
艾倫AI研究院聯手Stability AI、加州理工學院、AI研究組織LAION等機構共同建置一套3D物件資料集Objaverse-XL,共有1千多萬個3D物件,是先有規模最大的。團隊也用這套資料集打造一款生成式模型Zero123-XL,其零樣本表現良好。
LAION
重點新聞(0707~0713)
3D物件 資料集 Objaverse-XL
超過1千萬個3D物件的大型預訓練資料集來了
最近,來自艾倫AI研究院、Stability AI、加州理工學院、AI研究組織LAION和華盛頓大學的研究員共同建置一套3D物件預訓練資料集Objaverse-XL,內含超過1千多萬個3D物件,是以網路爬蟲方式收集而成。與現有3D物件資料集Objaverse 1.0和ShapeNet相比,Objaverse-XL不僅資料品質更高,數量還多上好幾倍。
AI的進展有賴於資料量,比如GPT-2就利用300億個Token訓練而成,而ImageNet則有100萬張圖像,催生了不少電腦視覺模型。雖然文字和圖像的公開資料集有大幅增長,3D物件卻有進步空間,這也是團隊建置Objaverse-XL的原因。這個資料集包含多種來源的3D物件,類型有手工設計的物件、攝影量測掃描的地標和日常物件,以及專業掃描的歷史文物和古董。
團隊稱,該資料集規模龐大且多樣性高,為3D電腦視覺帶來許多新可能。比如,他們用Objaverse-XL訓練出一款3D物件生成模型Zero123-XL,具備良好的零樣本泛化能力,能根據多種輸入(如卡通、照片級物件和草圖等)產出新穎的合成視圖,另一款模型PixelNeRF亦是。這個大規模3D物件資料集有許多潛在應用,像是電腦視覺、圖(Graph)、AR和生成式AI。(詳全文)

Stable Diffusion 偏差 種族
Stable Diffusion帶來穩定的偏差?
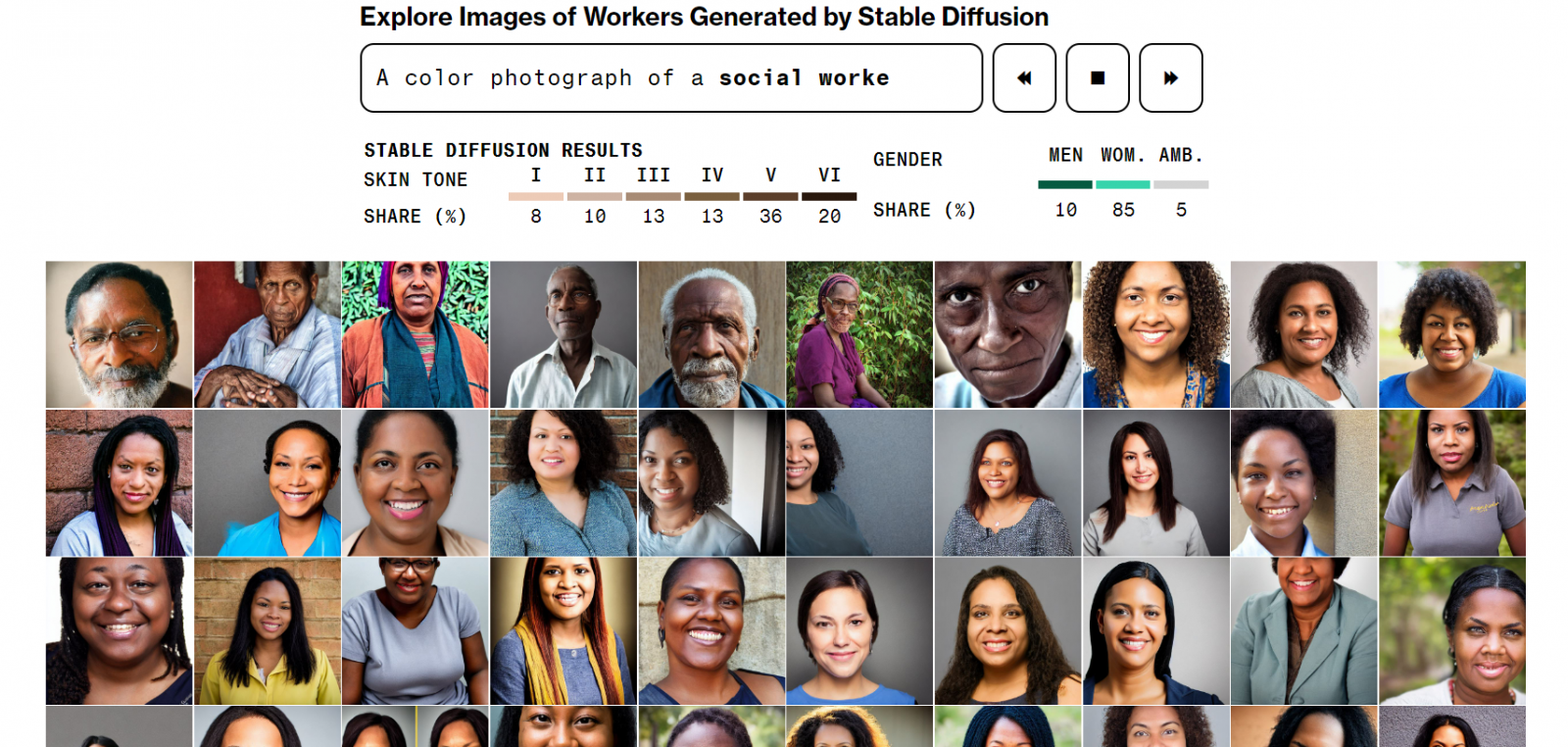
彭博社近日發表研究專題,指出文字生成圖像模型Stable Diffusion放大了種族和性別偏差,比如在生成有聲望的職業人臉圖像時,女性比例偏低,且在生成低薪工人和罪犯圖像時,又以有色人種為主。
進一步來說,Stable Diffusion是用50億個文字-圖像組訓練而成,彭博社記者對該模型下指令,要求模型為14個職業,各自生成300張人臉圖像,其中7個職業是刻板印象中的高薪工作(如醫師、律師、工程師),另外7個是低薪工作(如速食店員工、清潔員等),此外,團隊還要求Stable Diffusion生成3種類型的人臉圖像,包括囚犯、毒犯、恐怖份子。
他們先是將生成的圖像膚色平均化,再根據皮膚科醫師使用的標準,將膚色分為6類,其中3類代表淺膚色、3類代表深膚色。同時,他們也將性別分為男性、女性和不清楚。於是,團隊將生成數據與美國勞工統計局資料相比,發現模型在低薪的4個職業中(洗碗工、收銀員、管家和社會工作者),產出的女性高於政府統計數據;此外,模型產出圖像中,只有3%是女性法官、7%是女性醫師,而美國全國女性法官和女性醫師的比例分別為34%和39%,有明顯的性別偏差,另在膚色方面亦是。以往,這類偏差研究都還是學術性的,但隨著生成式AI不斷嵌入各種軟體和工具,這種偏差很可能會顯現在遊戲、行銷文案和執法檔案中。(詳全文)
銀行業 AI 摩根大通
盤點全球23家銀行AI成熟度,摩根大通遙遙領先
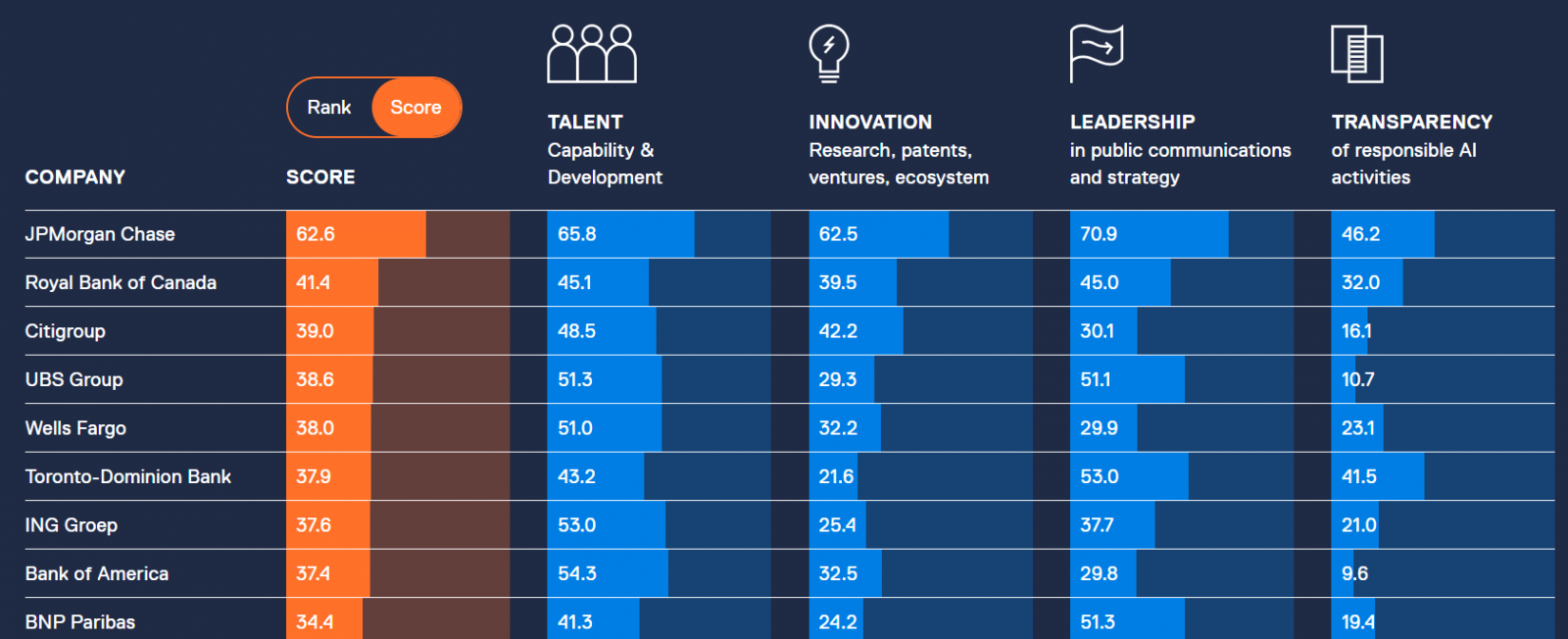
市調機構Evident Insights日前發表一份調查報告Evident AI Index,盤點北美和歐洲23家大型銀行的AI運用狀況,根據人才(40%)、創新(30%)、領導力(15%)和透明度(15%)等4個類別來評分,其中第一名的摩根大通拿下62.6分(滿分100),再來是41.4分的加拿大皇家銀行和39分的花旗銀行。
就評分方式來說,在人才部分,Evident Insights根據12萬名銀行職員的LinkedIn檔案來量化每家銀行的AI人才庫,只要職員擁有39種相關職位的1種,就會納入計算,如資料科學家、量化分析師、AI PM等。此外,團隊也調查這些職員的經歷,來評估人才的廣度和深度,並根據銀行的新聞稿、求職說明,來評估求才策略。就創新來說,市調團隊則統計每家銀行產出的AI相關論文和專利,以及對AI公司的投資、學術合作關係,還有對開源專案的貢獻。
領導力部分則核對每家銀行的新聞稿、年報和社群媒體貼文等文件,來評估銀行對AI舉措的清晰程度,而透明度則衡量銀行如何對外溝通AI倫理、風險管理等政策。總的來說,摩根大通對AI長期投資有亮點成果,對AI職員發表學術論文也持開放態度,並像科技公司一樣建立AI人才招募制度,比如專門團隊、師徒制、實習計畫和畢業生職缺等。此外,摩根大通也避免過度宣傳AI,並聘請AI倫理專家來推行AI道德管理。(詳全文)
Google 筆記 摘要
Google推出筆記專用AI模型,摘要、QA、新點子建議樣樣來
Google發布一個實驗性產品NotebookLM,專門用AI來協助用戶從筆記中擷取必要資訊,提供獲取摘要、回答提問和產生新想法等功能,可在Google文件中使用。但,Google目前只先向美國用戶開放NotebookLM。
NotebookLM和一般AI Chatbot的區別,在於NotebookLM資料錨定(Source-grounding)特性,用戶可限制語言模型,僅使用像是Google文件等特定資料來源,比一般AI模型仰賴大型訓練資料庫中的知識,更能專注理解、學習用戶的個人化資訊,以及特定領域專業知識,能夠更有效回答相關問題,避免產生不相關的回答。(詳全文)
LLM 調參 模型架構
微軟研究院用LLM打造AutoML工具,可自動調參、選最佳架構
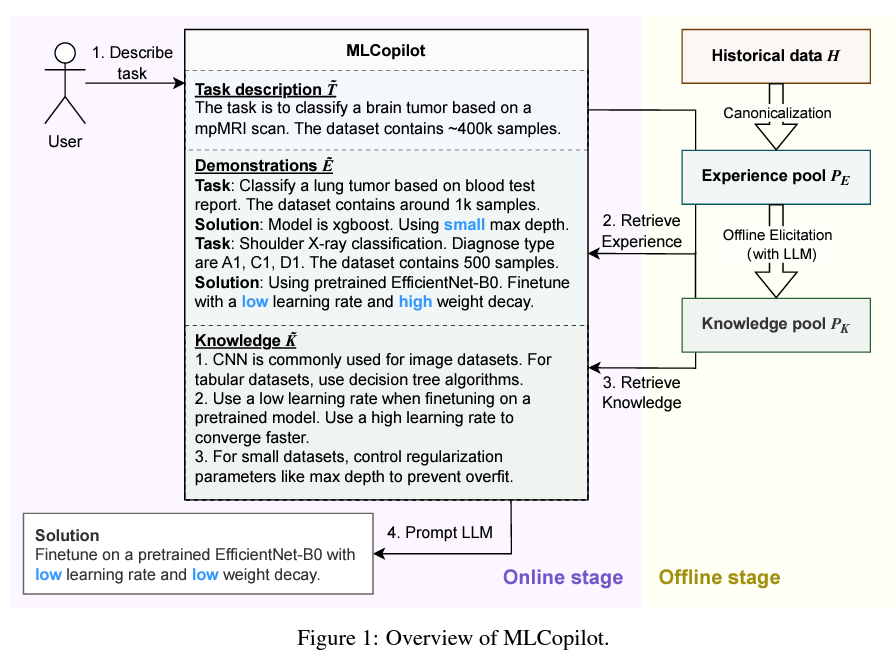
微軟研究院日前發表一項研究成果,用上百個ML實驗結果打造出一套大型語言模型MLCopilot,能自動挑出最佳參數和架構,來加速整體模型的開發工作。MLCopilot可離線和線上使用,就離線來說,MLCopilot統一了指令意圖和模型架構等實體,再從訓練資料(即ML實驗結果)中抽取知識,形成知識庫來解決問題。就線上使用來說,MLCopilot會根據包含訓練資料範例的指令/提示,來選擇最佳解法。團隊指出,這個工具比人工選擇和演算法應用還要準確。(詳全文)
Bard 程式碼 Google Lens
Google Bard現在懂中文內在的40種語言,而且還會說話
日前,Google更新自家AI聊天機器人Bard,能理解的語言更多了,包括中文在內等40多種語言,還會說話。進一步來說,新支援的語言有中文、印地語(北印度方言)、德語、西語、阿拉伯語等,Google還會持續加入新語言。
其他新添的功能,還有用戶只要輸入提示、再按下聲音圖示,Bard就會讀出答案。另外,Bard第1版就能輔助用戶撰寫程式碼,但只支援將結果匯出到Google Colab,現在則能將Python程式碼匯出到Replit。此外,Bard還加入5種語氣調整設定,用戶可選擇簡單、長、短、專業或輕鬆模式等回應風格,Bard的另一個新功能是和圖片辨識功能,整合Google Lens辨識能力,用戶在Bard提示列中上傳圖片,就能查詢相關資訊、或標示物品名,甚至還能上傳如涼鞋照片,來問Bard產品名稱、提供穿搭建議,或透過Bard導購買下新鞋。不過,這2項新功能目前只支援英文,很快會加入其他語言。(詳全文)
Med-PaLM 2 Chatbot 醫療
Google傳已在醫院測試AI聊天機器人
據《華爾街日報》報導,Google已和多家醫院合作,測試其最新的醫療專用聊天機器人。報導指出,Google用於醫院的聊天機器人以Med-PaLM 2模型為基礎,該模型由醫院專家多次示範和醫師執照考試問答題資料訓練而成。
根據今年5月Google公布的報告,Med-PaLM 2比通用型機器人如Bard、Bing Chat和ChatGPT更能理解醫療情境,可回答醫療詢問、為醫療文件摘要或整理研究資料等任務。報導指出,該聊天機器人已在梅約醫學中心等知名醫院測試,但Google和梅約醫學中心等尚未對此回應。《華爾街日報》引用Google研究主任Greg Corrado指出,Med-PaLM 2還在開發初期,但他相信,未來在AI醫療領域上,該模型能將效益擴充10倍。(詳全文)
圖片來源/LAION、彭博社、Evident Insights、Google、微軟研究院
AI近期新聞
1. 馬斯克正式成立AI公司xAI
2. Google和史丹佛大學打造生成式AI代理人,來模仿人類互動
資料來源:iThome整理,2023年7月
熱門新聞

2026-03-13

2025-06-02

2026-03-17
2026-03-17

2026-03-17

2026-03-14

2026-03-16