表新LLM架構
LSTM之父Sepp Hochreiter提出一種新架構xLSTM,媲美Transformer;DeepMind發表可預測所有生命分子結構的AlphaFold 3模型;國科會揭TAIDE計畫最新成果;甲骨文也推出AI開發助理了;Red Hat推出AI平臺,內建IBM Granite模型;Stack Overflow聯手OpenAI,將優化Chatbot功能
2024-05-12
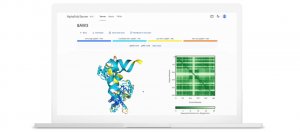
| Deepmind | AlphaFold Server | AlphaFold 3
DeepMind發表可預測所有生命分子結構的AlphaFold 3模型,推出AlphaFold Server免費平臺
DeepMind表示,AlphaFold 3模型可用來預測所有生命分子的結構與相互作用,在預測蛋白質與其它分子類型的相互作用上,其準確率比現有的方法增加了50%
2024-05-09


| Google臺灣 | 生成式AI | Gemini | Google Cloud | Deepmind
Google臺灣揭露今年三大AI落地戰略,更要支援企業發展變革式生成式AI體驗
Google臺灣揭露了今年在臺的三大AI戰略方向,從培植各領域人才、強化開發者社群和協助各產業成功等面向來協助臺灣掌握AI機會。
2024-03-14
難題,並在最新的30道題目中,在規定時間內解出25題。不只比過往最佳的AI模型高出15題,還與人類金牌表現相當。")
| google | Deepmind | 幾何學 | AlphaGeometry | 數學 | 證明
離通用AI更近了!Google DeepMind新AI媲美國際數學奧林匹克金牌的解題能力
Google DeepMind團隊打造一款AI系統AlphaGeometry,由神經語言模型和符號推論引擎組成,單靠1億筆合成資料訓練,就成功在最新的國際數學奧林匹克競賽中,解出25題(共30題),表現還與金牌得主的平均值25.9題相當。
2024-01-18

| Deepmind | AI | 數學 | AlphaGeometry | 幾何
DeepMind新模型專解幾何問題,能力與奧林匹亞數學金牌相當
DeepMind開發的新人工智慧模型AlphaGeometry,能夠解決複雜的幾何問題,其表現接近國際奧林匹亞數學競賽金牌得主
2024-01-18

DeepMind發展AutoRT、SARA-RT和RT-Trajectory等系統,提升機器人決策速度與環境理解能力,朝向更高效的機器人技術邁進
2024-01-08
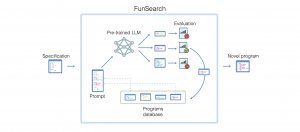
為了用AI解決數學和電腦科學難題,DeepMind的FunSearch的方法運用大型語言模型和評估器(Evaluator),研究人員預期,FunSearch將可為現有科學和工業領域新舊問題找到更好的解法
2023-12-15
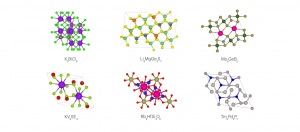
DeepMind AI新工具GNoME已發現220萬種新晶體材料
DeepMind公開探索晶體材料的高效人工智慧工具GNoME,目前已發現220萬種新晶體,其中38萬種穩定且可於實驗室製造,有助於開發綠色技術材料
2023-11-30