| Gemini Diffusion | Google AI | 擴散式生成 | AI文字生成 | 語言模型
Google Gemini Diffusion新模型得益於擴散機制,大幅加速文字生成效率
Google釋出Gemini Diffusion,該公司首次將擴散式生成機制應用於人工智慧文字生成,大幅提升生成速度與內容一致性,適用長文本及結構化資料等高一致性需求的場景
2025-05-23

| Databricks | 語言模型 | AI代理人 | 批次推理 | 企業AI應用
Databricks推人工智慧模型治理、對話API與批次推理新工具,供企業集中管理模型,加速人工智慧代理開發,免自建置基礎設施即可執行批次推理
2025-03-12


| Deepmind | Mind Evolution | 語言模型 | 自然語言規畫 | 推理效能提升
DeepMind公開Mind Evolution研究,結合LLM提升自然語言問題求解效能
DeepMind新的Mind Evolution技術,透過結合語言模型與演化式搜尋,有效解決自然語言規畫與推理中的效率與準確性挑戰,大幅提升問題解決能力
2025-01-23
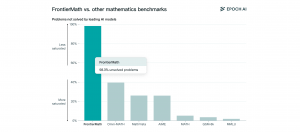
新數學基準測試FrontierMath凸顯AI模型邏輯推理進步空間極大
FrontierMath是針對評估人工智慧高階數學推理能力,而設計的數學基準測試,目前市面上知名模型的解題成功率低於2%
2024-11-13
提示任務,可分為6點,如情境(C)是指在提示中描述任務概況、賦予LLM角色,目標(O)則是在提示中,告知LLM想實現的目標。這個方法論,有助於提示管理。(圖片來源/Line)")
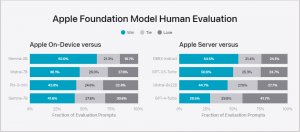
| Apple Intelligence | 語言模型 | 蘋果
蘋果揭露Apple Intelligence所使用的裝置與伺服器模型
蘋果新一代作業系統將內建基於生成式AI技術的Apple Intelligence功能,目前蘋果先對外揭露Apple Intelligence運作於裝置端以及伺服器端的基礎模型技術細節與效能表現
2024-06-12

蘋果釋出可在自家裝置端執行的OpenELM模型家族以及訓練/推論框架,OpenELM最小版本僅2.7億參數
2024-04-26
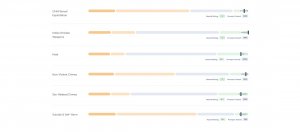
MLCommons AI安全工作小組發布AI Safety v0.5基準測試,可評估語言模型對特定危害類別的反應,預計在今年稍晚推出更全面的v1.0版本
2024-04-18

| IT周報 | AI2 | 開放研究 | 語言模型 | AIOps | 評估框架 | Hugging Face | google
AI趨勢周報第241期:號稱真正開源!AI2釋出OLMo語言模型和所有相關資料
AI2釋出2款語言模型,以及所有相關數據如訓練程式碼、預訓練資料集、評估套件等;Juniper發表AIOps服務;AI可自我評估輸出對錯!Google釋出新框架;OpenAI推出2大新嵌入式模型;Google Cloud與Hugging Face宣布策略聯盟
2024-02-05
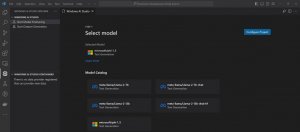
微軟推出Windows AI Studio簡化Windows本地端AI應用開發
Windows AI Studio是微軟新發布的Windows平臺人工智慧開發工具,透過提供Azure AI Studio、Hugging Face上的模型,供開發者在本地端進行人工智慧應用開發
2023-11-17