短短幾年,大型語言模型(Large Language Model,LLM)技術不斷突破,能處理的內容,可輸出的對話複雜度與篇幅,都有大幅增長,能一次輸入與處理數百、上千頁篇幅、包含複雜內容的資料,並生成長達數萬、數十萬字的對話。
但LLM能力的進展,是以消耗硬體資源為代價,運算參數越多,處理的文字量越大,消耗的GPU運算能力與記憶體空間也越大。
隨著LLM能力急速進步,這兩年開始出現硬體資源擴展速度,追不上LLM能力增長的情況,特別是記憶體容量。LLM的記憶體需求正以10倍、100倍的幅度不斷暴漲,但GPU供給的記憶體容量,僅以每世代最多提高50%的程度增加,促使需求與供給之間的落差不斷擴大,以致在LLM應用形成「記憶體容量瓶頸」。
當GPU記憶體空間不足時,GPU將被迫等待資料從緩慢的外部儲存裝置載入,或被迫重新計算無法保存在記憶體中的資料,不僅導致LLM運作遲緩,甚至停頓,也造成GPU運算能力與維運成本的浪費。
這樣的情況,也促成以打破記憶體容量瓶頸為目的的一系列新技術,以及新解決方案誕生。
我們在6月底的封面故事《AI硬體架構新變革:KV快取產品崛起》,先從KV快取的角度,檢視LLM的記憶體瓶頸問題,以及相關解決方案的發展。
不過,KV快取只涉及LLM應用中的推論部分,還不是LLM記憶體瓶頸問題的全貌,這次我們將從更完整的LLM記憶體應用需求出發,檢視相關產品技術現況,涵蓋LLM架構與規格演進,以及各式各樣的LLM記憶體擴充解決方案。
影響LLM記憶體需求的因素
在訓練與推論階段,影響LLM記憶體占用容量的因素有所不同。
在訓練階段,影響記憶體需求的主要因素包括:模型權重(Weights)、梯度(Gradients)、追蹤與保存計算過程狀態的啟動反應表徵(Activations),優化器狀態(Optimizer States)等。在推論階段,影響記憶體需求的因素,則有模型權重,以及KV快取等。
其中最基本的影響因素是模型權重,也就是模型的參數數量與其精度,其他因素如梯度與優化器狀態的記憶體占用量,都與模型參數的數量、精度直接相關,模型參數數量越多,使用的計算精度越高,占用記憶體容量也成比例增加。
而占用記憶體容量最大宗的來源,則是訓練階段的Activations,以及推論階段的KV快取這兩項因素。其中Activations的記憶體占用量與自注意力機制(Self-Attention),以及資料內容長度等相關,特別是內容長度的記憶體占用量,呈現平方增長規模(訓練32K長度內容所需記憶體容量,是訓練4K長度內容的64倍);而且,AI推理階段對KV快取記憶體的需求量,直接取決於模型的輸入與輸出內容長度。總的來說,兩者都與輸入與輸出Token數量呈正比關係,也就是LLM的上下文區間(Context Window)的大小,越大的上下文區間,可保存越多的輸入與輸出內容,但需要的記憶體空間也越大。
所以,我們透過觀察LLM參數總數,以及支援的上下文區間大小演變,就能看出LLM的記憶體需求增長趨勢。
急速膨脹的LLM記憶體需求
以OpenAI的GPT模型為例,在參數數量方面,2018年問世的GPT-1僅1.17億個參數,2019年的GPT-2就增加到15億個參數,增加超過12倍,2020年的GPT-3又一舉增加到1,750億個參數,較最早版本增加1,500倍,2022年的GPT-3.5也是1,750億個參數,此後OpenAI不再公開後續GPT版本的參數數量,不過外界估計2023年推出的GPT-4,約含有17,600億個參數,2025年發表的GPT-4.5則估計有40,000億到50,000億個參數,從這個數字來看,GPT模型參數數量,在8年內增加了3萬倍以上。如果只看2020年GPT-3以後情況,則到GPT-4.5為止的總參數量,也增加20到30倍。
在上下文區間方面,為了生成篇幅更長、複雜且更精確的對話內容,上下文區間的大幅提高是所有LLM共通趨勢。
例如,GPT-1只支援512個Token,接下來幾個版本都以倍數增加,GPT-2為1,024個Token,GPT-3為2,048個Token,GPT-3.5為4,096個Token;到了GPT-4一舉提高到32,768個Token,GPT-4 Turbo又增加到128,000個Token,250倍於最初的GPT-1,接下來GPT-4o與GPT-4.5都維持在128,000個Token。接著OpenAI為了因應其他LLM競爭,在2025年4月發表的GPT-4.1上,將支援的上下文區間提高到100萬個Token,相較於最早的GPT-1,提高至將近2,000倍,從GPT-3起算,也提高將近500倍。
我們再以開源的Meta Llama模型作為對照,相對於GPT,Llama一開始是以較少參數量,但仍能達到足夠效能為訴求,2023年初發表的最早版本Llama擁有652億個參數,只相當於GPT-3.5的1/3,比起同時期問世的GPT-4,參數數量更相差30倍。後來2023年中與2024年初推出的Llama 2與Llama 3,參數量也維持在700億個上下,不過2024年中推出的Llama 3.1,最大參數量增加到4,050億個,較最初版本提高6倍,2025年4月發布的Llama 4,目前最大參數量也維持在4,000億個(Maverick版),但另有1個擁有20,000億個參數的版本(Behemoth版)還未正式推出,相較於最初的Llama提高超過30倍,參數量已達OpenAI同時期推出GPT-4.5的同一層次。
在上下文區間方面,最初的Llama支援2,048個Token,只相當於早了3年推出的GPT-3,不過Meta追趕腳步很快,接下來Llama 2與Llama 3支援的上下文區間,依序成倍增加到4,096個與8,192個,然後Llama 3.1一舉提高到128,000個Token,追上同時期GPT-4o、GPT-4.5的水準。
緊接著Meta更在最新的Llama 4上,將上下文區間大幅提高到100萬個Token(Maverick版),以及1,000萬個Token(Scout版),分別較最初的Llama增加將近500倍與5,000倍,為當前LLM的最高規格。
總的來說,就算不計入2020年以前的早期版本LLM,只看2020年以後問世的較新版本LLM,在過去5年內,LLM的參數數量已從數百億到1千多億個,增加到數萬億個,幅度增長30倍以上。
這意味著:在其他條件不變的前提下,光是載入模型本身,需要的記憶體空間也跟著增加30倍以上;而LLM所能支援的上下文區間大小,也從2,048個Token提高到100萬個Token,最大還能達到1,000萬個Token,增長500倍到數千倍。也就是說,為了應付越來越長的上下文區間,訓練與推論過程中的記憶體耗用量,也將隨著膨脹數百倍至數千倍以上。
所以,要運行當前最新世代LLM,運算系統需要的記憶體容量,較4、5年前的LLM至少增加數十到數百倍以上。
MOE架構的記憶體需求
一些較晚推出的LLM,為了在擴大模型規模的同時,抑制運算資源的膨脹,而採用混合專家模型架構(Mixture of Expert model,MOE)。MOE架構LLM是由多個較小型專家單元(Expert)組成,對每個Token的計算只需啟用一部分專家單元與活躍(active)參數來進行,從而可大幅節省運算資源、時間與成本。
例如OpenAI在2023年推出的GPT-4,據稱就採用8 x 220B或16 x 110B的MOE架構,由8個220B規模(2,200億個參數),或16個110B規模(1,100億個參數)的專家單元組成,總參數量達到17,600億個,十倍於上一代GPT-3.5,但GPT-4並不同時啟用所有參數,據稱一次只需啟用2,800億個活躍參數,顯著減少了運算量。
類似的,Meta今年上半年發表的Llama 4也改用MOE架構,由16個或128個專家單元組成,雖然總參數量達到1,090億(Scout版)、4,000億個(Maverick版)與20,000億個(Behemoth版),但實際啟用參與運算的活躍參數僅170億個與2,880億個。
問題在於,MOE架構確實能顯著減少運算量,卻不能節省記憶體占用。MOE架構是透過路由器元件(router)來檢視輸入內容token,然後選擇交由合適的專家單元處理,每1個輸入token可能分別交由不同專家單元處理,而會選擇哪一個專家單元是無法預先確定的。所以,若非一開始就將所有專家單元的參數全部載入記憶體,一旦路由器選用到未將參數載入記憶體的專家單元,此時,就必須等待緩慢的底層儲存裝置載入參數,導致運作緩慢、反應遲鈍。
所以,為了確保訓練與推理作業的順暢,MOE架構LLM還是必須將全部參數載入記憶體,而不能只載入活躍參數,相較於既有的密集型(dense model)LLM,並沒有節省多少記憶體空間。
GPU的記憶體容量增長
看完需求端方面,也就是LLM記憶體需求增長狀況後,接下來我們檢視供給端方面,也就是GPU配置的記憶體容量增長情況。
以Nvidia的HGX資料中心級GPU為基準,過去7、8年來,每一代新產品大致都能提供較上一代多出30到50%的HBM記憶體容量,2017年推出的V100配置最大32GB的HBM2記憶體,2020年的A100則擁有80GB的HBM2e,2022年發表的H100最初也是配置80GB HBM2e(後來有升級到94GB HBM3的版本),2023年的H200增加到141GB HBM3e,2024年初與2025年初發表的B200(Blackwell)與B300(Blackwell Ultra),則分別配置192GB與288GB的HBM3e記憶體,除了A100到H100之間,記憶體容量增長有所停滯,其餘產品都維持近50%的記憶體容量增長,在8年內一共提升了9倍。
作為對照,我們再來看AMD Instinct系列GPU記憶體配置情況,從2020年底推出,擁有32GB HBM2記憶體的MI100起算,2021年底發表的MI200系列增加到128GB HBM2e,2023年底推出的MI300系列,又增加到192GB HBMe3。2024年底AMD推出MI325X,記憶體容量提升到256GB HBMe3。不久前於2025年6月發表的MI350,記憶體容量則進一步升級到288GB HBM3e,與Nvidia的B300同等。
總計過去5年來,AMD Instinct系列的記憶體配置容量也增長9倍,超過Nvidia同時期的GPU記憶體增長幅度——單論2020到2025年,Nvidia從H100到B300的GPU記憶體容量,其實僅提高3.6倍。
緊迫的GPU記憶體不足問題
無論是8年內提高9倍,或是5年內提高9倍,單從數字上來看,GPU記憶體容量都有相當可觀的增長,但問題在於,同一時期,LLM的記憶體需求卻是以數十倍、數百倍的幅度提高,顯然GPU的記憶體供給增長幅度,遠遠落後於LLM的記憶體需求。
LLM不僅需耗用大量運算力,同時也是記憶體密集型應用。事實上,在LLM訓練與推論過程中,要有效發揮GPU運算能力,不可或缺的前提,是GPU能即時地從記憶體饋入運算資料,也就是說,記憶體必須要有充足空間載入運算所需資料,並以足夠高的頻寬持續將資料饋入GPU,才能維持GPU的利用率,避免閒置。
所以,足夠的GPU記憶體容量與傳輸頻寬,是LLM應用的必要條件。
而隨著LLM複雜度與規模的急速膨脹,即便是較小規模版本的LLM,記憶體容量需求也相當可觀。
舉例來說,訓練一個80億參數量(8B)的小規模LLM模型,在FP16精度下,載入參數需要16 GB記憶體,即便消費型GPU的記憶體容量也足以承載,但加上參數梯度後,記憶體占用就會加倍,如果再加上Activations與自注意力機制等需求,總記憶體需求量會膨脹到上百至數百GB,甚至TB等級,即便高階的資料中心型GPU,也無法獨力承載這樣大的記憶體需求。
如果換成中、大規模模型,耗用的記憶體容量,將比前述數字高出10倍、數十倍。對於175B規模的GPT-3,或405B規模的Llama 3.1模型,在FP16精度下,光是載入參數就要占用350GB與800GB記憶體,加上訓練過程中的其他記憶體開銷,將會耗用數以TB計的記憶體。
而對於推論作業來說,GPU記憶體除了必須載入模型參數,由於當前LLM支援的上下文區間都達到128K個Token以上,KV快取的記憶體需求會隨著輸入、輸出內容長度增加而迅速膨脹,甚至會占用比模型參數本身高出數倍的記憶體空間。即便是中、小規模的LLM,當設定的輸入、輸出內容長度較長,或同時處理的資料批次較大時,推論時需要的KV快取記憶體往往也會達到數百GB等級或更多。
當GPU的記憶體空間不足時,將連帶造成LLM運作效率大幅下降,甚至停擺。GPU須時常等待資料從緩慢的外部儲存裝置載入到記憶體,導致GPU閒置,以及LLM運作遲緩;若記憶體容量不足以充分保存訓練與推論過程中的資料(如運算過程狀態或KV快取等),當後續需要這些資料時,GPU必須重新計算這些資料,造成大量GPU時間耗費在重新計算上。
「開源節流」克服LLM記憶體瓶頸
要克服LLM龐大的記憶體需求,以及GPU有限的記憶體供應量之間落差,方法不外乎「節流」與「開源」。
所謂「節流」,就是設法減少LLM訓練與推論過程中的記憶體耗用。而「開源」則是增加記憶體供給量。
節省記憶體消耗
過去數年來,開發商與研究人員已發展一系列技術,來節約LLM訓練與推論過程中占用的記憶體。
例如:在訓練階段可採取Activation重新計算(Recomputation),放棄保存部分運算過程狀態,以重新計算來換取節省記憶體占用。針對KV快取,常用作法則有:將高精度浮點數轉換為低精度,以損失精度換取節省記憶體的量化技術(Quantization),或在維持一定精度下,只保存部分KV快取值的稀疏技術(Sparsification);還有允許輸入內容不斷增加,而仍確保KV快取不致溢出GPU記憶體容量的滑動窗口技術等。
改進自注意力機制,也是節約KV快取記憶體占用的一大重點方向,例如:藉由共用KV快取、節省記憶體占用的多查詢注意力(Multi Query Attention,MQA)與分組查詢注意力(Grouped Query Attention,GQA),可以在非連續的記憶體空間,保存KV快取資料,減少記憶體浪費的分頁式PagedAttention技術,以及能夠壓縮注意力輸入、只儲存潛在向量,藉此大幅減少KV快取的多頭潛在注意力機制(Multi-head Latent Attention,MLA)等。
前述技術能在訓練與推論過程中的不同環節,節約數十百分比到數倍的記憶體消耗,但本質上其實是不同面向的折衷與妥協,是以精度、運算時間、模型能力等方面為代價,來換取節省記憶體,並非適用所有應用方式,必須視情況取捨。
另一方面,各式記憶體節約技術的成效,又會被LLM持續進化所帶來的記憶體需求增長所抵銷。為追求更完善的資訊處理與生成能力,LLM的規模依舊持續擴大,新一代LLM還藉由引進多模式學習技術(Multimodal learning),已不限於處理文字訊息,而能處理文字、圖像、語音等多元資料內容,也帶來不斷膨脹的記憶體需求。
因此,僅僅依靠軟體或運算架構來節約記憶體耗用的「節流」手段,已不足以面對記憶體需求不斷成長的壓力,必須搭配擴展記憶體資源的積極「開源」手段。
增加記憶體資源
既然單一GPU的記憶體,不足以承載LLM的訓練與推論工作,那麼最最簡單、粗暴的解決辦法,就是使用更多GPU組成叢集,藉此匯聚更大的記憶體空間。
多GPU叢集是AI與LLM應用的標準硬體架構,當前GPU伺服器主流配置是8路組態,8組GPU之間透過NVLink或Infinity Fabric之類專屬高速介面相互直連。以當前資料中心級GPU規格來說,1臺8路GPU伺服器可匯聚1到2 TB的HBM記憶體,足以載入大規模LLM的數千億個參數,考慮到訓練與推論過程中的其他記憶體開銷,這樣的記憶體規格可能還是不敷所需,可再加入第2臺、第3臺,或更多GPU伺服器,進一步擴展LLM可用的HBM記憶體容量。
顯而易見的,這種作法存在兩大副作用,一是缺乏成本效益,二是未精準對應實際需求。
當瓶頸發生在「記憶體容量不足」,而非「GPU運算能力不足」時,引進更多GPU,確實能獲得更多HBM記憶體,但考慮到GPU昂貴的成本,這是非常沒有成本效益的記憶體瓶頸解決手段,形成浪費。
兩種解決手段
只依靠LLM軟體架構與演算法改進手段,所得到的節約記憶體效果,不足以應付持續增長中的記憶體需求;但透過增加GPU數量,為LLM提供更多HBM記憶體資源,又欠缺成本效益。
所以,更合理的手段,是為LLM尋求與GPU「脫鉤」的記憶體資源擴展方式,不需為了增加記憶體而引進1整組GPU,而可單獨、靈活地擴展記憶體。
這也是當前大多數LLM記憶體擴展解決方案的發展方向——從GPU外部,提供可獨立擴展更大規模的記憶體空間,藉此將原本完全由GPU記憶體承擔的工作負載,卸載到GPU以外的記憶體裝置上,如CPU DRAM,或透過網路介接的NVMe快閃儲存設備,代價是這些裝置的傳輸頻寬,明顯不如與GPU直接整合的HBM,算是以較低頻寬,換取不被GPU綑綁的記憶體擴展能力。
另一些廠商則重視傳輸頻寬更甚於擴展能力,沿用HBM與GPU的晶片整合架構,但改用儲存密度高出數倍的NAND快閃記憶體,來取代基於DRAM的HBM,這便是目前發展中高頻寬快閃記憶體(High Bandwidth Flash,HBF),擁有相當於HBM的高傳輸頻寬,但容量高出HBM十多倍,同樣能為LLM提供更大記憶體空間,但不具備與GPU脫鉤的擴展靈活性。
基於外部記憶體裝置的擴展方案,以及直接與GPU整合的高頻寬快閃記憶體(HBF),構成當前LLM記憶體擴展解決方案的兩大類型。
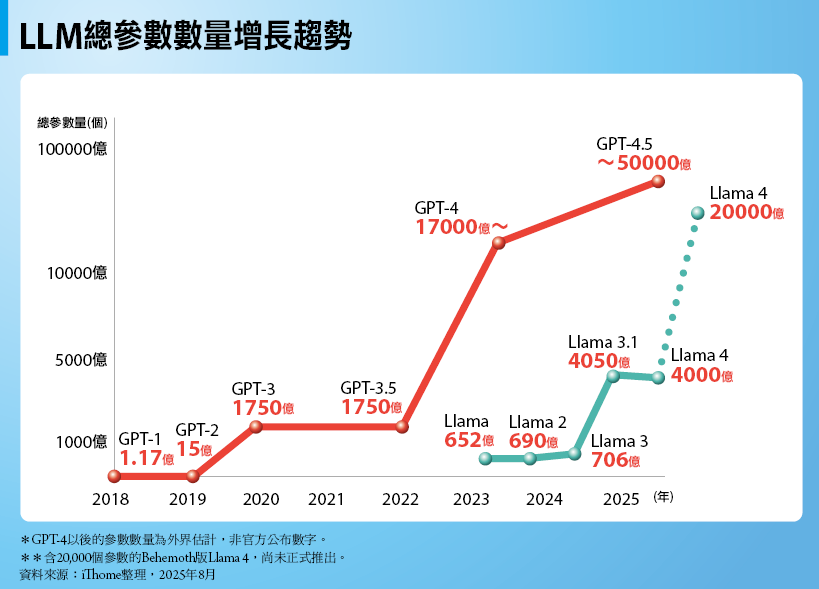
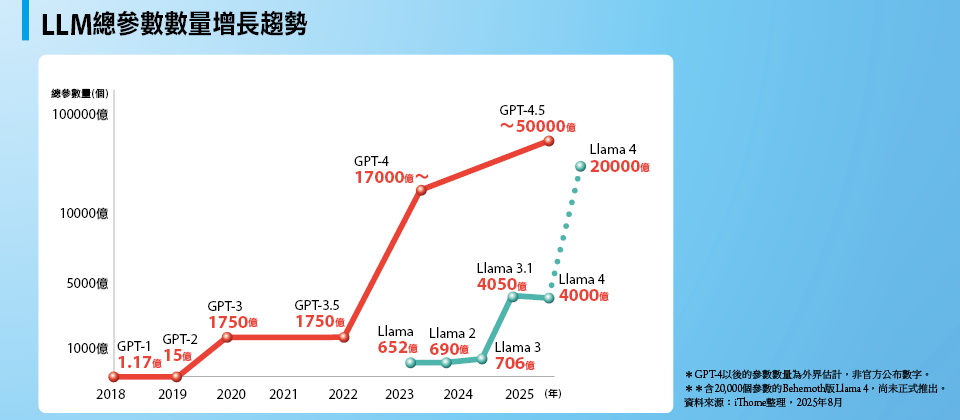
LLM總參數數量增長趨勢
自LLM問世以來,模型總參數量便以指數爆發性增長,連帶導致記憶體需求量暴漲。
以最具代表性的OpenAI GPT為例,自2018年推出的GPT-1起,到2025年初發表的GPT-4.5,模型包含的參數量在8年內增加3萬倍以上。如果只看2020年以後,從GPT-3到GPT-4.5的總參數量也增加20到30倍。對照開源LLM最具代表性的Meta Llama,總參數數量也在兩年半內增加30倍。
當LLM的總參數量增加30倍,意味著要以相同精度將參數載入記憶體,需要的記憶體空間也將增加30倍。連帶的,訓練與推論過程中其他需求耗用的記憶體量,也會成比例增加。*GPT-4以後的參數數量為外界估計,非官方公布數字。 **含20,000個參數的Behemoth版Llama 4,尚未正式推出。 資料來源:iThome整理,2025年8月
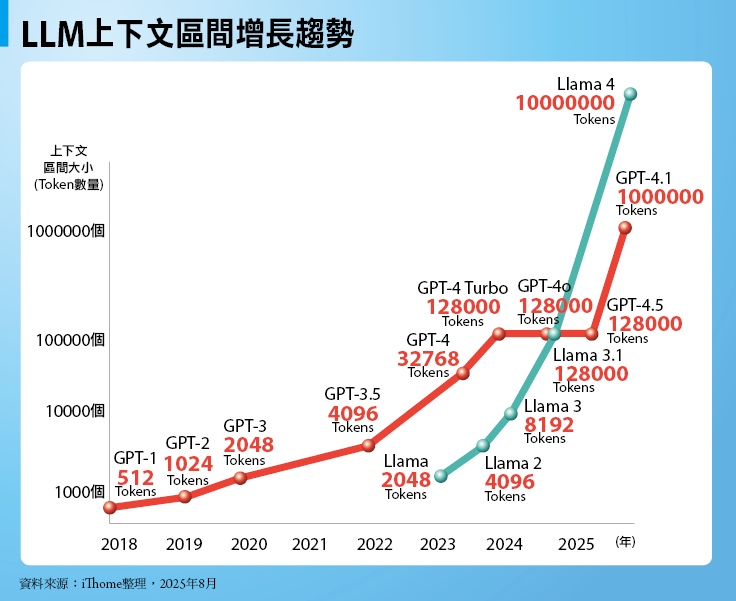
LLM上下文區間增長趨勢
越大的上下文區間(Context Window),可讓LLM容納更多輸入與輸出內容,保存更多計算資料,顯著提高處理與生成長篇幅內容的能力,但連帶也需消耗更多記憶體空間。
以Open AI的GPT為例,自最早的GPT-1,到今年初發表的GPT-4.1,支援的上下文區間從512個Token提高到100萬個Token,提高將近2,000倍,從GPT-3起算,也提高將近500倍。而開源領域的Meta Llama,更從Llama的2,048個Token提高到Llama 4的1,000萬個Token,增長近5,000倍。
隨著上下文區間大幅提高,耗用的記憶體空間也將以成百、上千倍的比例大幅增加。資料來源:iThome整理,2025年8月
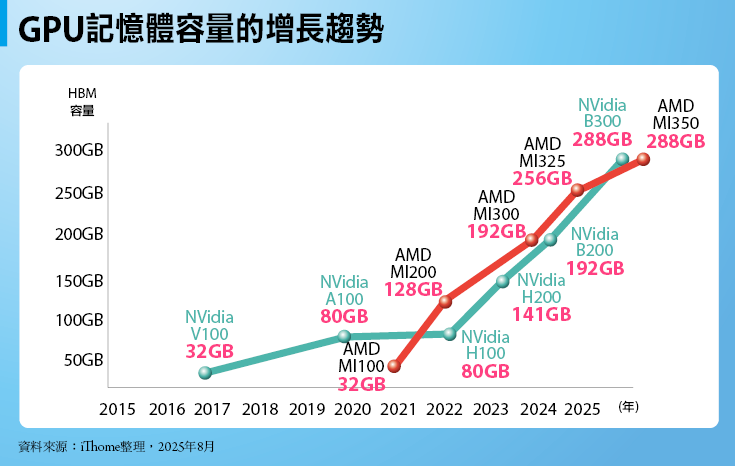
GPU記憶體容量的增長趨勢
過去7、8年來,資料中心級GPU的HBM記憶體容量,大致以每一世代提升30%到50%的幅度增長,以Nvidia HGX系列GPU為例,從V100到B300的記憶體容量足足提高9倍,對照AMD的Instinct系列GPU,從MI100到最新的MI350,在5年內也提高9倍,都稱得上相當顯著的增長。
問題在於,同一時期內,LLM的記憶體需求是以數十倍、數百倍幅度暴漲,遠超過GPU記憶體容量提升幅度,需求與供給之間出現巨大的落差,形成LLM應用中的記憶體容量瓶頸。資料來源:iThome整理,2025年8月

熱門新聞

2026-02-06
")
2026-02-09
")

2026-02-06

2026-02-06


2026-02-06

2026-02-06