在JavaScript中要計算字串中的字元長度,應該怎麼做呢?字串物件的length特性? 結果是1,這看來是對的,那為什麼
結果是1,這看來是對的,那為什麼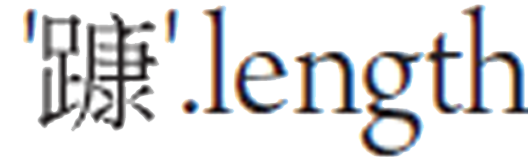 值不是1呢?
值不是1呢?
而當一個語言聲稱它支援Unicode時,開發者必須搞清楚裡面是怎麼支援!
UCS-2/UTF-16
不少開發者在介紹JavaSript時,都會談到它支援Unicode,不單是字串中可以撰寫Unicode字元,變數名稱也可以,有些開發者為了要強調這個特性,還會在撰寫文件或研討會中,使用這類程式碼來增加趣味性:
.png)
Unicode是個字元集,在談到一門語言支援Unicode時,開發者應該進一步想到它是怎麼個支援法,更具體來說,就是搞清楚它內部實現時採用何種編碼,字串相關語法與API又是怎麼處理,特別是對於一門走過長久歷史,至今仍存活的語言更應留意,以免寫出臭蟲。
JavaScript支援Unicode,不過嚴格說來,一開始支援的是UCS,而在執行時期,JavaScript字串最初採用的內部編碼是UCS-2,就現今來看,UCS-2大致等於UTF-16的子集,這是因為在過去,一開始有ISO/IEC與Unicode Consortium兩個團隊,都打算統一字元集,而ISO/IEC在1990年就先公布了第一套字元集的編碼方式UCS-2,裡面使用了兩個位元組來編碼字元。
字元集中每個字元會有個編號作為碼點(Code point),而UCS-2編碼是以兩個位元組為一個碼元(Code unit),最初的想法很單純,令碼點與碼元一對一對應,在編碼實作時,就可以簡化許多;後來,在1991年,ISO/IEC與Unicode團隊都認識到,世界不需要兩個不相容的字元集,因而決定合併,之後才發布了Unicode 1.0。
由於越來越多的字元納入Unicode字元集,超出碼點U+0000至U+FFFF可容納的範圍,因而原本UCS-2採用的兩個位元組,無法對應Unicode全部的字元碼點,後來在1996年公布了UTF-16,除了沿用UCS-2兩個位元組的編碼部份之外,也採用四個位元組來編碼更多的字元,也就是說,視字元是在哪個碼點範圍,對應的UTF-16編碼會是兩個位元組,或是四個位元組。
因此從時間點來看,JavaScript在1995創建之時,UTF-16尚未公布,只有UCS-2可以採用,後來才支援UTF-16,然而,有些曾經存在的API或語法,基於相容性而在行為上沒有改變,這意謂著,過去的JavaScript,若想處理碼點U+0000至U+FFFF以外的Unicode字元會是個麻煩。
字串以碼元為元素單位
一般而言,Unicode使用平面(Plane)作為編碼區段,每個平面擁有65536(也就是2的16次方)個碼點,U+0000至U+FFFF為基本多文種平面(Basic Multilingual Plane,BMP),包含了最常使用的字元,JavaScript在創建時採用的UCS-2,大致可以對應BMP字元,而且,碼點與碼元的關係為一對一,對於BMP字元來說,一個字元確實就是一個碼元,由於許多開發者處理的字元只會位於BMP,才會以為字串的length是指字元數量,而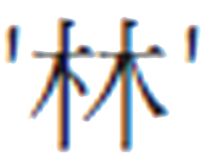 [0]是取得第一個字元。
[0]是取得第一個字元。
然而,JavaScript後來支援UTF-16,以便能處理BMP以外的字元,為了解決輸入法無法直接鍵入這類字元的問題,JavaScript以字元在UTF-16編碼時的高低位元組來表示,也就是使用兩個碼元。
例如, 的Unicode碼點為U+28117,無法直接使用既有的\uhhhh來表示,在ES5或早期版本中,字串必須以UTF-16兩個碼元撰寫為'\uD860\uDD17';不過在ES6,增加了\u{…}的表示法,可以直接撰寫'\u{28117}',兩種表示法可以並存,'\uD860\uDD17' === '\u{28117}'結果會是true。
的Unicode碼點為U+28117,無法直接使用既有的\uhhhh來表示,在ES5或早期版本中,字串必須以UTF-16兩個碼元撰寫為'\uD860\uDD17';不過在ES6,增加了\u{…}的表示法,可以直接撰寫'\u{28117}',兩種表示法可以並存,'\uD860\uDD17' === '\u{28117}'結果會是true。
然而,JavaScript早期在處理字串相關資訊時,是以碼元為處理單位,支援UTF-16後為了兼顧相容性,規格書中規定(https://bit.ly/2Xm8AyI),處理字串時,使用UTF-16碼元作為字串的元素(Element)單位,而不是把Unicode字元作為字串的一個元素。
因而ES5或早期版本的API或語法,在涉及字串的元素單位處理時,都是採用碼元,例如length就是指UTF-16碼元數量,而不是字元數量,這也就是何以.length的結果不是1而是2,因為,有兩個碼元\uD860與\uD17。
另外像是字串的charAt方法,或是[]語法可取得指定索引處的元素,也要注意元素是以碼元為單位,因此.charAt(0)方法或者是[0],取得的元素是碼元'\uD860',而不是Unicode字元。
ES6的Unicode支援
從碼元及\uhhhh\uhhhh表示法來看,JavaScript中的\uhhhh寫法,嚴格來說,是碼元表示方式,只不過在BMP範圍時,碼元表示方式等於碼點表示方式;ES6的\u{…}表示法其實也可以用來指定BMP範圍內的字元,如果環境支援ES6,在指定Unicode碼點時,建議使用\u{…}來取代\uhhhh。
ES6新增一些有關字串的API與語法,可以正確地處理BMP以外的字元,例如,ES6為字串新增的codePointAt方法,可以取得指定索引處的「字元」碼點,而String.fromCodePoint函式,可以指定碼點取得字元,如果字元是在BMP以外,兩者的組合可以用來實作自己的charAt,正確地取得字元,而不是碼元:
function charAt(text, idx) {
return String.fromCodePoint(text.codePointAt(idx));
}ES6有個Array.from函式,可以接受字串並傳回陣列,陣列元素會是字串中各個「字元」,如果字串包含BMP以外的字元,可以使用Array.from(text).length正確地計算字元數量,如果想要用for迴圈結合索引來走訪每個「字元」,也可以透過Array.from取得字元陣列後走訪,或者是使用for...of語法,它可以正確地走訪字串的「字元」。
使用規則表示式時,也必須留意比對的元素預設是碼元,例如,/\uD860/.test('\uD860\uDD17')的結果會是true,因為確實比對到碼元\uD860,如果開發者指定的\uD860其實是碼點,可以開啟u旗標(Flag),/\uD860/u.test('\uD860\uDD17')的結果會是false,/\u{28117}/u.test('\uD860\uDD17')才會是true。
支援Unicode是指什麼?
當一個語言聲稱它支援Unicode時,開發者是否搞清楚是什麼意思呢?許多開發者甚至搞不清楚Unicode與UTF-8、UTF-16、UTF-32等的關係!
實際上,問題並不是只發生在JavaScript,Java中也會發生。例如,.png) 的結果也是2,其實Java在API文件上有明確說明,length方法傳回的是碼元數量(https://bit.ly/2Imep78)。
的結果也是2,其實Java在API文件上有明確說明,length方法傳回的是碼元數量(https://bit.ly/2Imep78)。
你手邊使用的程式語言支援Unicode嗎?Python 3中的.png) 是多少呢?Go語言中
是多少呢?Go語言中.png) 是表示什麼呢?想取得字串的字元數量,又該怎麼做呢?Unicode確實是複雜的,然而與其逃避學習、希望能僥倖過關,不如好好認識它,別再以為支援Unicode就沒事了!
是表示什麼呢?想取得字串的字元數量,又該怎麼做呢?Unicode確實是複雜的,然而與其逃避學習、希望能僥倖過關,不如好好認識它,別再以為支援Unicode就沒事了!
專欄作者

因在網路上經營「良葛格學習筆記」(openhome.cc)而聞名,曾任昇陽教育訓練中心技術顧問、甲骨文教育訓練中心授權講師,目前為自由工作者,專長為技術寫作、翻譯與教育訓練。喜好研究程式語言、框架、社群,從中學習設計、典範及文化。閒暇之餘記錄所學,技術文件涵蓋C/C++、Java、Ruby/Rails、Python、JavaScript、Haskell等多個領域。
熱門新聞

2026-02-16

2026-02-20


2026-02-17



2026-02-16

2026-02-16