
資料來源:iThome整理,2025年12月
歷經大約1年的規格制定工作後,由多家晶片、網通與雲端服務大廠組成的UALink聯盟,於2025年4月發表UALink(Ultra Accelerator Link)1.0版規範,讓這項討論已久的開放式加速器晶片互連I/O架構,終於正式問世。
UALink聯盟成立於去年5月,成員包括AMD與Intel兩大晶片廠商,加上Broadcom、Cisco兩大網通廠商,還有Google、HPE、Meta與微軟等雲端大廠,阿里雲、蘋果與Synopsys也於2025年1月加入,理事會加上貢獻者成員超過65家(但Broadcom已退出UALink理事會,降為一般貢獻者成員)。聯盟的宗旨是建立一個開放的GPU加速器互連I/O規範,為AI伺服器與叢集中的加速器,提供高速、低延遲的I/O連結架構,以對抗Nvidia的NVLink技術。
Nvidia當前在GPU加速器市場上的「霸業」,不僅是建立在GPU本身,還包括完整的周邊應用架構,NVLink便是維繫Nvidia「霸業」的「護城河」之一,Nvidia可以透過這套專屬的高速I/O架構,讓大量GPU彼此互連,建構出超大規模、超高密度的GPU運算環境。
單論個別GPU的運算效能規格,AMD與Intel的GPU往往不亞於Nvidia,部分特性甚至猶有過之,然而,現實環境大多需要多GPU協同運作,此時就會暴露出AMD與Intel各自的GPU互連I/O架構(如AMD的Infinity Fabric,與Intel的Xe Link),連結能力與頻寬不如NVLink的問題,尤其是在跨GPU伺服器節點的情況下,連結的GPU數量越多,差距也越顯著。
而UALink便是「非Nvidia陣營」抗衡NVLink的解決方案。UALink最吸引人之處,是在Nvidia獨家專屬的NVLink技術之外,提供一套替代的開放式GPU互連I/O架構方案,還有多供應商參與帶來的通用性與成本效益。
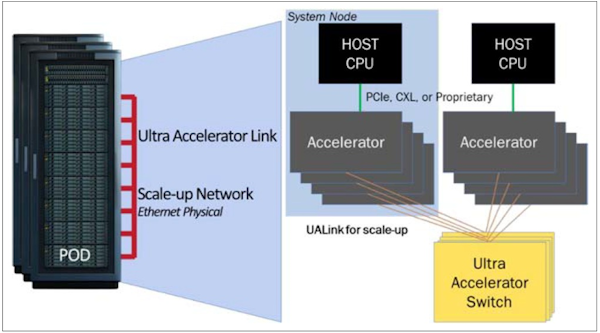
UALink基本架構
UALink可為GPU伺服器提供近距離的GPU直連傳輸通道,透過UALink交換器的介接,允許最多1,024個GPU加速器彼此互連,構成一個縱向擴展(Scale-Up)Pod單元。圖片來源/UALink Consortium
與NVLink的規格對比
目前發布的UALink 1.0版規範,是基於乙太網路實體層的200G規格,可提供每通道100 Gb/s或200 Gb/s的傳輸速率,考慮到編碼與糾錯的損耗,實際信號速率為212.5 GT/s,可以1、2、4條通道組成1個鏈結(Link),在4通道下可提供800 Gb/s的資料傳輸頻寬(也就是100 GB/s,雙向為200 GB/s)。而透過UALink交換器(UALink Switch,ULS)的介接,可讓最多1,024個GPU加速器互連,組成1個縱向擴展(Scale-Up)的AI Pod單元。
與NVLink相比,UALink 1.0的單一通道傳輸頻寬更高,GPU互連規模更大,但個別GPU所能獲得的總傳輸頻寬,則較為遜色。
NVLink 4.0與5.0的每通道基本傳輸頻寬為100 Gb/s與200 Gb/s(與UALink 1.0相同),但只以2條通道組成1個鏈結(Link),每個傳輸鏈結頻寬為50 GB/s與100 GB/s(雙向),不如UALink的200 GB/s。
但NVLink 4.0與5.0可為每個GPU提供18個鏈結,一共36條傳輸通道,每個GPU能獲得最大900 GB/s與1800 GB/s的總傳輸頻寬(雙向)。相較下,UALink 1.0只能為每個GPU提供800GB/s的總傳輸頻寬(雙向)。
不過,在GPU互連規模方面,則是UALink 1.0佔上風,允許最多1,024個GPU互連。而NVLink搭配NVLink Switch,允許直連的GPU數量為576個。
目前看來,UALink 1.0的能力大致介於NVLink 4.0與NVLink 5.0之間,已有競爭能力,但產品推出時間是一弱點。
預期第一批支援UALink 1.0的產品,要等到2026到2027年間才會推出,AMD與Intel 的GPU加速器,以及Astera Labs、Broadcom的交換器都將支援,但屆時Nvidia很可能也會推出新一代的NVLink 6.0,再次在效能規格上將UALink拋開。

熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
2026-02-09
")
")
2026-02-09
