
圖片來源:
AWS
AWS近日利用半監督式學習方法,來提升語音辨識系統效能,特別是在吵雜的環境中,AWS表示,雖然現在深度神經網路能夠準確地辨識大量詞彙的對話,訓練工作還是需要長達數千個小時的標註資料,收集這些龐大資料不但耗時且成本昂貴,因此,過去AWS的科學家不斷在研究能夠在人工干預最小化的情況下,讓Alexa學習正確辨識語音的技術,大致上分為非監督式和半監督式學習。
AWS採用半監督式學習方法,首先,用800小時標註過的語音資料,訓練了一套語音辨識模型,該辨識模型擔任老師的角色,並用該模型「輕微地」標記另外尚未標記的7,200小時語音資料,接著,AWS手動在一些數據集中加入雜訊,再將這些帶有雜訊的資料集和被第一個模型標記的資料,一起用來訓練第二個辨識模型,而這個模型則是擔任學生的角色,藉由這樣的設計,AWS期望創在學生模型是用具有噪音的資料訓練,而老師模型則是乾淨的語音資料,如此一來,就能改善語音辨識系統處理噪音的穩定度。
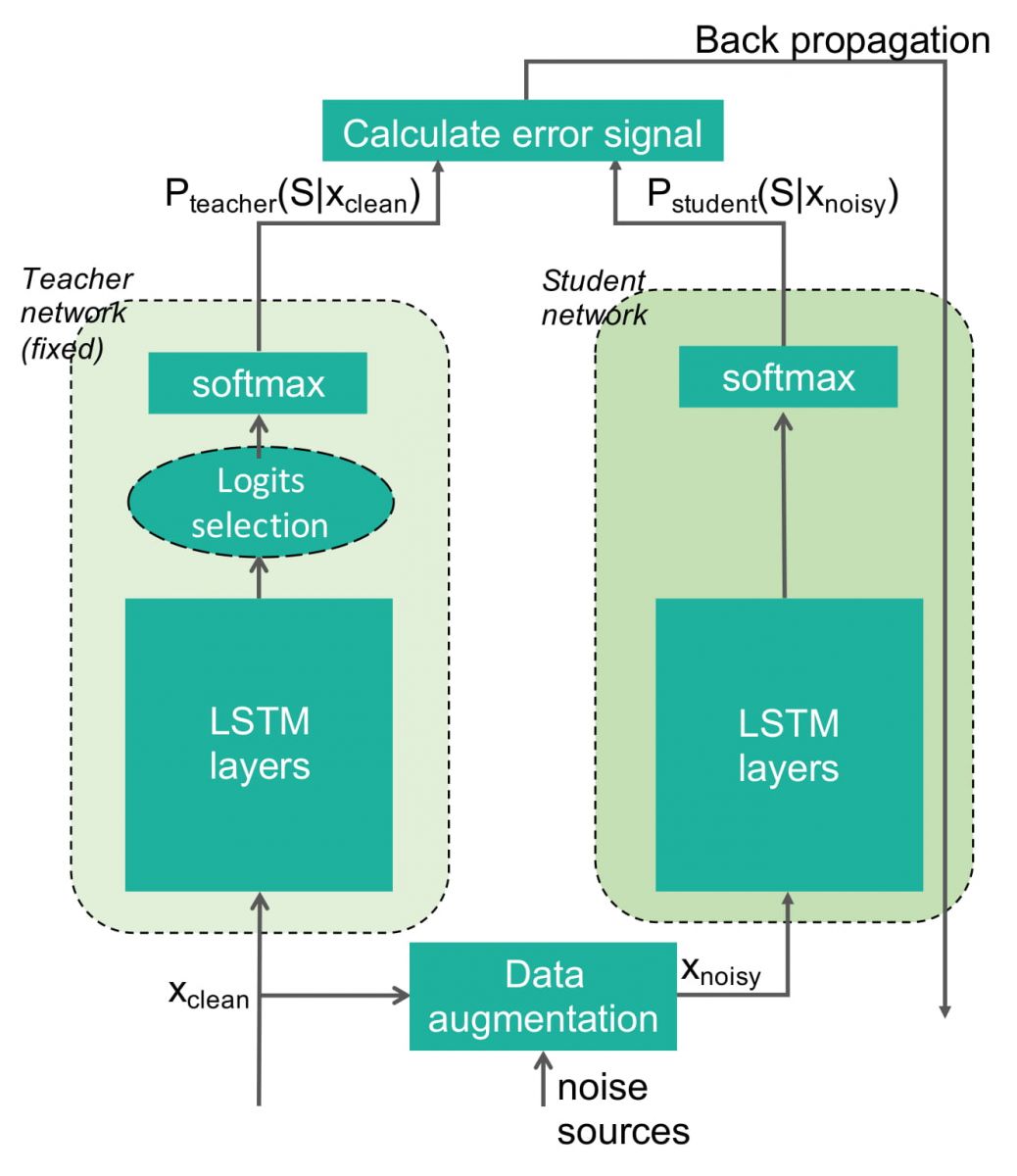
圖片來源:AWS
在一項測試實驗中,AWS同時播放錄製的語音和用音響播放多媒體聲音,相比只有用無噪音和標註資料訓練的語音辨識模型,AWS半監督式的辨識模型錯誤率減少了20%。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23
Advertisement