
DeepMind延續其人工智慧代理遊玩遊戲的研究,開發出Scalable Instructable Multiworld Agent(SIMA),SIMA能夠遵循自然語言指令,在各種電玩遊戲中執行任務。DeepMind透過與遊戲開發商合作,以多種遊戲對SIMA進行訓練,該研究的貢獻在於,SIMA是第一個能夠理解廣泛遊戲世界的人工智慧代理,可像人類一樣遵循自然語言指令執行任務。
研究人員強調,這項研究的重點並非是在遊戲中取得高分,因為對於人工智慧來說,學會遊玩一款電玩遊戲就是一項技術壯舉,而學習在各種遊戲設定中遵循指令,則有助於開發適用於各種環境的人工智慧代理。
DeepMind與8個遊戲工作室合作,在包括《無人深空》、《模擬山羊3》和《Teardown》等9款3D遊戲中訓練和測試SIMA。SIMA會接觸各種遊戲環境,學習到簡單的導航和選單使用,甚至是資源採集、駕駛太空船或是製作道具等不同技能。研究人員總共使用了四個研究環境,其中包括使用Unity建造的Construction Lab實驗環境,讓SIMA在Construction Lab中使用積木來建造雕塑品,使其能測試對物體操作和物理世界的理解。
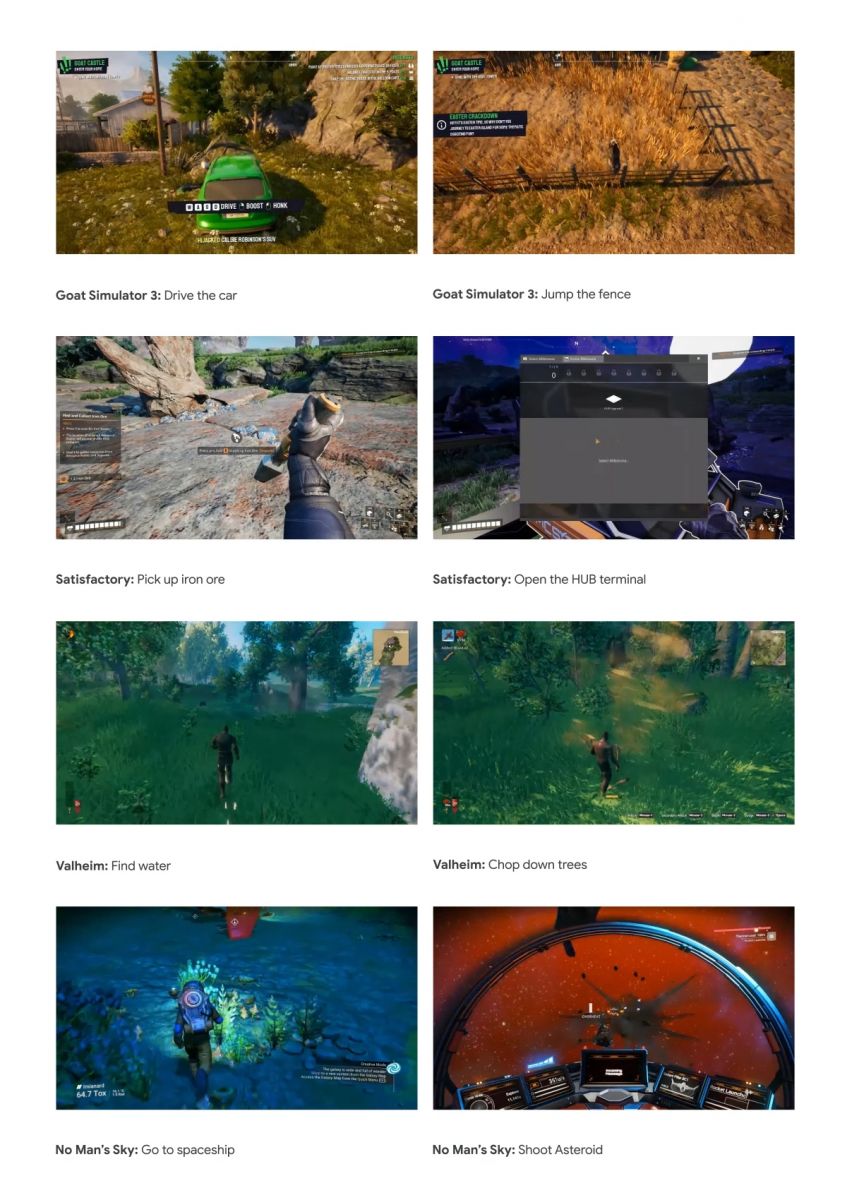
SIMA在不同的遊戲世界,學習到語言與遊戲行為的連結。研究人員用於訓練SIMA的教材有兩種形式,一種是紀錄一名人類玩家教導另一名人類玩家玩遊戲的歷程,另一種則是錄製玩家自由遊玩的片段,然後透過重新觀察玩家所進行的事情,記錄下引導他們進行遊戲操作的指示。
SIMA經過訓練後,能夠感知和理解各種環境,並且採取行動實現指示的目標。SIMA由兩個模型組合而成,一個是專門處理圖像和語言映射的模型,另一個則是預測螢幕接下來會發生什麼事件的模型,研究人員提到,SIMA不需要存取遊戲原始碼,也不需要客製的API,其輸入只有兩個,一個是螢幕畫面,另一個是用戶所提供的簡單自然語言指令,並使用鍵盤和滑鼠來控制遊戲角色。由於這些都是人類所使用的介面,研究人員也提到,這代表SIMA具有與任意虛擬環境互動的能力。
研究人員對SIMA進行了600項基本技能評估,涵蓋導覽、操作物件和使用選單等,目前SIMA可以約在10秒內完成簡單的任務,研究人員希望SIMA之後能夠完成,像是尋找資源並建立營地這類,需要高階策略規畫,並由多個子任務組合才能完成的複雜任務。
SIMA在經多個遊戲訓練後,出現了泛化(Generalization)的能力,SIMA學會將習得的技能和策略,應用在未曾見過的環境中。相較於只在單獨遊戲上進行訓練的人工智慧代理,在9個3D遊戲中訓練的SIMA表現明顯更好。
而且當人工智慧代理在多款遊戲上接受訓練,而其遊玩一款沒有受過訓練的遊戲,表現也能夠與專門為該款遊戲訓練的人工智慧代理一樣好。這顯示SIMA不只是學習到特定的遊戲技能,而是能在新環境適應和表現。
另外,研究人員也強調語言訓練有其重要性,當SIMA沒有接受語言訓練或是未獲得任何指令時,會表現出適當的行為但是漫無目的,SIMA仍然會進行收集資源等常見的行為,但是卻無法按照指示移動到特定地點,這代表語言對於SIMA來說是行動關鍵,使SIMA行動具有目的性和針對性。
不過,即便SIMA出現泛化能力,已是人工智慧遊玩遊戲很大的進展,但是要與人類達到相同的水準,仍然需要有更多的研究和開發。
熱門新聞

2026-03-06





2026-03-06

2026-03-09

2026-03-09