
英特爾
今年4月初英特爾推出第三代Xeon Scalable系列處理器,沒想到在8月底舉行的英特爾架構日,他們居然打破過去慣例,針對下一代Xeon Scalable系列處理器(研發代號為Sapphire Rapids),提前公開揭露其技術組成架構。
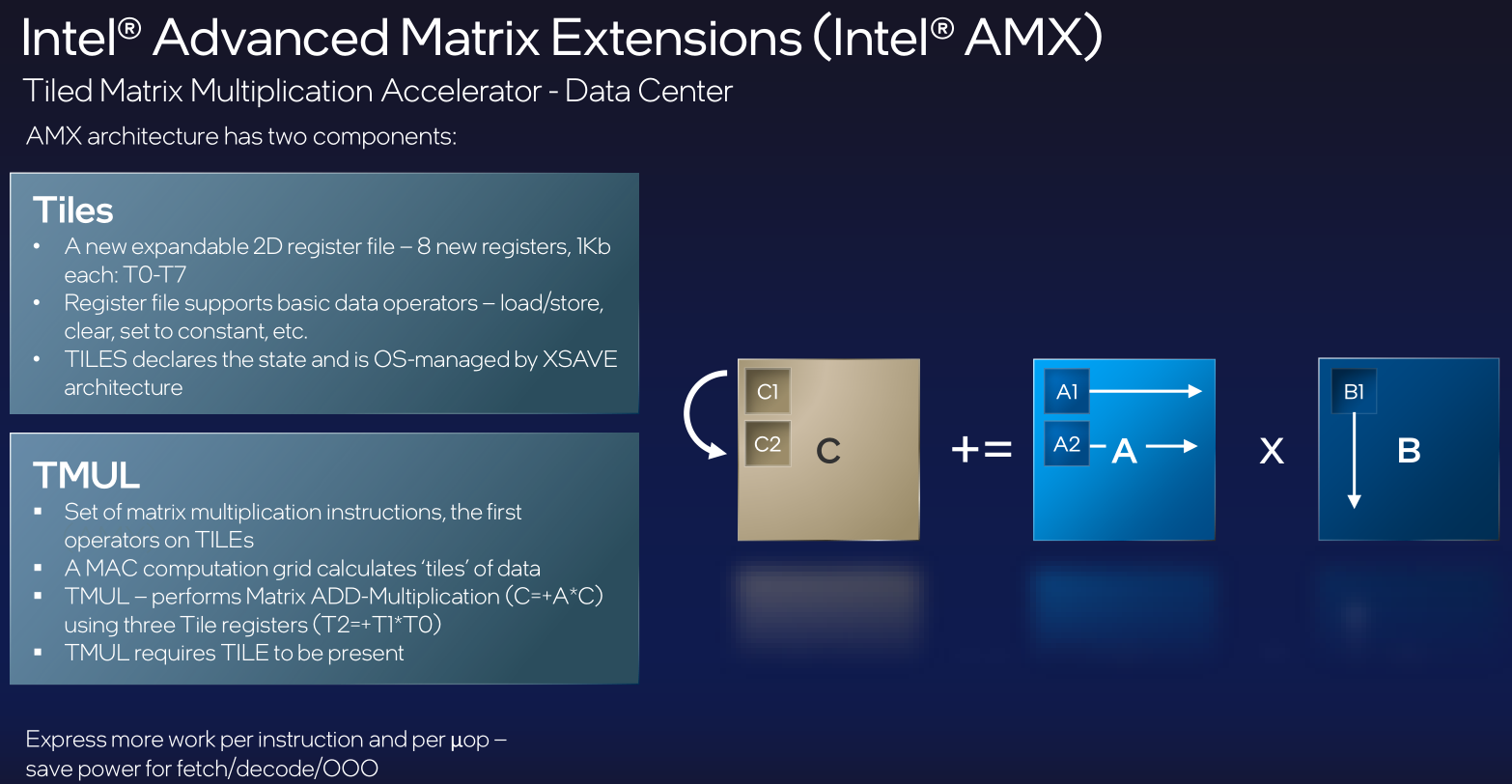
相較於過往的伺服器級處理器,Sapphire Rapids採用了許多首創的設計方式。例如,在封裝的部分,這系列處理器採用新的系統單晶片(SOC)架構,也就是模組化、磚片型(tiled)架構,而能具備足夠的延展性;同時,它們也是首批採用嵌入式多晶片互連橋接技術(EMIB)的產品,而能維持單體(monolithic)的中央處理器介面。
在關鍵技術規格的搭配上,Sapphire Rapids也罕見地區隔出運算、I/O、記憶體,這三大類智慧財產(IP),以建構區塊的形式來呈現特色,令人眼睛為之一亮。此舉讓人聯想到當紅的Arm,他們正是以提供矽智財授權、供用戶搭配設計晶片而在市場迅速崛起,而英特爾在揭露新世代伺服器處理器技術架構,刻意標榜IP組合的舉動,或許別有用意、有互別苗頭的意味。
.png)
Sapphire Rapids的三大技術組成
即將登場的英特爾下一代伺服器處理器Sapphire Rapids,當中實作、結合了許多技術,主要包含了運算、I/O、記憶體等三大類型的技術智財,當中除了英特爾自行研發的製程、封裝、核心微架構、加速器引擎、I/O介面、儲存級記憶體,也有業界最新標準,例如PCIe 5.0、CXL 1.1、DDR5、HBM。圖片來源/英特爾
而單從這些技術組成來看,同樣能發現英特爾對於下一代伺服器處理器,意外採取積極擁抱新規格的態度。例如,他們在毫無預告的狀態下,突然宣布要支援PCIe 5的I/O介面、CXL 1.1互連、DDR5記憶體,以及提供內建HBM記憶體的產品款式。過去英特爾Xeon支援新規格的進度相當遲緩,就連日益普及的PCIe 4.0,也是今年4月推出的第三代Xeon Scalable支援,DDR4-3200記憶體的支援也是如此,相較之下,競爭廠商在前代產品幾次都搶先一步支援新規格,如今態勢改變,英特爾難得採取超前部署的姿態。
因此,Sapphire Rapids如今要搶先一步支援上述新規格,此舉可說是顛覆了過去大家的刻板印象。事實上,英特爾過去通常會耐心等待相關技術與應用成熟,屆時再進場提供支援,也難怪各界會詫異有這樣的改變。
事實上,綜觀現今的伺服器處理器平臺,目前唯有Arm今年4月底主推的Neoverse V1和N2,打著支援PCIe 5介面、CXL 1.1、DDR5記憶體、HBM記憶體(第三代技術HBM2e)的新規格,而英特爾Sapphire Rapids竟不畏被評為「跟進」,而公開宣稱要支援這些特色,這也是過往所難見到的景況,或許真是大家有志一同,都看好這些技術。
採用創新製程與封裝技術,實現模組化系統單晶片架構
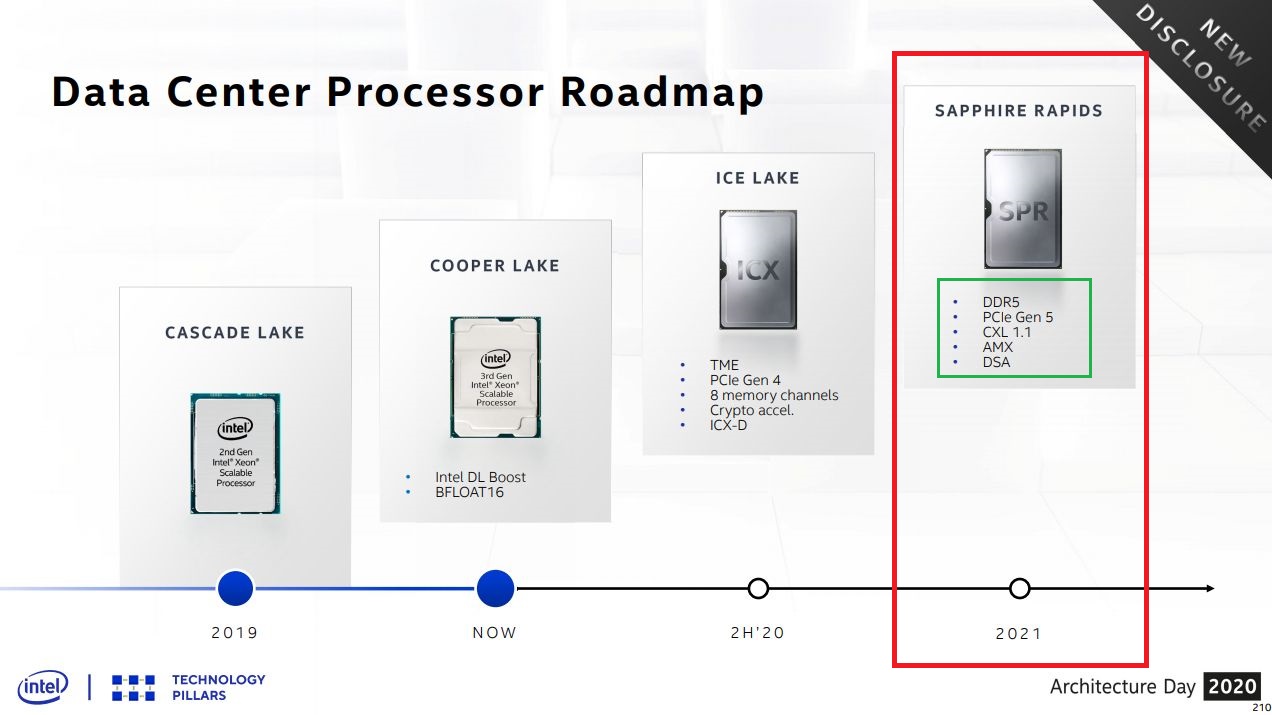
關於第三代Xeon Scalable之後接班的伺服器處理器,在2020年英特爾架構日上,首度正式提及Sapphire Rapids,他們預告這款處理器將採用Enhanced SuperFin製程,並支援DDR5、PCI 5.0、CXL 1.1等先進規格;同時,這款處理器將內建新的加速功能,像是廣泛針對資料搬移應用的資料流加速器(DSA),以及用於深度學習的進階矩陣延伸指令集(AMX);供貨時程上,他們將於2021年下半開始生產出貨。
同年11月,英特爾在美國超級電腦大會期間,再度提及Sapphire Rapids,在採用的製程技術上,以10奈米Enhanced SuperFin稱呼,而對於AMX,則以AI加速指令集DL Boost的次世代技術來比喻。在超級電腦系統的應用案例上,美國洛斯阿拉莫斯國家實驗室發展的Crossroads系統,也宣布將採用Sapphire Rapids處理器。

到了今年,英特爾目前已連續在三場強調公司轉型策略的重大活動當中,提到Sapphire Rapids的最新技術進展。首先是3月舉行的IDM 2.0策略發表會上,該公司新任執行長Pat Gelsinger表示,他們已經開始提供Sapphire Rapids的樣品給特定用戶,希望年底達到生產階段,並在2022年上半「大躍進」,並預告下一代的伺服器處理器代號,會是「Granite Rapids」,屆時將會導入基於Intel 7奈米製程的運算晶磚(Compute Tiles),當中會結合模組化設計方式,以及他們引以為傲的封裝能力。

接著是7月底舉行的Accelerated 2021發表會,公布多項製程與封裝創新消息之餘,也提到新款伺服器處理器進度。
以製程而言,由於英特爾採用了新的命名方式,也使得Xeon Scalable系列處理器的下一代與下下一代產品,也將對應不同的製程名稱,如Sapphire Rapids原本是10奈米Enhanced SuperFin製程,現改名為Intel 7製程。至於再下一代的Granite Rapids處理器,先前採用的製程是Intel 7奈米,改名為Intel 4。


至於封裝,英特爾表示,Sapphire Rapids將是首款採用EMIB封裝的Xeon處理器量產產品,也會是首款使用4個方塊晶片(dual-reticle-sized)的裝置,提供近乎單體(monolithic)設計的效能。(編按:所謂的dual-reticle-sized,直譯是雙光罩尺寸,是指原本單一光罩所能製作的晶片大小限制,用封裝技術黏起來,達成相較於原先2倍的尺寸,而在長、寬都多1倍的狀況下,因此,實際上會是4個方塊)。

若就EMIB規格來看,Sapphire Rapids的凸點間距(bump pitch)是55微米,而在之後推出的伺服器處理器上,這類規格將會縮減至45微米。
英特爾強調,EMIB讓Sapphire Rapids運用嵌入基板的矽晶片互連機制,而不需用到大型矽晶片矽中介層,相較於標準封裝的互連方式,EMIB能提供2倍頻寬密度,以及4倍電力使用效率。
關於Sapphire Rapids的封裝方式,8月底舉行的英特爾架構日期間,負責這項產品的總工程師Nevine Nassif,介紹當中採用的新型模組化、磚片型架構,並解釋其為何能具備更大擴展性、超越實體光罩設計限制的理由,關鍵正是導入了EMIB,它能將多個獨立的晶磚,整合到一個封裝,實現單顆邏輯處理器的設計,藉此提供跡近單體晶粒設計的效能、功耗、密度,同時,還能擴充核心數量、快取容量、記憶體容量,以及I/O。她強調,這樣的設計能針對所有的工作負載,提供平衡的擴充性與一致的效能,對於資料中心規模的伸縮度與資源利用率的最佳化而言,這會是關鍵。




在軟體應用上,此種架構能提供單一、平衡的統合記憶體存取(UMA),可讓每個執行緒完整存取所有晶磚內蘊含的資源,像是快取、記憶體、I/O,也因此對於整個系統單晶片而言,可以獲得低延遲與大量的跨區存取頻寬(cross-section bandwidth)等好處,進而實現低抖動(low Jitter)的系統穩定執行表現。同時,用戶者還可以在此啟用Sub-NUMA與Sub-UMA層級的叢集,以獲得額外的效能與延遲度改善。
.png)
Sapphire Rapids晶片採用新一代模組化設計
單體(Monolithic)型態的晶粒(Die)是英特爾Xeon系列處理器沿用多年的設計方式,而在即將問世的Sapphire Rapids身上,他們改用多個晶磚(Tile)的作法,在設計上,可具有更大的擴充性、平衡度,得以如此的箇中關鍵,正是英特爾發展的嵌入式多晶片互連橋接(EMIB)技術,而在這樣的架構之下,處理器的每一個執行緒,都可以完整存取所有晶磚的資源。圖片來源/英特爾

英特爾下一代伺服器處理器搶先亮相
在8月底舉行的英特爾架構日期間,該公司設計工程事業群資深院士暨首席架構師Sailesh Kottapalli,透過線上發表會的形式,介紹了下一代伺服器處理器Sapphire Rapids的整體特色,並且展示實際的產品。圖片來源/英特爾
整合高效能核心與加速器引擎
在處理器的組成元件上,過往英特爾在不同世代的產品當中,主要是透過導入新的微架構來提供新的功能特色。

而在個人電腦平臺的下一代處理器Alder Lake,以及伺服器平臺的下一代處理器Sapphire Rapids,均採用複合式搭配方式──前者混合搭配兩種微架構:代號為「Gracemont」的高效率核心(Efficient x86 Core,E-Core),以及代號為「Golden Cove」的高效能核心(Performance x86 Core,P-Core);後者則採用高效能核心,以及多種與資料中心應用有關的加速器引擎,可直接在處理器內部提供異質運算架構。

而在Sapphire Rapids採用P-Core之後,可獲得下列好處。首先可受益於Intel 7製程的技術突破,在微架構與每週期指令(IPC)的執行效能上,獲得改善;其次,對於伺服器處理器因為處理資料中心規模的大量程式碼與資料,而出現存取瓶頸的狀況,P-Core在前端設計上,配置數量更多的指令轉譯後備緩衝區(iTLB)、解碼器(支援更大的解碼寬度)、微操作佇列(μop Queue)、微操作快取(μop Cache),同時也改善指令分支預測的精準度,採用更聰明的程式碼預先存取機制,能有效降低L1快取延遲,針對L2快取的完全寫入提供頻寬預測最佳化處理。

第三,針對多租戶服務這類資料中心運作模式,P-Core具備多種功能,像是:VM快速遷移、進階的快取與TLB服務品質確保(QoS),以便提供一致的效能。第四,則是提供自主、控管粒度更細緻的電源管理機制,P-Core可因應高時脈的運作,在不發生抖動的狀態下,提升處理器核心的效能。
.png)
提供更寬大、聰明的運算執行架構
Sapphire Rapids處理器採用的微架構,是代號為Golden Cove的高效能核心(Performance Core),可針對低存取延遲與單執行緒應用程式,提供更好的處理效能,能強化一般用途的系統執行,也更足以支撐蘊含大量程式碼與資料的應用程式。圖片來源/英特爾
此外,P-Core本身也內建多種加速指令集架構與功能支援,可因應資料中心的應用需求。當中最受矚目的莫過於進階矩陣延伸指令集(AMX),可針對深度學習工作負載當中的張量運算,提供大規模的加速處理,而這也是Sapphire Rapids主打的特色。
而在運算能力上,有了AMX,可讓Sapphire Rapids具備更強大的AI效能。例如,在每個處理器運算執行週期當中,AMX可以完成2,048個INT8整數運算,以及1,024個BF16浮點運算。若以現行的AVX-512指令集來處理,只能完成256個INT8整數運算,以及64個BF16浮點運算;英特爾也基於早先發展的Sapphire Rapids產品,透露矩陣乘法微型測試結果,結果發現:相較於現有AI加速指令集AVX-512 VNNI,採用AMX的處理速度可達到7倍之高。

另一個是加速器介接架構(AIA),針對加速器、裝置的連接,可在系統的使用者模式(User Mode)層級,以原生、有效率的方式,執行調度、同步、訊號傳遞等任務,而不是到工作繁忙的核心模式(Kernel Mode)執行。
搭配功能更強大的運算核心之餘,英特爾在Sapphire Rapids也首度導入加速器引擎的設計,針對資料中心層級通用的作業模式,提供高階的最佳化處理機制,藉此減輕常態下的運作負擔,以及提升P-Core的資源利用率,進而拉抬使用者工作負載的效能。
舉例來說,上述AIA,以及後面提到的進階虛擬化功能,也被英特爾歸類於加速器引擎,除了減輕核心模式的經常性負擔,還能避免複雜的記憶體管理。
目前Sapphire Rapids還提供哪些加速器引擎?首先是前面我們曾提到的資料串流加速器(DSA),這是專為資料中心環境最常見的資料搬移作業,舉凡封包處理、資料縮減、虛擬機器遷移時的快速建立檢查點,所設計的卸載功能,能夠提升整體工作負載的效能,適用範圍可涵蓋處理器、記憶體、快取,以及各種透過I/O介面連接的記憶體、儲存裝置、網路設備之間的資料搬移活動。
而在實際應用上,目前每顆處理器可支援4個DSA加速器實體,根據英特爾進行的Open vSwitch測試當中,處理器利用率能因此減少39%,而在資料搬移的效能上,可改善至2.5倍的幅度。
.png)
內建加速器引擎,在處理器內部實現異質運算
過去英特爾處理器通常會以內建各種指令集的方式,就近實現多種加速運算,但Sapphire Rapids於處理器核心之外,增添了加速器引擎的配置,可運用這種方式將常見的工作卸載到加速器引擎執行,為關鍵工作負載騰出更多可用的運算容量。圖片來源/英特爾
第二個新世代處理器內建的加速器引擎,是英特爾發展已久的Quick Assist Technology(QAT),-而且,Sapphire Rapids將提供的是新一代QAT引擎,可大幅提升效能與實用性,並且不僅支援最常見的加密、雜湊、壓縮等演算法,還能將這些作法串在一起使用。而對於資料中心環境當中,能以加密方式針對全部數據的儲存、傳輸、使用進行保護,面對持續增長的資料量,企業也能善用這項技術,促使相關數據維持在壓縮的格式。英特爾表示,若以QAT來處理這些資料,會比使用P-Core還要快,而且執行同樣的功能時,還能減少需要的運算核心數量。
而在加密處理作業上,英特爾表示,QAT如今可提供400Gb/s的效能(對稱式加密),而同時進行壓縮與解壓縮的處理上,均可達到160 Gb/s。而在英特爾運用Zlib L9壓縮演算法的測試當中,處理器使用率降低50%,壓縮速度是未啟用QAT的22倍。相對地,若不啟用QAT,要得到同樣的效能,英特爾預估要運用1千顆P-Core才能達成目的。
關於加速器引擎,除了DSA和QAT,英特爾在8月23日舉行的Hot Chips大會,針對Sapphire Rapids的介紹,還補充前一週架構日所未提及的動態負載平衡(Dynamic Load Balancing,DLB),顧名思義是針對多個處理器核心提供平衡負載的處理,每秒可執行4億個負載平衡決策,也能將軟體型態的佇列管理工作卸載到這裡執行;在優先處理的佇列排定上,最多可設置8個層級;在動態處理的部份,DLB可提供流量感知的負載平衡與重新排定執行順序,對於應用程式的可用資源容量,DLB也能支援動態、耗電量感知的配置處理。

I/O介面大躍進,支援PCIe 5.0、CXL 1.1等業界新規格
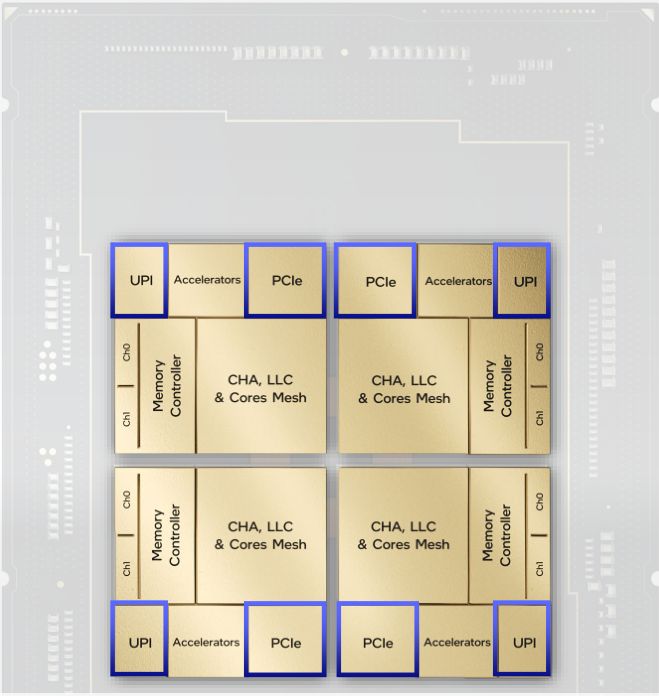
針對伺服器對於記憶體與加速器擴充需求,Sapphire Rapids支援1.1版的CXL,基本上,CXL是針對處理器、記憶體擴充、加速器的互連機制,它運用PCIe 5.0實體層的基礎設施與PCIe替代協定,可因應高效能運算負載。
或許是支援CXL 1.1的關係,Sapphire Rapids也順勢支援PCIe 5.0,提升周邊裝置I/O存取效能,英特爾也針對這部份提供了改良的服務品質確保(QoS),以及DDIO(Data Direct I/O)技術,與這項新規格支援一起推出。
而英特爾本身發展的多顆處理器互連技術UPI(Ultra Path Interconnect),是在2017年Xeon Scalable系列處理器推出而一起問世的,當時取代了QPI(QuickPath Interconnect),而經過三代以來的採用,如今也將隨著Sapphire Rapids推出UPI 2.0版,將提供更多連結(4個)、更大的頻寬與更快的傳輸速度(16 GT/s )。
在Hot Chips大會上,英特爾特別補充了I/O虛擬化的兩大功能:共享虛擬記憶體(Shared Virtual Memory,SVM)、可擴展I/O虛擬化(Scalable I/O Virtualization,S-IOV),屬於進階的虛擬化應用特色。
基本上,SVM能在處理器的虛擬定址空間,讓裝置與Intel架構運算核心能夠在此存取共用資料,可避免記憶體固定於一處與進行內容複製的常態負擔,適用於整合型、獨立型、裸機型、虛擬機器型的執行個體服務。
至於S-IOV,能夠在虛擬機器/容器與PCIe裝置之間,提供通用的硬體加速機制。舉例來說,S-IOV可橫跨數千臺虛擬機器/容器,提供硬體加速器的可擴展式共享,以及直接存取等兩種方式。這種作法能夠比現行大家熟知的SR-IOV,提供更大的延展性,而且比起僅限軟體的裝置擴展方式,S-IOV可提供更高的效能。而在支援的裝置類型上,S-IOV可用於整合型與獨立型裝置。

支援DDR5、HBM新世代記憶體
提供平衡的快取與記憶體架構,同樣是Sapphire Rapids的賣點,英特爾希望能在低延遲的狀態下,提供足夠的持續存取頻寬。
在內建快取記憶體的部分,Sapphire Rapids支援大容量的共用快取,以便讓整顆處理器能夠動態共享這些內容,因此在L3快取上,英特爾決定配置比過往配置多一倍的容量(100 MB以上),並強化服務品質確保的機制。
在伺服器系統DRAM記憶體的搭配上,Sapphire Rapids將會支援DDR5,可獲得頻寬更大(5200 Mbps)、更省電(1.1伏特)等特色,而且,英特爾在此同樣會是搭配4個記憶體控制器,支援8個通道的存取。
至於儲存級記憶體應用,英特爾長期主導發展的Optane Persistent Memory,將推出第三代產品,亦即300系列,Sapphire Rapids也會提供支援。

除了這些記憶體類型之外,Sapphire Rapids也將在部分產品的版本中,整合高頻寬記憶體(HBM),以因應密集型平行運算的高效能需求,像是高效能運算、機器學習、記憶體內(In-Memory)資料分析等工作負載,屆時將會提供兩種運作模式:以同樣的記憶體區域搭配HBM與DRAM使用的均一模式(Flat Mode),以及支援DRAM記憶體的快取模式。
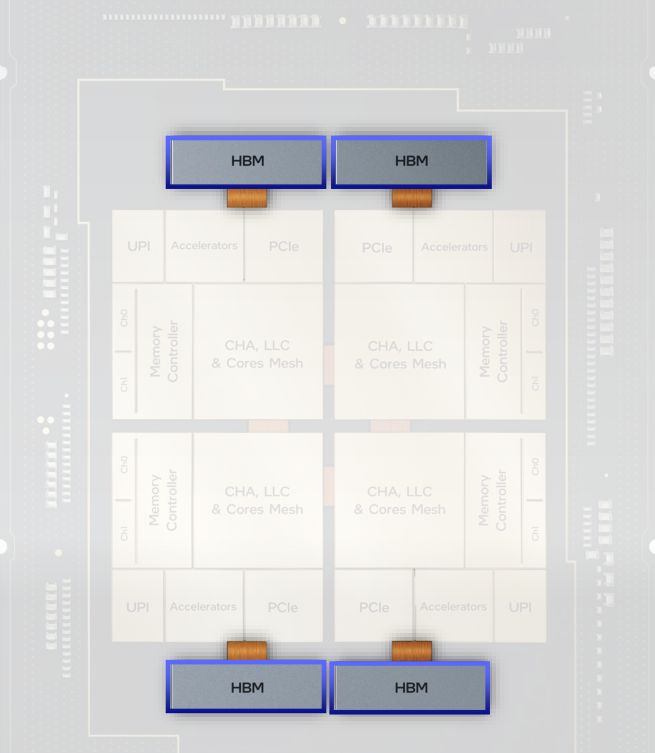
基於上述的新世代記憶體類型,英特爾也將支援記憶體分層應用(Memory Tiering),例如,軟體可存取的HBM+DDR記憶體資源,以及介於HBM與DDR之間的軟體透通式快取。
%2B(5).png)
對於微服務,以及整數與浮點運算的應用,提供大幅提升的效能
英特爾架構日公布Sapphire Rapids的效能測試比較結果,在微服務的部分,受益於AIA、DSA、QAT等加速器引擎的使用,以及多種分攤系統經常負擔的處理機制,相較於第二代Xeon Scalable系列處理器,英特爾新發展的下一代伺服器平臺Sapphire Rapids可提升70%的效能(左圖);而在整數運算與浮點運算上,Sapphire Rapids新增的AMX延伸指令集可帶來相當顯著的效能增長,連帶也能大幅提升機器學習類型工作負載的處理能力(右圖)。圖片來源/英特爾
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09