在Hadoop平臺中,核心用途是儲存空間的資源管理,以及記憶體空間和程式排程的安排。透過分散式架構的HDFS檔案系統、搭配可分散運算的MapReduce程式演算方法,可以將多臺一般商用等級的伺服器組合成分散式的運算和儲存叢集,來提供巨量資料的儲存和處理能力。要了解Hadoop,首先必須先了解MapReduce和HDFS的運作原理。
MapReduce是一種解決問題的程式開發模式,開發人員需要先分析待處理問題的解決流程,找出資料可以平行處理的部分,也就是那些能夠被切成小段分開來處理的資料,再將這些能夠採用平行處理的需求寫成Map程式。
然後就可以使用大量伺服器來執行Map程式,並將待處理的龐大資料切割成很多的小份資料,由每臺伺服器分別執行Map程式來處理分配到的那一小段資料,接著再將每一個Map程式分析出來的結果,透過Reduce程式進行合併,最後則彙整出完整的結果。
先拆解任務,分工處理再彙總結果
MapReduce的運作方式就像是大家熟知的全國性選舉開票,中選會事先將開票任務分配給各地投票所,每個投票所各自負責所屬的票箱,完成計票作業後將開票結果回報給中選會,由中選會統一彙整出全國的開票結果,這樣就不需要把幾百萬張選票都集中到中選會處理,而是透過分散處理的方式來加快開票作業。
開票任務就像是Map程式,每一個投票所都執行相同的開票作業程序,也只負責處理少量的局部資料,而Reduce程式就是彙總票數的工作。
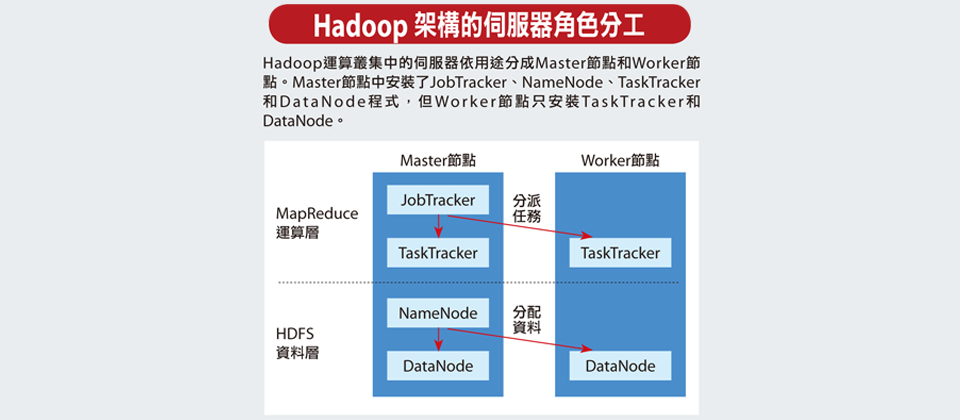
在Hadoop運算叢集架構中,這些伺服器依據用途可分成Master節點和Worker節點,Master負責分配任務,而Worker負責執行任務,如負責分派任務的中選會,角色就像是Master節點。
另外在系統的運作架構上,最簡單的Hadoop架構,可以分成上層的MapReduce運算層以及下層的HDFS資料層。
在Master節點的伺服器中會執行兩套程式,一個是負責安排MapReduce運算層任務的JobTracker,以及負責管理HDFS資料層的NameNode程式。而在Worker節點的伺服器中也有兩套程式,接受JobTracker指揮,負責執行運算層任務的是TaskTracker程式,而與NameNode對應的則是DataNode程式,負責執行資料讀寫動作,以及執行NameNode的副本策略。
在MapReduce運算層上,擔任Master節點的伺服器負責分配運算任務, Master節點上的JobTracker程式會將 Map和Reduce程式的執行工作,指派給Worker伺服器上的TaskTracker程式,由TaskTracker負責執行Map和Reduce工作,並將運算結果回覆給Master節點上的JobTracker。
在HDFS資料層上,NameNode負責管理和維護HDFS的名稱空間、並且控制檔案的任何讀寫動作,同時NameNode會將要處理的資料切割成一個個檔案區塊(Block),每個區塊是64MB,例如1GB的資料就會切割成16個檔案區塊。NameNode還會決定每一份檔案區塊要建立幾個副本,一般來說,一個檔案區塊總共會複製成3份,並且會分散儲存到3個不同Worker伺服器的DataNode程式中管理,只要其中任何一份檔案區塊遺失或損壞,NameNode會自動尋找位於其他DataNode上的副本來回復,維持3份的副本策略。
在一套Hadoop叢集中,分配MapReduce任務的JobTracker只有1個,而TaskTracker可以有很多個。同樣地,負責管理HDFS檔案系統的NameNode也只有一個,和JobTracker同樣位於Master節點中,而DataNode可以有很多個。
不過,Master節點中除了有JobTracker和NameNode以外,也會有TaskTracker和DataNode程式,也就是說Master節點的伺服器,也可以在本地端扮演Worker角色的工作。
在部署上,因為Hadoop採用Java開發,所以Master伺服器除了安裝作業系統如Linux之外,還要安裝Java執行環境,然後再安裝Master需要的程式,包括了NameNode、JobTracker和DataNode與TaskTracker。而在Worker伺服器上,則只需安裝Linux、Java環境、DataNode和TaskTracker。
[圖表]MapReduce執行示意圖(點此看圖)
相關報導請參考「巨量資料的頭號救星:Hadoop」
熱門新聞

2026-02-26

")
2026-02-27

2026-02-27

2026-02-27

2026-02-27
-P29-link.png){kind=link}
2026-02-26