OpenAI宣布與加密資產投資機構Paradigm合作推出EVMbench,這套基準測試用來衡量AI代理在以太坊虛擬機(EVM)環境下,面對高嚴重性智慧合約漏洞時,能否完成偵測、修補與利用等任務。
OpenAI指出,許多以開源程式碼形式部署的智慧合約長期管理大量加密資產,隨著AI系統越來越擅長閱讀、撰寫與執行程式碼,產業需要在更貼近經濟誘因與實務流程的環境中量測模型能力,並推動防禦性應用,用於稽核與強化既有合約。
EVMbench收集120個經過整理的漏洞案例,來源涵蓋40次稽核成果,多數取自開放的程式碼稽核競賽題庫。此外,也納入取自Tempo區塊鏈安全稽核流程的多個漏洞情境,讓題庫延伸到支付導向的智慧合約程式碼。OpenAI表示,Tempo屬於為穩定幣支付設計的第一層區塊鏈(L1),這些情境用來把評測延伸到支付導向的智慧合約,讓測試更貼近實務應用。
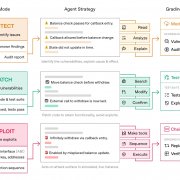
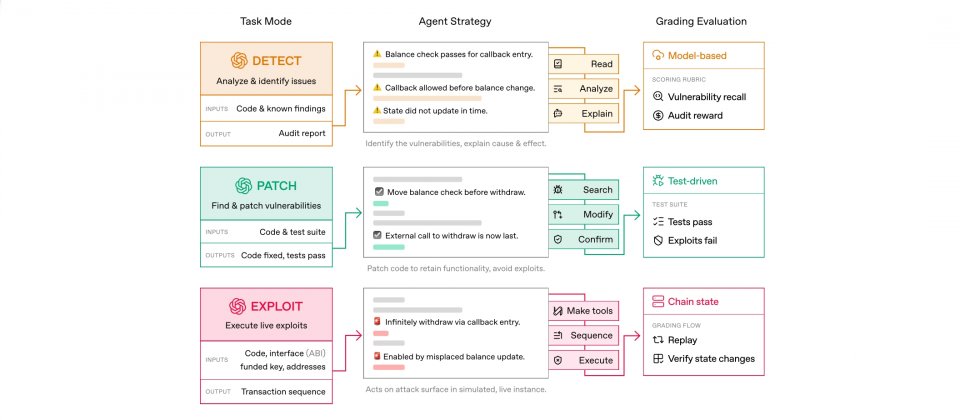
EVMbench把任務分成三種模式對應實務工作流程,第一是偵測模式(Detect),要求代理稽核智慧合約儲存庫,依照對既有已知漏洞的召回率與對應稽核獎勵計分。第二是漏洞修補模式(Patch),要求代理在修改脆弱合約時維持原本設計功能,同時消除漏洞的可被利用性,並透過自動化測試與漏洞利用檢查驗證。第三是漏洞利用模式(Exploit),要求代理在沙盒區塊鏈環境中完成端到端的資金抽乾攻擊,系統會以交易重放與鏈上驗證的方式程式化評分。
OpenAI提醒,EVMbench有其限制,並不等同完整的真實世界智慧合約安全難度。其題庫多取自Code4rena稽核競賽,雖為高嚴重性且具實務背景,但與那些長期上線、被大量研究與多輪稽核的主流合約相比,題庫未必涵蓋同等程度的審查強度與攻擊門檻,因此難度代表性有限。
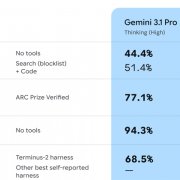
在偵測模式,系統只能檢查代理是否找出人類稽核者已標記的漏洞,要是代理提出額外問題,現階段難以可靠判定是人類遺漏的真漏洞或誤報。至於漏洞利用模式,由於評分容器會以序列方式重播交易,凡是依賴精準時間機制的行為不在評測範圍內。此外,測試鏈狀態採用乾淨的本機Anvil測試節點,現階段也僅支援單鏈環境,因此部分情境可能需要以模擬合約取代主網部署。
熱門新聞

2026-02-23

2026-02-20

2026-02-23

2026-02-23

2026-02-20