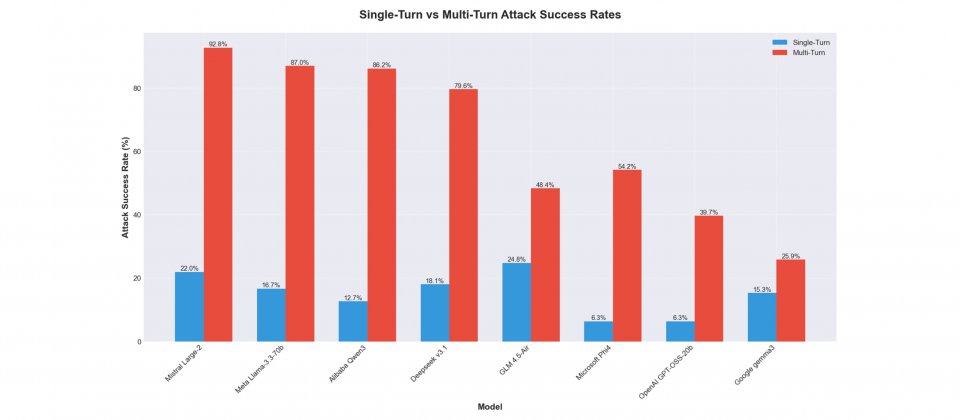
Cisco AI Defense研究人員指出,多輪提示攻擊(Multi-Turn Attack)正成為開源權重模型的主要弱點。在這份針對8款開源權重大型語言模型的黑箱(Black Box)測試中,研究團隊發現模型在多輪對話中更容易被誘導產生違規輸出,攻擊成功率最高達92.78%,最低也有25.86%,整體約為單輪攻擊的2到10倍。
研究以AI Validation平臺進行自動化測試,涵蓋阿里巴巴的Qwen3-32B、Meta的Llama 3.3-70B-Instruct、Mistral Large-2、DeepSeek v3.1、Google的Gemma-3-1B-IT、微軟Phi-4、OpenAI的GPT-OSS-20b,以及智譜AI的GLM-4.5-Air等模型。測試過程完全採黑箱方式,研究人員未事先掌握模型內部架構或防護機制,並依據MITRE ATLAS與OWASP的AI安全分類來判定模型的防禦能力。
結果顯示,幾乎所有模型在多輪對話中都出現防護瓦解現象,以Mistral Large-2為例,多輪攻擊成功率達92.78%,而Google Gemma-3-1B-IT則相對穩定,僅25.86%。這些結果凸顯模型的安全缺口在於單輪與多輪防護之間的落差,以Qwen3-32B為例,差距高達73.48%,代表模型在長對話情境下防禦能力明顯下降。
研究人員指出,攻擊者往往透過語境誤導、漸進升高、資訊拆解重組、角色扮演、拒絕改述或轉向等策略,逐步削弱模型的安全約束。尤其資訊拆解重組與語境誤導最具威脅,能讓模型在不自覺間產生違規或敏感內容。而這些攻擊方式可能在企業應用造成實際風險,例如客服系統被誘導洩露資料,或決策輔助工具輸出不當建議,影響業務運作。
Cisco分析指出,模型的訓練導向與對齊策略,是影響安全缺口的主因之一。強調能力與開放性的模型,如Mistral與Meta Llama系列,往往在多輪測試中出現較大落差,而重視安全對齊與輸出穩定性的模型,如Google Gemma與OpenAI GPT-OSS-20b,雖整體能力略保守,但能更一致地維持防護。這也說明開源權重的自由度雖促進創新,卻同時放大了安全風險。
研究人員建議在部署前進行完整安全稽核,並將多輪對話測試納入評估標準,同時搭配對抗式訓練、上下文感知防護、即時監測與紅隊演練,降低越獄攻擊風險。報告最後指出,開源權重仍是推動人工智慧生態的重要基礎,但要是缺乏相應的安全工程與治理機制,多輪提示攻擊將持續是開源模型的最大隱憂。
熱門新聞

2025-06-02

2026-03-13

2026-03-14

2026-03-13

2026-03-13

2026-03-13

2025-04-15
2026-03-16