Openai推出了一套工具和環境Safety Gym,幫助他們進行受限增強學習演算法。Safety Gym可用來評估增強學習代理人,在訓練時尊重安全約束的進展。Openai提到,要將深度學習應用在現實世界中,無論是實際的機器人還是網路技術,人工智慧學習時都需要有安全演算法,讓他們不需要實際經歷事故,就可以學會避免危險發生。
增強學習是一個透過探索環境學習最佳行為的方法,需要透過代理人不停地試錯來運作,在代理人嘗試一些行為之後,判斷有效與無效的行為,增加良好行為的可行性,並減少無效行為的可能性,以達到最終設定的目標。但Openai提到,探索本身就是危險的事,代理人可能嘗試了無法接受的危險行為。
而這衍生出安全探索(Safe Exploration)的議題,Openai表示,安全探索的具體作法便是受限(Constrained)增強學習,受限增強學習與普通增強學習相似,只是代理人除了要最大化獎勵函式之外,環境還需要增加了成本函式來限制代理人,像是要自動駕駛汽車從A點開到B點,受限增強學習能夠約束自動駕駛行為以符合交通規則。
Openai表示,普通增強學習的一大問題是,代理人的最終行為,都由獎勵函式來描述,但是從根本來說,獎勵設計非常困難,因為需要權衡的任務效能以及安全性要求,是兩個互相競爭目標,但是在受限增強學習則不需要做出取捨,而是選擇結果,由演算法算出人類想要的結果。
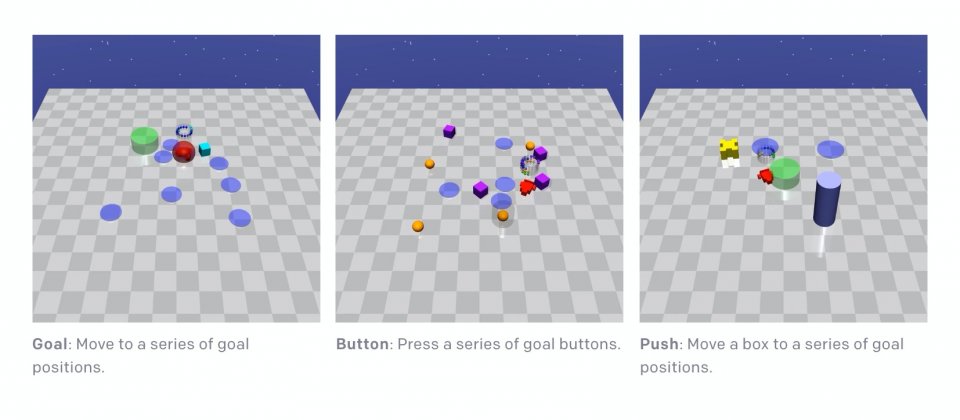
為了要研究受限增強學習,Openai推出了一系列稱為Safety Gym的工具和環境,相較於現存的受限增強學習的環境,Safety Gym提供更豐富的學習環境,具有更大的難度以及複雜度範圍。在Safety Gym中,機器人必須要在混亂的環境中達成任務,預設有Point、Car和Doggo(下圖)三種機器人,以及達成目標、按鈕和推三種預設主要任務。

作為開放給社群的研究基礎,Openai在Safety Gym基準套件上測試了普通增強學習以及受限增強學習演算法,Openai提到,他們初步的結果顯示,Safety Gym可用來進行廣泛困難度的增強學習演算法測試。
(下圖)PPO和TRPO為普通的增強學習演算法,同時Openai也為這兩種演算法加入應用拉格朗日力(Lagrangian)的版本,作為安全性懲罰成本以限制其最佳化,而CPO(Constrained Policy Optimization,CPO)則為受限的增強學習。
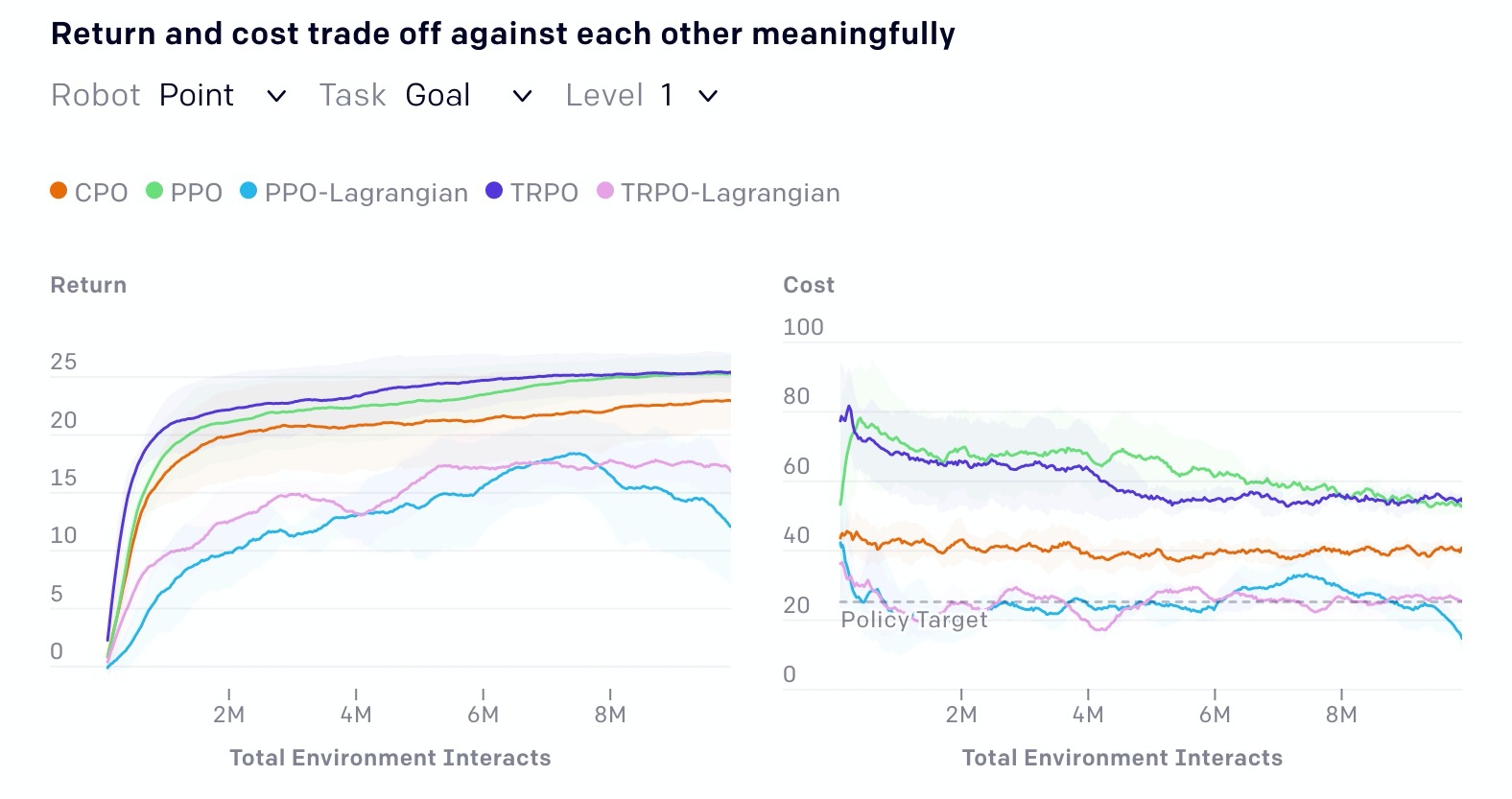
Openai意外發現,在Safety Gym環境中,應用拉格朗日力(Lagrangian)方法的演算法,竟比CPO的表現還要好上許多,而這推翻了過去的研究結果。為了幫助研究人員可以快速上手實驗,Openai釋出了實驗所用的代理人實作。
接下來,Openai提到,他們會改進受限增強學習,並與其他問題設定和安全技術結合,Openai提到,他們希望Safety Gym除了能夠量化精確度和效能之外,未來還能量化安全性,如此政府便可能將這套評估方案,用來建立安全標準。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-02-26

2026-03-02
%3A \">圖片來源/Novee</a>")
2026-03-02
