上,揭露自監督學習的研究進程,同時也在演講結束後,和與會者面對面探討各類深度學習的議題,還很親切的接受合照。")
卷積神經網路之父Yann LeCun,今天在全球影像處理會議(ICIP大會)上,揭露自監督學習的研究進程,同時也在演講結束後,和與會者面對面探討各類深度學習的議題,還很親切的接受合照。
攝影/王宏仁
臉書AI研究院首席科學家、同時被譽為卷積神經網路之父的Yann LeCun,今年更獲得素有電腦界諾貝爾獎之稱的2018年圖靈獎(Turing Award)殊榮,終於在睽違兩年後,今天再度來臺,在匯聚全球頂尖人才的全球影像處理會議(ICIP大會)上,發表自監督學習(Self-supervised Learning,SSL)在深度學習領域的發展,不僅能用來預測文字片段,也已經初步應用在影片未來動態的預測,比如自駕車先預測周遭車輛的行駛軌跡,再決定接下來的行駛方向。
Yann LeCun認為,自監督學習能突破現有深度學習方法的侷限。比如說,最廣泛使用的監督式學習(supervised learning),是由人給定標記好的資料,讓機器學習正確答案並作為推論根據。但是,這種學習方法是立基於人的標記,不僅資料標記過程需要花費大量時間與資源,機器也只能根據已標記的特徵來學習,完成指定的任務,如語音轉文字、分類圖像、物件辨識等。
又比如強化學習(Reinforced Learning),是透過獎勵與懲罰的機制,讓機器在虛擬情境中不斷試錯(trial and error),累積經驗來學習。這種學習方式雖然在競技比賽裡表現良好、甚至能勝過人類,但學習效率極低。舉例來說,人類在15分鐘內能領略的任一款Atari遊戲,機器卻平均要花83小時才能學會,在臉書研發的虛擬圍棋遊戲ELF OpenGo中,更要用2000個GPU訓練14天,更別提要訓練200年才學得會的星海爭霸遊戲(StarCraft)。
而且,強化學習並不能永遠在虛擬場景訓練,一旦進到真實世界,所有試錯的過程將會帶來高成本的代價。比如說,在自駕車了解前面是懸崖要轉彎之前,可能需要先掉下去幾百次,且不同於虛擬世界可以無間斷的循環訓練,在真實世界中花費的訓練時間只會更長;更何況,人類學習過程只需極少數「試錯」的過程,比如在看到前方的懸崖之後,常識就會使我們轉彎。
對此,Yann LeCun認為,自監督學習能解決這個問題。比起強化學習是從試錯的經驗中學習,自監督學習是建構一個龐大的神經網絡,透過預測來認識世界。換句話說,自監督學習所訓練的模型,能藉由觀察過去、當下所有的訓練資料,來預測下一刻會發生的事情,因此,在預測到車子將會摔落懸崖時,就能提前轉彎來避免。「就像人類是不斷透過已知的部分來預測未知,看到一半的人臉會自動在腦海補足另一半畫面,所以自監督學習是更接近人類學習行為的方法。」
影片、聲音等高維度連續資料的預測仍為自監督學習的挑戰
要更詳細的解釋自監督學習之前,Yann LeCun先舉例解釋人類的學習行為。如果在一個5個月大的小嬰兒面前,展示一輛漂浮在空中的玩具車,從零開始學習的嬰兒只會覺得,這就是這個世界運行的方式;然而,如果在一個兩歲的孩童面前這麼做,孩子將會很驚訝,因為他已經透過長期的觀察,在腦海裡形成一套常識,雖然他還無法理解「地心引力」這個名詞,卻知道玩具車不該漂浮在空中。

小嬰兒隨著年齡會經歷不同階段的學習。
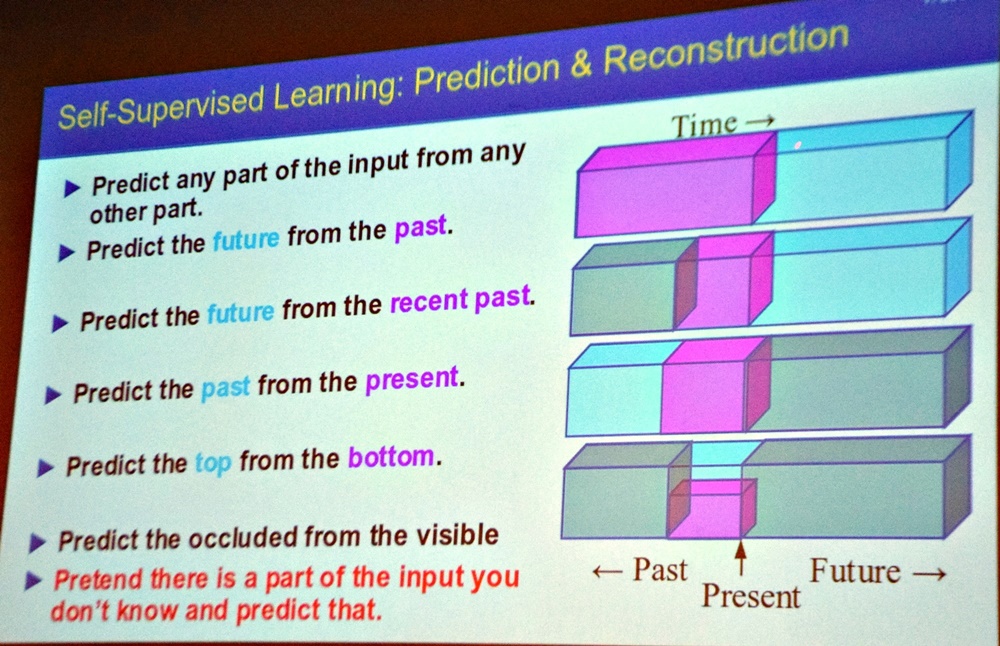
也就是說,「人類大部分是透過觀察來學習,少部分才是靠互動交流。」而自監督式學習,也是透過觀察,從現有訓練資料中的任何部份來學習,去預測未知的部份,而且學習過程中並不仰賴人類給定的標籤。Yann LeCun表示,不管是從過去的資料預測現在或未來、從近期的資料預測未來或過去、或從同一時間下的其他資料預測缺失的部份等,都能運用自監督學習來完成。
Yann LeCun也進一步以蛋糕,來比喻上述提到的三種學習方法,所能預測的資料量。其中,以強化學習能預測的資料最少,是基於獎勵才能做出少量正確的預測,就像蛋糕上的櫻桃;而監督式學習的預測資料量,是取決於人類提供的標記資料,一個樣本能回饋10-10,000 bits不等的訊息,像是蛋糕的表層;但是自監督式學習,則是給多少資料,就有多少資料能觀察,一個樣本能產生上百萬bits的預測回饋,就像整個蛋糕本身,這是其他學習方法所不能及的。

此外,在應用方面,自監督式學習目前在自然語言處理(NLP)的應用頗有成效。比如去年Google對外開源了用於自然語言預訓練的新技術BERT(Bidirectional Encoder Representations from Transformers),能在一個挖空15%內容的句子中,預測字彙並填空;其他相關的應用,還包括Word2vec、FastText、Cloze-Driven Auto-Encoder等文本內容處理模型。
除了NLP,圖像的填空是更具挑戰性的任務,但現在也已經能夠過拼圖與著色問題的解法來預測。因為自監督式學習適合用來預測具有離散分布(discrete distribution)特性的資料,所以在著色的部分,就能運用離散分布的方式,將顏色量化為較少數量的顏色種類,再挑選出可能代表該位置的顏色來著色;而拼圖問題則是能用基本的分類問題解法,先對資料的特徵進行訓練,再進行預測。
但是,自監督學習在影片或聲音識別的領域卻不如預期。這是因為動態的影像與聲音資料,都是屬於高維度的連續性(High-dimensional Continuous)資料,很難參數化(parametrize)其可能的離散分布,在這個情況下,就時常預測出含有多種可能性的結果。對此,Yann LeCun提出一個架構,要建構出世界模擬器(world simulator)模型,來預測現實環境將會因為每個決策產生什麼改變,再客觀的去衡量哪一種決策更有利。
對於自監督學習在影片預測的成效,Yann LeCun也提出一個研究案例。在一段高速公路的車流影片中,針對其中一輛車的行進路線進行測試,來檢視自監督學習模型,是否能藉由預測自駕車周遭車輛的行駛軌跡,來估算接下來的行駛方向與速度,測試過程中也保留原始的車輛,另外模擬出一輛不存在的自駕車,來對比兩輛車的行進路線差異。而這個模型也證實了動態影像預測的可行性。

黃色的是原本車輛,藍色的是虛擬自駕車。
對於AI的發展,Yann LeCun認為,現今的深度學習方法,雖然能帶給人類新科技的應用,如自駕車、醫療影像分析、語言翻譯、聊天機器人等,卻無法創造出「真正的」人工智慧,也就是具備常識、聰明、敏捷且靈活的機器人。不過他也認為,「儘管機器學習系統仍有侷限,但自監督學習可能是個解方,甚至在未來建構出擁有人類常識的機器人(Human Level Intelligence)。」而接近人類學習行為的自監督學習方法,就是實現這個理想的第一步。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-25

2026-02-23