
Apple
蘋果上周展示最新視覺模型名為Depth Pro,能在不使用相機影像情況下,將2D圖片轉化成3D圖。
Depth Pro是一種零樣本單眼深度估計(monocular depth estimation)的基礎模型,能為高解析度深度圖加入細節銳利度,成為高品質3D圖像。使用單眼深度估計技術的好處是可以應用於任何類型圖片,且可零樣本訓練出具有可量測的深度,因而能準確重製物件形狀、場景布局,用在地圖上,則可重製具有絕對尺度值的深度圖(depth map),而且不需提供相機內部參數metadata(像是焦距)給模型。簡而言之,這種AI模型預測方法不需要感測器數據即可準確預測,也可用任何單一圖片來合成想要的圖片。
在研究方法上,研究團隊使用了2個視覺Transformer(vision transformer,ViT)模型,包括一個影像補片編碼器(patch encoder)和一個影像編碼器(image encoder),前者負責將圖片切成小補片,完成特徵提取、推論圖片像素的深度,後者以上下文(context)訊息提升深度估計的準確性。模型完成後的後處理方面,團隊以真實和合成資料集來提升量測準確性以及物件邊界跟蹤(boundary tracing)能力,輔以另一個影像編碼器模型提供的焦距估計,藉此優化3D圖片生成結果。
在邊界準確度測試上,Depth Pro超過所有現有模型,像是Marigold和PatchFusion。該模型另一優點是速度快,在實測中可以在一臺使用一顆Nvidia V100 GPU上0.3秒內生成2.25-megapixel的深度圖。
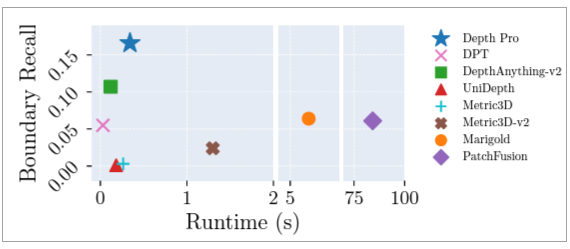
連同論文,蘋果並將Depth Pro模型程式碼和加權值等公布在GitHub上。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23