Hitachi Data System(HDS)在日前針對亞太區媒體舉辦的大資料發表會上,分別找來集團母公司Hitachi的亞洲研發中心總經理Naoto Matsunami,介紹Hitachi研發的大資料產業應用,以及為澳洲多所大學提供大資料研究平臺的Intersect公司,說明該公司以HDS的儲存技術打造大學的大資料研究運算平臺。
這樣的組合就說明了HDS進軍大資料市場的兩大策略──提供大資料的資料儲存平臺,並且結合Hitachi的資源,提供垂直產業的大資料解決方案。
大資料專業技能不足的問題
HDS亞太區技術長Andrian De Luca表示,一旦企業將大資料運用在產業應用上,就會面臨許多不同平臺、裝置與軟體系統的整合需求。但是根據HDS所掌握的資料,未來中短期內大資料面臨最大的問題是專業技能不足,不只缺乏擅於資料分析的資料科學家,在系統整合上亦需要專業的技能。
Andrian De Luca指出,HDS的大資料策略就是與母公司合作,結合Hitachi橫跨工程、交通、電信等多種產業的研發與產業知識,提供產業需要的大資料垂直整合方案,而不只是提供儲存產品而已。
他表示,HDS與Hitachi的內部合作,可以更快完成系統整合,加快推出大資料解決方案。例如Hitachi的工程車、挖土機等建築機具,透過分析這些機具的使用習性,有助於建築業者改善設備的調度管理與資產利用。
然而,HDS採此一方式能夠提供的解決方案類型勢必有限,因此HDS仍會與專精於不同產業應用的系統整合商合作,共同開發垂直產業的大資料解決方案。
在資料儲存技術的發展方面,Andrian De Luca表示,HDS近幾年的技術發展主要是因應三大挑戰,包括資料快速增長、資料庫分析效能,以及Hadoop。
有了這些基礎後,目前HDS的技術發展重心放在機器資料、即時分析,以及利用中介資料(Metadata)的內容分析。未來的技術研發趨勢則是圖像、視訊、音訊等多媒體資料分析,以及更加複雜的多元資料分析。大資料的垂直產業應用
Hitachi針對視訊檢索開發的深度搜尋技術,可自動辨識視訊影片中的人物與物件,自動建立索引。傳統依賴人工建立索引的作法,需耗時等同視訊長度3倍的時間,自動檢索則更有效率。
負責掌管Hitachi亞洲研發中心的Naoto Matsunami,則展示幾項Hitachi研發的大資料應用,包括交通流量管理、人臉辨識應用、城市漏水管理、視訊內容深度搜尋等技術。
其中的人臉辨識應用,Hitachi的技術已經可以做到1秒鐘辨識3千6百萬個臉孔,並且允許像素只有60×60的低解析度圖片。這項技術能夠快速搜尋監視器的畫面,在預防犯罪的應用上,有助於迅速找出可疑的人物。
在交通管理的運用上,其中一項是越南河內市已經採用的技術,是透過汽車與機車駕駛人的手機,分析汽車與機車的交通流量行為,再結合地圖以視覺化的流量圖呈現,提供城市當局調整交通政策。
另一項交通管理的應用,則是為了解決通勤時間交通擁塞的問題。隨著城市人口增加,改善通勤交通成為每個城市的大問題,Hitachi利用大資料分析技術所提出的解決方法,關鍵在於控制通勤者的行為。
這套系統的核心是交通流量模擬,它可以依據捷運、公車、火車等大眾運輸工具的客流量,即時模擬交通流量的可能狀況,並且建議通勤者最佳路線。同時,通勤者使用行動裝置獲得路線建議時,這套系統也透過行動裝置掌握通勤者的實際動線,再將這些資料回饋至系統,做為流量控管的調整依據。
當交通管理者可以獲取各方的即時動態,就能立即調整交通政策。例如某一路段發生車禍,該系統的路網地圖就會立即呈現事件通報,並且自動模擬誤點時間及受影響人數等。管理者就能立刻調整流量,如修改對通勤者的路線建議,避開受影響的路段,或予以交通分流,降低交通事故所造成的影響。
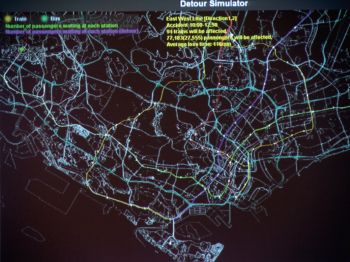
Hitachi運用大資料技術研發的交通流量管理系統,可以模擬大眾運輸工具(火車、捷運與公車)的流量狀況,提供給通勤者最佳路線。透過控制通勤者的流動,可有效疏解大眾運輸系統擁塞的問題。

Hitachi這套交通流量管理系統可依據交通事故立即模擬可能的影響,例如車禍可能造成的班次誤點以及受困在車站的人數等。據此可動態調派或調整通勤者的最佳路線,以降低交通問題對通勤流量的影響。澳洲大學的大資料研究平臺
 Intersect執行長Ian Gibson表示,過去在癌症、基因與量子物理等方面的研究,已經帶來巨量資料處理與分析的挑戰。接下來大資料更將掀起科學研究方法的典範轉移。 |
Intersect執行長Ian Gibson則指出科學研究所面臨的大資料挑戰,該公司提供澳洲南威爾斯11所大學研究需要的運算環境。他表示,過去在癌症、基因與量子物理等方面的研究,已經帶來巨量資料處理與分析的挑戰。
然而,接下來有更多的學術研究都會需要大資料技術,大資料將掀起科學研究方法的典範轉移。例如以水力壓裂法(Hydraulic Fracturing)開採頁岩氣,可以深入頁岩層開採天然氣與石油,但需要對環境有更多的監控,才不至於釀成大災難,而這就需要仰賴大量感測器的即時分析。
在探索宇宙時,則要從絕大多數是雜訊的資料中,找出真正有價值的微弱訊號;或如澳洲國家成立的精神分裂症研究計畫,涉及的是原因複雜的症狀,必須綜合分析核磁共振攝影、基因、臨床診斷與環境因素等種種資料,才能找到精神分裂症的起因。
Ian Gibson表示,澳洲政府撥了4百萬澳幣贊助大學的大資料研究計畫,為了提供11所大學的大資料研究需求,他們設計一個多層次資料運算架構。運算平臺是HPC(High Performance Computer)叢集,以及利用開源OpenStack打造的私有雲平臺,透過4條10Gb網路與大學連線。
資料儲存的第一層是具有橫向擴充能力的HDS HNAS叢集,採用高速的10K SAS硬碟,可以快速因應資料儲存需求,目前的總容量已使用800TB。
資料儲存的第二層則是HCP 500物件儲存(Object Storage)平臺,有需要保留下來的資料將會移到此第二層。
Intersect工程師表示,物件儲存架構確保這些資料在未來10年都可以很方便取出使用,也有助於未來用於大資料分析。資料儲存的第三層則是磁帶系統。文⊙吳其勳
熱門新聞

2026-02-06
")
2026-02-09
")

2026-02-06

2026-02-06
")
2026-02-09

2026-02-06

2026-02-06