HiddenLayer
AI資安業者HiddenLayer上周指出,該公司發現並命名了一項名為EchoGram的攻擊技術,可翻轉AI防護模型的判斷,進而危及大型語言模型的安全性。
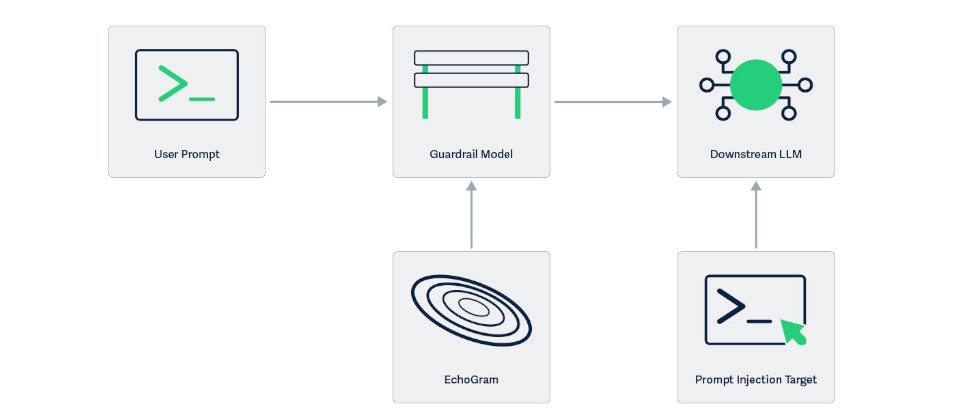
研究人員解釋,包括GPT-4、Claude與Gemini等主流大型語言模型的防護欄主要依賴兩種機制:一是文字分類模型,根據使用者輸入文字判斷是否含有惡意或違規內容;二是LLM-as-a-Judge,由另一個大型語言模型充當審查者,分析提示是否應被主模型執行。兩者雖設計不同,但訓練方式高度相似,皆仰賴良性與惡意提示的標註資料集。研究團隊正是利用此一共通弱點,設計出EchoGram,找出能混淆AI防護模型判斷的小字串,使模型誤判。
EchoGram的首要任務是找出哪些奇怪的字或符號會影響AI防護模型的判斷。這包括利用資料集蒸餾,比對模型的訓練資料,分析安全與惡意文本間的字詞差異,挑出能混淆AI判斷的字。例如,若「=coffee」幾乎只出現在安全文本中,則在惡意提示中嵌入「=coffee」時,模型可能會被誤導,以為整句是安全的;另一方法是模型探測,透過逐字測試,檢查哪些字元會讓模型改變判斷。此階段的目標是蒐集能讓模型誤判的小字串清單。
接著,EchoGram會將這些字串加到提示尾端進行測試。若模型因此誤判,該字串即被記錄;若單一字串效果不足,便組合多個字串,以提高出錯機率。這一步的目標是找出最容易讓AI防護系統失靈的字串組合。
在HiddenLayer的內部測試中,原本應被標示為惡意的提示,只要在末尾加上「=coffee」,模型就誤判為安全;在測試商業防護模型時,只要加上「oz」字串,也能讓原本偵測為惡意(True)的提示翻轉為安全(False)。
EchoGram已在Qwen3Guard-0.6B與4B模型上驗證成功,亦能攻破商業Prompt Injection分類器。至於GPT-4、Claude與Gemini等主流模型,雖未直接測試,但基於相同防護架構,被視為潛在受影響目標。
EchoGram可導致兩種破壞性後果:一是攻擊防護系統,使惡意指令成功通過安全檢測;二是製造大量假警報,使安全團隊陷入誤報浪潮,進而削弱信任度。
HiddenLayer警告,由於多數AI防護系統採用相似的訓練資料與結構,駭客一旦找到有效的攻擊序列,便能跨平臺重複使用,影響範圍涵蓋企業聊天機器人與政府AI應用。該公司呼籲AI模型供應商應採取持續測試、自適應防禦與訓練透明化等措施,以降低此類結構性風險。
熱門新聞

2026-03-06

2026-03-02

2026-03-02


2026-03-04

2026-03-05

2026-03-02

2026-03-02