
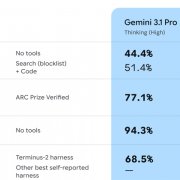
一群來自Stanford、Harvard、Yale、Berkeley等多所大學的數學家,於2026年2月在arXiv發布《First Proof》,提出10道源自實際研究過程的數學問題,旨在建立更貼近真實學術流程的評估方法,以檢驗AI能否自主完成研究級數學證明。OpenAI於2月14日公開其模型對這10題的證明嘗試,並表示其中至少5題具有高度正確可能。
不同於數學競賽題目,First Proof所提出的10道問題皆來自作者實際研究過程中的關鍵中間命題(Lemma),是數學家在撰寫論文或推進理論時自然產生的問題,答案尚未公開並經加密處理,以避免資料污染。此外,這些題目需要完整、可被專家逐步驗證的證明,而非簡短數值答案。
作者強調,此實驗聚焦於數學研究的「最後一個階段」——在既有理論框架下完成嚴謹證明。他們希望透過這種設計,測試AI是否具備長鏈推理與學術級嚴謹度,而非僅在競賽式基準測試中取得高分。
至於OpenAI則是採用一個新的內部模型來測試上述10道First Proof題目,這些問題需要於專門領域中建立端到端的論證,而作者都是各領域的專家;OpenAI在2月14日公開證明嘗試,根據迄今所取得的回饋,至少有5題具備高度正確可能。
OpenAI表示,前沿研究挑戰是評估下一代AI能力最重要的方式之一,基準測試固然有用,但往往無法捕捉研究中最困難的部分,包括維持長鏈推理、選擇正確抽象架構、處理問題陳述中的模糊性,以及產出經得起專家檢驗的論證。First Proof這類挑戰讓我們能在正確性難以立即驗證、且失敗模式具有啟發性的情境中,壓力測試模型能力。
OpenAI研究員James Lee說,OpenAI正在訓練一個新模型,主要目標是提升思考的嚴謹程度,希望模型能連續思考數小時,並對結論保持高度信心,當First Proof問題公布時,即成為理想的測試場域。
在測試過程中,OpenAI採取有限的人類監督。於訓練期間提示模型時,有時會建議其重新嘗試先前有效的策略;有時在收到專家回饋後,會要求模型擴充或澄清證明內容,以利驗證。
OpenAI已另外公開一份完整證明文件,收錄模型對10道題目的完整證明內容,並附上提示策略與測試過程說明。
熱門新聞

2026-02-20

2026-02-23

2026-02-23
2026-02-20

2026-02-23


2026-02-21