圖片來源:
臉書
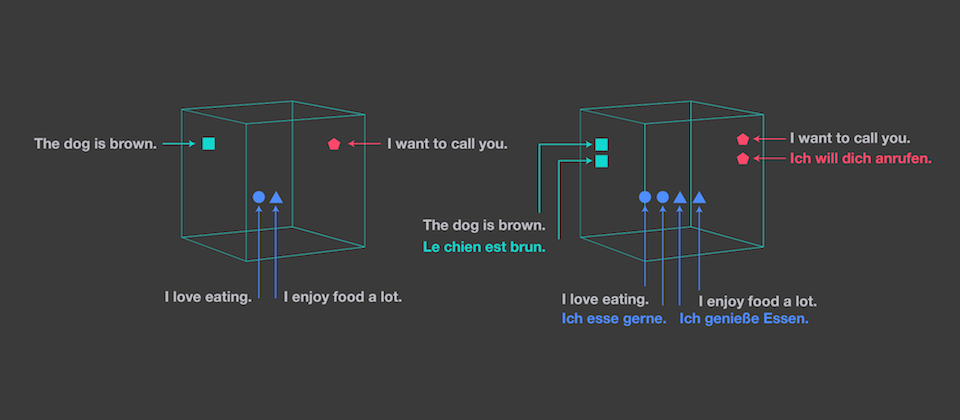
為了加速自然語言處理模型可以應用於多種不同的語言,臉書開源釋出跨語言句子向量計算工具LASER(Language-Agnostic SEntence Representations),該工具支援超過90種語言,讓自然語言處理模型可以簡單地轉換到另一個語言上,包含那些訓練資料較少的語言,像是卡拜爾語、維吾爾族語,甚至連方言也包含在內,特別的是,LASER是將所有語言嵌入到一個共同向量空間,而非每個語言有獨立的模型。
LASER工具會將每個句子不同語言的資料,一併匯入高維度的空間中,目的就是讓相同意思的句子能夠在同一個鄰近區域,輸出的資料可以被視為一個在語義向量空間中通用的語言,臉書研究團隊發現,在向量空間中的距離,與句子的語義相近程度有強烈的相互關聯。
臉書採用的方法即是透過目前的神經機器翻譯技術Seq2seq,將所有語言輸入至5層的雙向長短時記憶(bidirectional LSTM)網路,再用一個共同的解碼器產生語言的輸出結果,不同的是,臉書是用1,024維度固定大小的向量,來表示輸入的句子,如此一來,能夠比較句子的表示法並將其直接送入分類器中。
臉書表示,LASER是第一個可以在一個模型中,處理多種語言的函式庫,該研究成果能夠協助臉書開發自然語言處理相關的功能,像是在一個語言中,將電影評價分為正評和負評,再快速部署到其他100多種語言。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23
Advertisement