
圖片來源:
Google旗下的機器學習系統TensorFlow自2015年開源釋出後,便陸續擴增與加強系統的功能,日前Google又開源釋出TensorFlow系統最新版本的圖片標題工具Show and Tell,加強了圖片標題工具的電腦視覺元件,能夠更準確地描述圖片的物件和背景細節。
Google在2014年時,訓練機器學習系統能夠自動產生標題,來準確地描述圖片,當時的圖片辨識率達89.6%,在2015年時,Google又增進了電腦視覺模型的圖片辨識率為91.8%,而到了現在新版的Show and Tell工具,採用新一代電腦視覺模型,讓Show and Tell工具的圖片辨識率高達93.9%,能夠辨識圖片中不同的物件,以產生更準確和更多細節的描述。
除了加強標題工具的圖片辨識率外,Google也藉由真人產生的圖片標題,訓練標題工具中的視覺和語言元件,而這也是圖片標題工具用來轉換圖片為資訊的重要元件。根據Google,視覺和語言元件在經過訓練後,能夠正確地描述圖片中物件的顏色。

(圖片來源/Google)
另外,Google表示,Show and Tell工具經過成千上萬張由真人下標題的圖片訓練,所以當圖片標題工具判斷一張圖片與以前訓練用的圖片相似時,就會經常重複使用人類所寫下的圖片標題。甚至,Show and Tell工具除了接受閱讀真人標記的圖片標題的訓練外,沒有再接受其他額外的語言訓練,也能使用自然的英語詞組來描述圖片的人事物和情景。
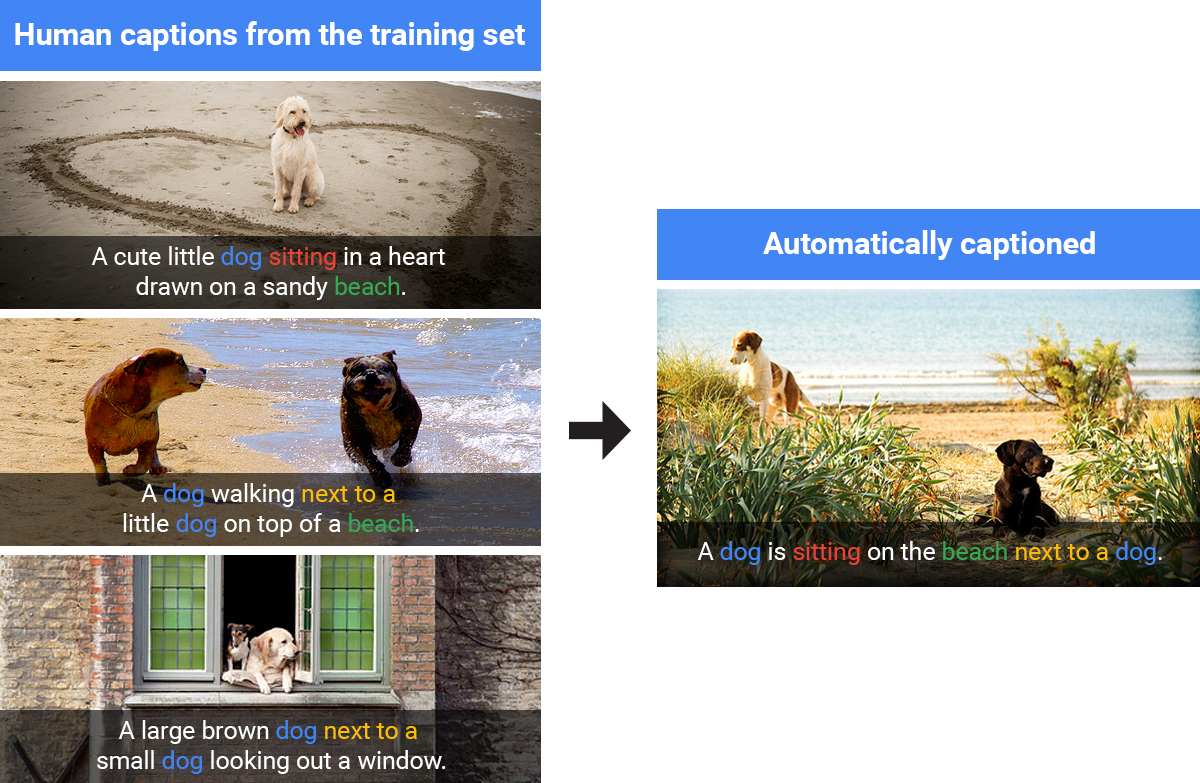
(圖片來源/Google)
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-02
%3A \">圖片來源/Novee</a>")
2026-03-02
Advertisement