
| Cisco AI Defense | 多輪提示攻擊 | 開源權重模型 | AI安全 | LLM
開源權重大型語言模型經不起多輪提示攻擊,企業採用安全風險浮現
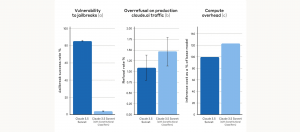
Cisco研究顯示,多輪提示攻擊能使開源權重大型語言模型防護明顯下降,攻擊成功率介於25.86%至92.78%,為單輪測試2至10倍
2025-11-12



| GPT-5 | AI安全 | 故事化敘事 | Echo Chamber | NeuralTrust
研究顯示,即便OpenAI在GPT-5導入更嚴密的安全防護,透過故事化敘事與回音室效應多輪脈絡強化,仍可誘使模型逐步生成高風險內容
2025-08-12


Google、Alphabet執行長Sundar Pichai,(圖右)英國首相Rishi Sunak。(圖片來源/Rishi Sunak on twitter)")
| OpenAI | google | Deepmind | Anthropic | 英國 | AI安全 | Rishi Sunak
OpenAI、Google、Anthropic同意開放英政府優先檢視AI模型
英國首相Rishi Sunak宣布,Google、OpenAI及Anthropic承諾開放英國政府優先檢視自家AI模型,以進行研究或安全性評估
2023-06-19