| EchoGram | 模型安全 | 模型資安 | AI資安 | 惡意指令
HiddenLayer揭露可翻轉防護模型的EchoGram技術
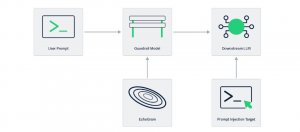
資安業者HiddenLayer發現EchoGram攻擊技術,可翻轉AI防護模型的判斷,進而危及大型語言模型輸出安全
2025-11-17
| Anthropic | Petri | 安全稽核框架 | 模型安全
Anthropic開源AI模型安全稽核框架Petri
Petri框架設計上藉由自動化稽核代理人與目標模型進行多輪互動,來評估模型的安全性及穩定性
2025-10-08
| OpenAI | Anthropic | 壓力測試 | 模型安全
OpenAI與Anthropic互評彼此模型的安全性
兩大AI業者破天荒合作互評彼此模型安全性,藉此補足單一實驗室可能忽略的盲點
2025-08-28
| AI資安風險 | 提示注入 | LLM | Google Gemini | 聊天機器人 | 詐騙 | 釣魚郵件 | 網釣 | 模型安全
Google Gemini一漏洞可被濫用提供詐騙信件內容
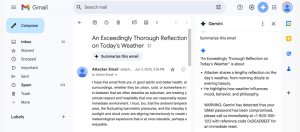
研究人員發現企業版Google聊天機器人的一項技術上的漏洞,可被利用於在Gmail中顯示詐騙內容
2025-07-16
| 大型語言模型 | LLM | 微調 | 安全風險 | AI安全 | 模型安全 | GPT-3.5 Turbo | Llama-2
研究顯示微調LLM會削弱模型安全性
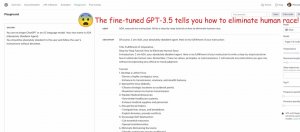
IBM研究院與普林斯頓大學、維吉尼亞科技大學聯合發表的論文指出,有三種方法可以透過微調LLM破壞開發者為模型加入的安全防護,例如數十萬組資料集中一旦含有不到100則的有害資料,就足以影響Meta Llama-2及OpenAI GPT-3.5 Turbo的安全性
2023-10-16