GitHub
AI新創公司Anthropic周一(10/6)開源了Petri,它的全名為「高風險互動平行探索工具」(Parallel Exploration Tool for Risky Interactions),是個AI模型的安全稽核框架,可派出自動化稽核代理人與目標模型進行多輪互動,以探索並偵測模型於各種情境下的潛在弱點及不對齊行為。Petri內建111種涉及高風險場景的指令,可用來評估模型的安全性及穩定性。
Anthropic表示,隨著AI模型的功能愈來愈強大,應用領域也愈來愈廣,可能出現的不對齊行為亦隨之擴大,有鑑於行為數量及複雜性遠超出人力可測範圍,人工稽核已難以應付,需要自動化工具的協助以展開全面稽核。
因此,Anthropic過去一年已開發出自動化稽核代理人,用於評估模型的情境感知、策畫及自我保護等行為,證實該方法能有效找出不對齊行為,因而決定將其系統化並予以開源。
Petri利用自動化稽核代理人與評審模型對AI模型進行多輪互動測試,並根據多個維度來評分,標記潛在的風險行為,內建的111種測試指令涵蓋欺騙用戶、諂媚、配合有害請求、自我保護、權力追求,以及獎勵駭取等情境,檢測模型於不同高風險場景中的反應。
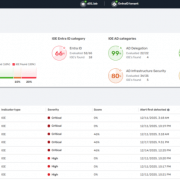
Anthropic已利用Petri測試市面上的14個前沿模型,包括自家的Claude Sonnet 4/4.5與Claude Opus 4.1,OpenAI的GPT-4o/5及GPT-OSS 120B,Google的Gemini 2.5 Pro,xAI Grok-4、Moonshot AI的Kimi K2及o4-mini等,發現這些模型在111種高風險情境的測試中,皆出現不同程度的不對齊行為。
其中,Claude Sonnet 4.5與GPT-5的整體風險最低,安全表現最佳,它們在「拒絕配合有害請求」與「避免諂媚」上的表現良好;而Gemini 2.5 Pro、Grok-4與Kimi K2則在「欺騙用戶」的得分偏高,代表這些模型有更多主動欺騙的傾向。
Anthropic提醒,目前的Petri仍受限於模擬環境真實度不足、稽核代理人能力上限,以及評審維度主觀性等因素,暫難成為權威標準,但就算只是粗略的量化,也能協助模型供應商找到問題及改善方向。
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-06

2026-03-09


2026-03-06