
| Databricks | MLflow | 資料集 | AI agent
Databricks推出新API可迅速合成機器學習評估資料集
Databricks新的合成資料生成API,讓企業能在數分鐘內,根據專有資料自動生成機器學習評估資料集,支援自定義問題指南,並與現有評估平臺整合,提升人工智慧代理的測試與除錯效率
2024-12-12

| Overture Maps | 開放地圖 | 資料集
電子地圖基金會Overture Maps發布開放地圖資料集的正式版
由AWS、微軟、Meta及TomTom共同創立的Overture Maps基金會正式發表開放地圖資料集,包括全球23億個建築物,5千多萬個興趣點,支援逾40種語言的國家及地區的行政邊界,以及涵蓋水及土地的基礎資料
2024-07-25
| SmolLM-Corpus | 資料集 | 小語言模型 | SmolLM | Hugging Face
Hugging Face公布可在手機上執行的語言模型SmolLM家族
Hugging Face研究人員公布小語言模型家族SmolLM,強調是以謹慎策畫的高品質資料集訓練而成,同時釋出該資料集並說明其內容及規畫方法
2024-07-18

蘋果、Nvidia等公司被控未經同意使用YouTube文字內容訓練AI
調查報導媒體Proofnews分析發現,蘋果、Nvidia、Anthropic及Salesforce等業者,使用內含YouTube平臺17萬則公開影片字幕的《The Piles》資料集來訓練其AI模型,但《The Piles》資料集建立者並未取影片作者的使用許可
2024-07-17
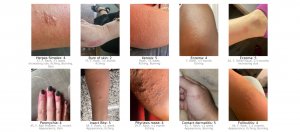
Google公開皮膚病狀圖片資料集SCIN,涵蓋各種膚色與身體部位
Google與史丹佛大學合作創建皮膚病狀圖片資料集SCIN,主要收集不同膚色與身體部位,常見的皮膚病狀照片,補充臨床皮膚疾病資料集的不足
2024-03-20

| IT周報 | 3D物件 | 生成式AI | 資料集 | google | NotebookML | Bard
AI趨勢周報第221期:超過1千萬個3D物件的大型資料集來了
多家頂尖AI研究機構聯手打造超大3D物件資料集,加速零樣本AI發展;彭博社研究發現Stable Diffusion也有膚色種族偏見;盤點全球23家銀行AI成熟度,摩根大通遙遙領先;微軟研究院用LLM打造AutoML工具,可自動調參、選最佳架構。
2023-07-16

| IT周報 | google | Transformer | 機器人 | 導航 | 資料集 | 搜尋 | 大型主機
AI趨勢周報第210期:Google用Transformer模型即時導航機器人
Google成功用Transformer模型即時導航機器人,延遲僅8毫秒;司法院法庭中文語音辨識系統正式上線,準確率超過9成;Google搜尋再優化,新添資料集搜索引擎;Brave搜尋引擎自建生成式AI,幫摘要搜尋結果;IBM大型主機作業系統將擁抱AI
2023-03-09

推特調查近期一系列媒體報導推特使用者資料洩漏的新聞,表示未有新的資料洩漏事件發生,皆是重複以及未包含機密資訊的資料集
2023-01-12
![]()
Linux基金會AgStack專案所維護的資料集Asset Registry,將會收集全球農地邊界,以用於食品追蹤、碳追蹤和田野分析等用例
2022-12-22

| google | 資料集 | 透明度 | Data Cards Playbook
Google釋出資料集透明度工具Data Cards Playbook
Google推出的Data Cards Playbook工具,可用於建立連續且具脈絡的資料及透明度,有了這個透明度基礎,開發人員才能更方便地開發負責任機器學習系統
2022-11-25

| google | 電腦視覺 | 資料集 | Open Images
電腦視覺資料集Open Images V7新增點標籤,可用於實例分割模型訓練
Open Images V7新加入點標籤,研究人員提到,使用點級標籤註解這類稀疏資料,訓練和評估分割模型,與密集註解資料所獲得的效果差不多
2022-11-01

Google釋出地理多樣性圖片說明資料集Crossmodal-3600
Crossmodal-3600中的圖片涵蓋世界各地理位置,每張圖片都有36種語言的文字說明,能夠用於評估圖片說明生成模型研究
2022-10-16