
AI模型以產生幻覺及誤導性的答案為人詬病,Google上周公開最新模型DataGemma,號稱大幅降低幻覺問題。
Google表示,DataGemma是第一個將大型語言模型(LLM)和來自Google開源知識圖譜(knowledge graph)Data Commons的各種現實世界資料連結的案例,目的在藉由以現實世界的統計資訊構連LLM,以減少AI幻覺。
目前Google已經在Hugging Face公布DataGemma模型程式碼及其他資訊。
Data Commons是Google建立且開源的知識圖譜,資料源是值得信賴的組織,像是聯合國、世界衛生組織、美國疾管局、和美國人口普查局等。Data Commons涵括健康、經濟、人口和環境等多種主題,包含超過2400億豐富資料點,統計變項橫跨數萬種。Data Commons使用者可以Google開發的AI自然語言介面查詢,研究人員可以查詢像是非洲電力普及率增長最大的國家,或是收入和美國各郡糖尿病關係之類的議題。
針對Data Commons資料源,Google利用二種方法提升DataGemma的理解能力,以更貼近事實。一是檢索交錯生成(Retrieval-Interleaved Generation,RIG),二是檢索增強生成(Retrieval-Augmented Generation,RAG)。第一種方式中,當用戶以DataGemma生成回應,它會從Data Commons尋找統計資料並取得答案。Google說,RIG方法並不新,但特別用在DataGemma框架的作法卻是唯一。
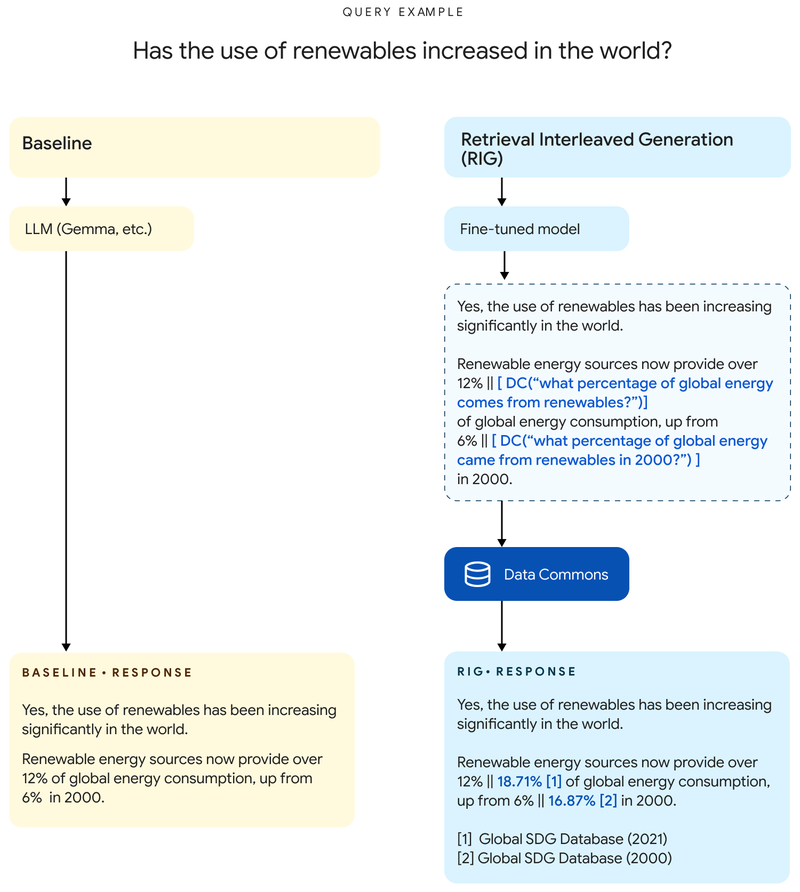
圖片來源/Google
第二種方式中,當用戶查詢DataGemma時,它會運用Gemini 1.5長脈絡空間,先從Data Commons取得上下文資訊,再生成回應,藉此減少幻覺、提升回應品質。
Google之前已利用開源的Gemma和Gemma 2為基礎,使用RIG和RAG微調出變種版本,而這次則是以Gemma 2為基礎,再以RIG及RAG方法,分別生成DataGemma 2個27B版本變種,現已分別在Hugging Face平臺公開。Google計畫持續改善方法,最後會將這些方法學整合到開源的輕量模型Gemma,以及Gemini家族模型。一開始將局部開放給少數人試用,再階段性逐步擴大開放。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23