微軟Azure認知服務中的健康保健用文字分析服務,現在可以從7種語言的非結構化文字,擷取出有意義的分析,並且經過進一步處理,用於臨床決策支援上。微軟提到,全面支援多語言非結構化生物醫學資料分析,是自然語言服務中的創舉。
除了英文,現在健康保健用文字分析功能還支援西班牙語、德語、法語、義大利語、葡萄牙語和希伯來語,這些語言支援,使得全球更多衛生組織,得以分析多語言非結構化臨床筆記。
微軟提到,當前自然語言處理服務的挑戰之一,就是要跨出英文的限制,而困難之處是要找到多種語言資料,來訓練人工智慧模型,並針對特定國家進行微調,畢竟語法在不同語言之間是不同的,特別是非拉丁語言。
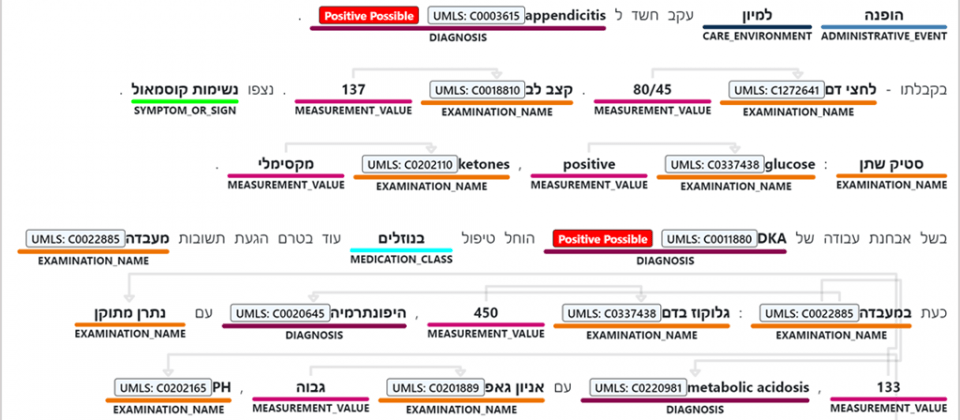
不同國家所面對的健康保健挑戰不同,像是書面文字是口語、醫學術語和該國慣用速記方法的混合體,微軟的合作研究對象之一Leumit Health Services,其所提供的病歷,通常混合希伯來語和英語單詞,而巴西等地因為缺乏互通或是資料收集標準,導致出現許多非結構化資料。藉由微軟的AI技術,將可使這些病歷資料更為可用。
健康保健用文字分析功能使用自然語言處理技術,來偵測和辨識文字中的醫學術語,並且進行分類後,與標準臨床編碼系統關聯,以推論資料中的語意關係和斷言,進而實現更深入的脈絡理解,微軟表示,透過整合非結構化資料和結構化資料,能夠揭露關鍵分析、辨識風險、自動填寫表格和配對臨床實驗者等,使更多潛在健康保健使用案例得以實現。
過去多數健康保健相關技術都僅限英文,阻礙了非英語系國家的採用,新的自然語言處理技術可以彌補語言造成的健康平等差距。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23
Advertisement