
對IBM的關聯式資料庫DB2來說,今年很特別,從第一個版本發表至今已經有25年,從1970年關聯式資料模型的提出、SQL語言與查詢最佳化技術的發展,都與IBM有關,之後這些理論與計畫正式實作成商業化產品後就成了DB2。
DB2近期版本功能的重大突破
IBM的關聯式資料庫DB2固守既有的高可用性與延展性的特色之餘,已決心積極向新的應用系統發展,例如終於推出對XML的原生支援,即是一例。
DB2當前版本的2大特色:pureXML
XML能與關聯式資料庫並存
資料庫在存取XML困難的地方在於:一般資料庫系統都是關聯式資料庫,而XML文件格式則是階層結構,兩者並無法直接儲存或者讀取。而DB2當前版本對XML文件相容性更加提升,使用者可以直接查詢與編輯XML文件內容。
DB2當前版本的2大特色:自動化管理
延續自動備援,資料表分割具彈性
IBM DB2有高可用的復原機制,採用HADR機制,能建立備用主機以提升系統可靠度,並提供新的表單載入/卸載功能,達到資料表彈性調動的效果。
25年來DB2發展的關鍵技術
DB2與關聯式資料庫的深厚淵源
關聯式資料庫管理系統這項技術發展已將近40年,DB2承接了IBM對於關聯式資料庫的理論基礎,同時也發展出效能調校、提升系統可用性與延展性的架構。
撰文⊙李宗翰、林郁翔、林柏凱 攝影⊙楊易達、賴基能DB2近期版本功能的重大突破
對IBM的關聯式資料庫DB2來說,今年很特別,從第一個版本發表至今已經有25年,它不但代表DB2經歷了長期的發展,也同時代表關聯式資料庫在企業已經應用了25年之久。
從1970年關聯式資料模型的提出、SQL語言與查詢最佳化技術的發展,都與IBM有關,之後這些理論與計畫正式實作成商業化產品後就成了DB2。
DB2 8.x版開始第一階段大換血的指標:
DB2第8版是在2003年3月發布的。長期參與DB2研發的IBM矽谷實驗室
查詢技術部DB2 z/OS資深研發經理傅毓勤認為,在這個版本之後,IBM在新功能的改進方向,開始變得比較多元。
他以持平的角度重新看待這段歷程。他認為IBM過去的確低估了個人電腦與分散式平臺的發展,之後又一度矯枉過正地追隨企業規模最小化,將主機系統移植到所謂的開放系統上的潮流。
90年代有段時期,IBM錯過了發展良機,也是傅毓勤感到很可惜的。當時他們仍專注在可用性的提升,並未及時發展新的應用系統與擴充SQL功能。
到了第8版,因為當時大部分企業忙著應付Y2K危機,因此IBM也得空,順勢延後了這個版本的開發時間。趁這段3、4年的時間,DB2的開發團隊從系統的本質上開始改變,成果似乎是令人滿意的。傅毓勤特別用Quantum Leap(大躍進)來比喻SQL的功能改進。
對當時的DB2來說,這樣的變革相當迫切。IBM內部曾經評估過MainFrame平臺與分散式平臺之間的功能落差,兩個平臺上共通的功能最多,其次是分散式平臺獨有的,但MainFrame獨有的部分顯然落後,於是他們得把主機端的功能補上來,平衡在不同平臺上的差異。於是到了DB2 8新的語言也有了延伸。
另一件重大的工作是讓DB2支援64位元運算,而且需徹底打破2GB記憶體空間定址對系統交易量處理所造成的限制。傅毓勤說,第8版時,這部分修改的進度是30%至40%,到了DB2 9.x版又繼續調整30%,預計在下個版本全部調整完畢,屆時就是完全64位元化。
這是一場針對DB2的大型開刀手術。傅毓勤說,系統裡面的指標原先都是4個Bytes,全部需改成8個Bytes;就算忽略改寫程式碼的工作量,系統修改後,接著還要執行測試,避免程式臭蟲隱藏其中,凡此種種,這些開發、測試、除錯的規模都相當可觀。
命名空間上允許使用更大量的字元,也是一個符合時代潮流的系統所必需。DB2過去只允許用8個字元來命名,現在必須能夠開放使用更多字元來表達,近幾年來,物件命名的方式已經改成以提升可讀性為主,因此他們需要做到能容納128個位元的命名。但這樣一改,既有資料表、索引、函式等資料庫物件的名稱,也都受影響,難度也很大。
最後一項改造的重點是最佳化,也是傅毓勤負責的任務當中最關鍵的,他必須設法調整DB2的「體質」,以便這樣的基礎架構能夠適應下個十年的複雜性增長。也就是在那時候,DB2開始發展所謂的自主運算(Autonomic Computing),事實上這是一種專門針對資料庫系統效能調校的機制,目的是讓系統最佳化越來越聰明。
在8.0的可用性、延展性與效能的發展上,DB2的資料分割最多可以切成4096個,而且可以隨時加入和輪流調換(Rotate),此外,資料表空間上的分割與資料叢集等2種功能原本是合在一起的,現在開始能各自獨立使用,彼此不相關。此外,新支援了多列資料的插入(Multi-row fetch& insert),而且最佳化的做法也加以改良,例如資料表查詢的結果實際儲存起來(Materialized Query Tables),預先儲存某些Select敘述的執行結果,讓其他SQL指令可以直接取用,提升執行速度。系統可取用的記憶體空間,也將透過壓縮取得更多,而且可以將資料頁所使用的共用緩衝區,固定在實際的儲存設備上。
|
|
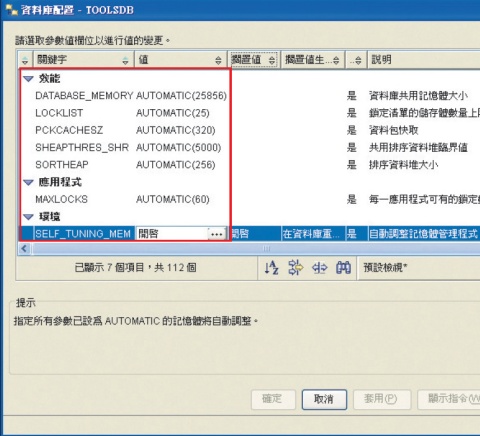
| 如果想讓資料庫開啟記憶體自動調校機制,你可以調整相關的參數。系統預設是啟用的。 |
9.x版著重在程式開發強化與簡化資料庫管理
9.0版是在2007年3月後發布的,它的代號叫做Viper,IBM繼續在可用性、可靠度、延展性等方面的發展之餘,最大的改變是原生支援XML(即所謂的pureXML)和提供記憶體自動調校的能力──Self-Tuning Memory Manager(STMM)。此外,DB2也開始支援全文檢索與空間與地理資料。
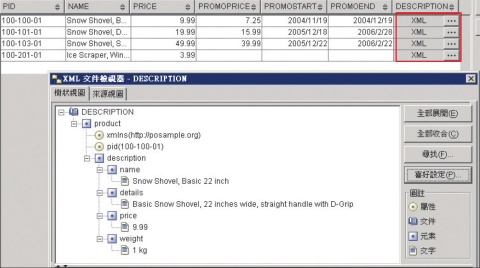
傅毓勤很自豪地說,現在業界對原生XML支援做得最好的是DB2 LUW和DB2 Mainframe,兩種平臺的功能與價值幾乎是相同的。從這個版本之後,XML在DB2當中是一個原生的資料型別,從上到下每一個元件都認識這個型別。你可以在裡面存XML的資料,或是建立一個資料表,在上面建立XML的欄位,再將資料存在裡面,也可以在XML欄位上建立索引,並且查詢裡面的XML 路徑的表示式。系統的備份與還原工具也都認得這種型別。
資料庫記憶體的自動調校,是DB2 9.1版之後的一大突破,它可以自動觀察系統目前執行的交易量,然後經過反覆調整、學習,產生最適合的設定。IBM根據依照自己的測試數據表示,啟動STMM後,能夠處理的交易量略微勝過有經驗的DBA人員調校。IBM軟體產品處資訊工程顧問莊濟誠說,如果是由「人」來觀察、調整可能會有誤差,但DB2是透過內建的監控機制,觀察記憶體使用的比例、命中率大小等狀況,同時透過一些規則來加以判斷,在記憶體裡面執行一些運算和比較,藉以去評估某幾個參數調整後,是否會帶來好的成效。
莊濟誠說,啟動自動記憶體調校後,從開始執行到成熟期,一般來說大約0.5~1小時,就可以收集到足夠的資訊來了解交易量的狀況,然後套用最佳化設定值。
啟動STMM也很簡單,只要資料庫系統管理人員修改系統設定參數,將SELF_TUNING_MEM設為On、DATABASE_MEMORY等6個參數設成Automatic,DB2就開始調整,如果自動調校到某個程度的成效很好、不需再調,管理者可以將這些設定關掉,就會鎖定在那個當下所調整的數值。文⊙李宗翰
|
|
| 企業可以在DB2 9.x 版上建立包含XML 資料型別欄位的資料表,如果需要檢視XML的資料內容,只要點選⋯的按鈕就可以瀏覽內容。 |
|
DB2 X功能搶先大公開 |
| DB2 9.5的下個版本,目前暫名為DB2 X(也是羅馬數字10的意思),傅毓勤表示,主要發展有4個方向︰繼續完成在64位元運算環境上的支援、處理器占用量能夠再減少、支援更多資料庫線上變更的處理形態,以及進一步符合資訊安全與法規遵循上的要求。
對64位元平臺中的記憶體邏輯定址空間的支援,DB2已經做到一部分,但在Virtual Storage上還有一些未完成,傅毓勤表示,下一版計畫調整完畢。 在效能的提升上,IBM想繼續減少在處理器資源占用量,在9.0的相容模式和使用模式下,已完成至一定程度,到了X,預計再比先前版本再降低幾倍的運算量。 可用性上,DB2預計讓資料庫更能夠操作線上變更作業,例如強化線上重整(online REORG)的使用性和效能,同時允許在線上調整綱要(online schema change)時,也能使用ALTER指令和線上重整,並且可以修改更多的屬性。 DB2 X也預計推出輔助稽核、數值加上遮罩(Allow masking of value),以及更細緻的權限控管功能,以落實資料保留與機敏資料保護,這主要是為了因應企業資安和法規遵循的需求。 以查詢為例,目前只能針對檢索現在的資料,未來將加入「As of」的機制,利用DB2幫你記錄這資料在某時受存取的狀態,日後可以指定時間點來加以查詢,有點類似版本控制的概念。 在權限控管上,DB2 8時,雖然能應用所謂的多種安全層級(Multilevel security),限制到只允許使用者存取資料表當中的某幾個欄位;到了DB2 X,將從每筆記錄的層級,再發展至Cell Level。管理權限也將更明確,將系統管理者需要的資料存取權與安全管理者的監控權加以分開。文⊙李宗翰 |
XML能與關聯式資料庫並存
XML(Extensible Markup Language,可延伸標記語言)是一種文件格式,人們可以很方便的去閱讀,同時電腦程式也可以辨識的格式和語法。XML有點像改良的HTML(HyperText Markup Language,超文字標示語言)。在標記語言中,使用標籤來標注文件內容,傳統HTML的標籤是給瀏覽器讀取,告訴瀏覽器文字大小、換行、表格或者編排資訊等,並不能傳達資料的內容。而XML的標籤是可以含有內容的,也就是除了像HTML含有標記資訊之外,本身還包含資料的內容。所以XML在某種層面上也是一種資料庫:階層式資料庫。因此它成了資料傳輸與交換最普及的文件格式。
資料庫在存取XML上有什麼樣的困難?困難的地方在於:一般資料庫系統都是關聯式資料庫,而XML文件格式則是階層結構,兩者並無法直接儲存或者讀取。
過去靠CLOB及Shredding即可支援XML,但是效果不彰
IBM DB2自7版開始,便能夠存取XML檔案格式,不過要將原本階層結構的XML文件,儲存於以表格為基礎的關聯式資料庫中,是沒辦法做到的,所以當時DB2採用兩種方式來存取XML檔案:一種是將整份XML文件以大型物件(Large Object)的方式儲存於表格中,另一種則是將XML文件拆解成表格欄位。
第一種方法將整份XML文件,以大型物件的方式儲存於表格的CLOB(Character Large Object),或者Long VARCHAR欄位中。對XML整份文件的存入與取出相當快速,但是對資料庫來說,在欄位中的檔案就是一組文字字串,並不具備XML結構的特性,所以在搜尋或讀取XML的部分資料時,必須對文件加以解析(Parsing),速度會慢上許多。必須仰賴外建的索引輔助查詢,才能增加查詢速度。
另一種方法將XML拆解成表格欄位,這種方法通常稱為Shredding,就是將一份XML文件按照它原本的建置結構拆解後,各部份資料存放於表格欄位中。在資料庫中使用或查詢XML文件時,以SQL指令配合一些符合XML特徵的新增函式查詢,再將查詢結果組成XML型式的結果,所以通常無法避免的,需要對多個表格用Join的方式來查詢。
使用Shredding的好處是,由於XML的子文件都已分別儲存在表格欄位裡,所以資料除了查詢之外,也可以變更內容。若對XML文件有變更內容的需要,Shredding會是比較適合的方法。不過正因為查詢XML時要對許多表格做Join,所以缺點就是效能較差。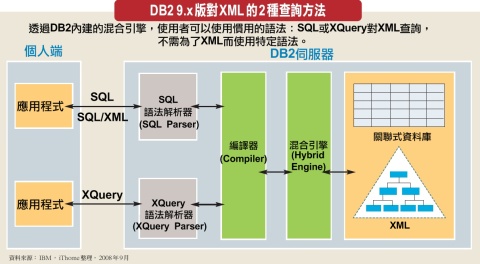
pureXML徹底強化DB2對XML的存取編輯能力
DB2 9.0開始,在XML資料形態上的處理方式,除了既有的Shredding以及CLOB,還新增了pureXML。
簡單地說,DB2在原本的關聯式資料儲存體中,額外加上了階層結構儲存體,可以直接儲存XML文件,不用透過拆解加工的方式,只要在建立表格時,宣告使用XML這個新的資料型態,即可更直接地存取階層結構的XML文件格式檔案。
pureXML對DB2來說,是個很重要的里程碑,因為有了它,DB2變成了既可以儲存傳統的關聯式資料表,同時又可以儲存階層結構XML檔案的混合結構資料庫。DB2可以在不破壞XML檔案結構的情況下,直接存取XML文件,因為不以大型物件的方式儲存,就沒有因為需要解析(Parsing)與外建索引而導致資料庫處理速度降低的問題。
在過往的CLOB中,XML主要是以大型物件的型態存入,透過解析的方式固然可以讀取XML的子文件(Sub-Document),卻無法直接進行編輯。你必須將整份文件取出、修改之後,再整份存回。另一種方式Shredding由於已經將XML拆解為表格,所以對XML文件的更新方式,必須使用一般表格欄位的Update來進行,與直接對XML的更新完全不同。
於是,IBM在DB2 9.5版又針對這部分加強了pureXML,例如可以直接對XML檔案的子文件加以修改,也就是可以對階層結構的內容直接編輯,不須將整份文件取出,或者對表格欄位更新等方式。
DB2 9.5還能在資料頁面(Page)上儲存XML。只要XML與關聯式資料表所需空間,不超出資料頁面大小,就可以在相同的Page儲存這兩種資料;如果XML超出Page大小限制,就不將XML檔案儲存於Page中,而改存於XML 資料區(XDA)。因為XML可以當成資料表的欄位,所以也可以用儲存資料列的方式來儲存XML文件,而存入的方法也同樣使用SQL指令來達成。文⊙林柏凱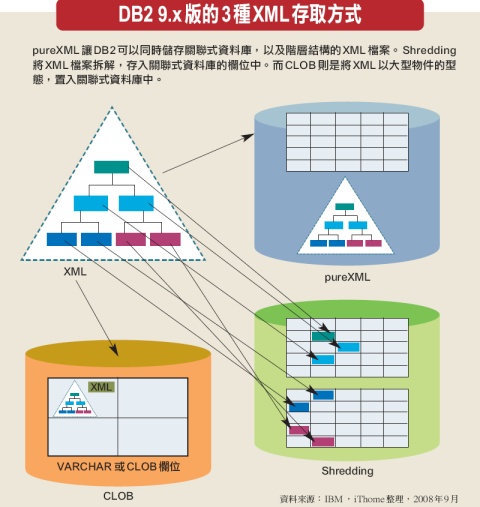 延續自動備援,資料表分割具彈性
延續自動備援,資料表分割具彈性
許多資料庫管理系統都會提供各種功能,以提升可靠度與管理便利性,對IBM DB2而言則是有高可用的復原機制,以及資料表彈性配置空間等功能,強化上述資料庫管理與維護工作。
以HADR強化資料庫可靠度
為了讓資料庫系統停機的可能性降到最低,DB2採用了高可用性災害復原(High Availability Disaster Recovery,HADR)的架構,來提升資料庫系統的可靠度。
HADR架構在DB2 8.2版就已經具備,它的部署方式,是就現有資料庫伺服器,額外再架設一個DB2主機,作為備用資料庫伺服器。兩者之間會以網路連接,藉此同步彼此間的資料內容,例如當使用者操作資料庫系統時,像是資料新增或修改,這些操作會由主要資料庫系統處理,並產生交易記錄(Log)。
這些交易記錄會由Log Writer編寫成Log Page,然後存放在Log資料庫內,同時傳遞一份至HADR控制器上,讓它將這些異動資料,透過網路傳遞至備用伺服器上的HADR控制器。
當備用伺服器上的HADR控制器,收到主要伺服器傳來的Log Page時,除了會將這些資料透過Log Writer,寫入Log資料庫之外,亦會同時傳遞一份至拆分器(Shredder)上,將這些Log Page還原成記錄(Log Record),再依照記錄內容,將這些異動套用到現有資料表或索引表中,讓備用資料庫上的資料,能配合主要伺服器同步更新。
建立備用資料庫伺服器後,如要於主要伺服器失效時,備用主機能自動取代,我們還需要在一臺主機上安裝Tivoli System Automation(TSA)系統,藉此透過網路觀察主要伺服器是否正常運作,如果偵測到服務終止,TSA就會「通知」備用伺服器,讓它取代原本的主要伺服器。TSA通常會安裝在備用資料庫的主機上,亦可建置在第三方伺服器,監控DB2資料庫正常與否。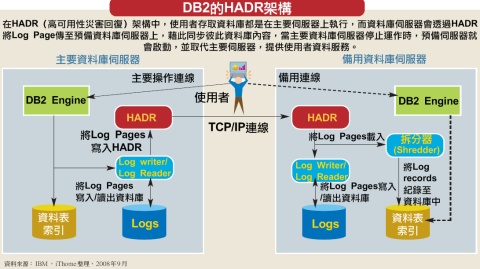
資料表分割空間彈性配置,並節省資料搬移資源
維持可用性是資料庫持續運作的要項,在系統運作上還需要注意效能是否運用得當。對許多企業來說,經年累月所累積的資料庫內容,其規模大多相當可觀,這裡面有些資料表儲存的內容,甚至多達數百萬筆。面對這麼龐大的表單,若要將資料由磁碟載入系統,或是查詢表單內的資料,對管理系統的執行效率,或多或少會產生負面的影響。在DB2中,假如需要存取一張龐大的資料表,管理者可藉由資料表分割功能,將單一資料表,依照欄位分別儲存在不同的表單空間(Table Space)中,並將這些表單空間的儲存位址,指定至不同的實體磁碟中,藉著跨磁碟存取,提升I/O速度。資料表分割置於不同的表單空間時,只有底層存放方式改變,資料在邏輯上還是同一張資料表,因此操作時指定的表單名稱並不會因此而改變。
這種作法的實作相當必要,越來越多資料庫平臺都支援這方面的功能,將資料表分割存放在不同的表單空間中,除了加快資料載入外,管理配置上也更加彈性,例如某些應用中,會需要在表單中維持固定區間的資料。以我們圖表中的主要交易資料為例,都是採用近3年的訂單資料為主,而這個區段內的資料,其實是單一資料表內不同的資料列,也就是依照建立年份區分成三段資料區間,存放在資料庫中。
將這些常用的資料集中於同一區段,當我們在查詢資料時,就會以該區段為範圍,而不必同時搜尋其他年度資料。如果企業採用這種方法,遇到年度更迭時,便需要將舊的資料匯出,並將新資料匯入,藉此維持資料內容。
這類匯出與匯入的操作,在DB2中稱為Roll-In Roll-Out Maintenance。DB2在之前的管理系統中,我們如果要執行這種卸除舊資料並加入新的作業,需要先把指定資料匯出成另一表單,完成後再將這些資料刪除,好將空間釋出。這些資料搬遷處理,都需要占用許多系統資源,而且資料搬遷時,資料表會鎖定禁止其他人存取,這些情況都會嚴重影響資料庫運作效率。
到了第9版的DB2中,上述這種操作可使用表單分割(Table Partitioning)中的載入(Attach)與卸載(Detach)功能,在資料表改變配置的過程中,並不需要將資料表大量移動。以圖表上的資料為例,當更新主要交易資料的內容時,是將舊資料卸載,並載入新資料,而不是以整批匯出及匯入的方式處理。
細部來說,DB2的處理方式,是將2005年資料由Table Space3上卸載,再將2008年資料載入該空間內,而被卸載的資料會轉變成為一張獨立的資料表。和匯入匯出很大不同之處在於,卸載與載入並沒有實際搬移磁碟內儲存的內容,而是改變資料所屬的表單空間,因此處理時間與資源使用量,相較於以往精簡不少,而卸載成為獨立表單的舊資料,也能以匯入的方式,轉移到歷史資料庫中儲存。文⊙林郁翔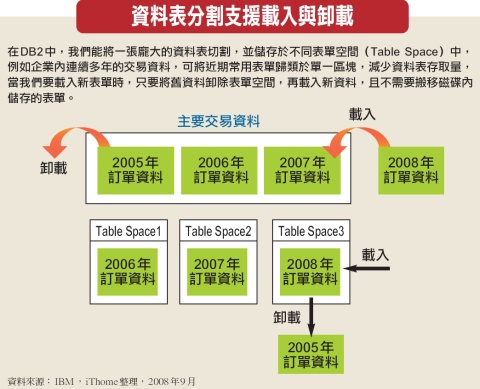 DB2與關聯式資料庫的深厚淵源
DB2與關聯式資料庫的深厚淵源
|
|
| 傅毓勤認為,關聯式資料模型的提出、System R 計畫的開展與S Q L / D S 的誕生,不只是幫DB2 奠定了基礎,也引發了日後商業化關聯式資料庫的普遍應用。 |

關聯式資料庫管理系統這項技術發展已將近40年,它和IBM有很深厚的淵源,從理論、實作、產品化,到了1983年正式推出DB2第一版,這個時間點距今剛好滿25年。
從第二版開始參與該項產品研發的IBM矽谷實驗室查詢技術部DB2 z/OS資深研發經理傅毓勤表示,DB2不只是IBM的第一套關聯式資料庫產品,假如也將早期IBM奠定理論和推動實際應用的基礎等因素考慮進來,說它是業界第一套關聯式資料庫,當之無愧。
理論建構:關聯式模型
關聯式的資料模型理論是在1970年出現,由IBM研究院的E.F. Codd發表了業界第一篇關於關聯式資料庫技術的重要論文,題目為〈A Relational Model of Data for Large Shared Data Banks〉。
Codd認為,將來如果在共享的環境下,需要管理大量資料,關聯式模型(Relational Model)是最強大的一種構想。當時這僅止為一個研究方向,必須要發展、實現出一些基礎的技術,因此IBM繼續在這方面發展。
SQL語法與查詢最佳化的濫觴
首先要建構的是程式語言,這些關聯性需要特定的運算子(Operator)去表達、怎麼做聯結(Join),都需要靠一套語言來加以規範與定義。後來SEQUEL查詢語言的出現,再加上查詢最佳化的技術理論的推出,都是很關鍵的發展,讓這個模型可行性越來越高。
在1974年,IBM的Don Chamberlin和Ray Boyce共同提出一篇論文〈SEQUEL:A Structured English Query Evaluation Language〉,主要關於一套全新設計的程式語言,用在關聯式資料庫的資料存取和操作上。顧名思義,SEQUEL是一種口語化查詢語言,使用上就像一段英語敘述,而且語意是完備的、不會有矛盾。
這部分的成就也成為1986年後的ANSI/ISO SQL標準的基礎。這兩位等於SQL語言的鼻祖。這項技術,等於把關聯式模型落實成一套真正存在的語言,你可以用它來描述怎麼去查詢,在實用度和處理能力上是一個躍進。
SQL運用在程式開發上,和既有的程序式程式語言(Procedural Language)上有很大不同,傅毓勤認為,你所要描述的是What而不是How,例如你只要指定特定的資料表加以連結,而非把宣告變數、資料型別、運算子、表示式、迴圈相關的敘述等所有細節,一五一十地寫出來。當時,這也是被人質疑的。究竟這樣的語言能不能有效地實現出來,換句話說,還需寫出一個編譯器來剖析這樣的程式,執行最佳化。
於是,1979年,IBM的Patricia Selinger在美國電腦協會的SIGMOD 大會上發表一篇〈Access Path Selection in a Relational Database Management System〉,這是第一份有關於關聯式模型查詢最佳化的論文,也確立了今後SQL查詢最佳化(SQL Query Optimization in RDBMS)的發展方向。傅毓勤說,放眼望去,幾乎所有的優化工具,都是憑藉這個基礎發展出來的。
在資料庫發展上要做到最佳化查詢,通常會遇到NP Hard等級的問題,要找到最好的演算法一直很難,因為時間耗費通常與資料表數量的增加成指數成長,比如要處理30個資料表,可能就得用到天文數字般的處理量,但Patricia Selinger提出用工程來解決的方法,例如根據查詢的複雜度、回傳結果的資料量、也就是預估各種存取資料方法的成本,用布林表示式來決定對應的存取計畫。
SQL/DS和DB2 for z/OS
這兩項理論讓關聯式資料模型就不再是那麼抽象的名詞,實現的可能性大增。接下來還有三件事在歷史上很重要,就是如何產品化,使DB2成為一套能夠真正用在業界的產品。
1982年,IBM基於System R和SQL推出全世界最早的商業化關聯式資料庫SQL/DS,用在VSE和VM這兩個大型主機的作業系統上,它也是第一個針對查詢處理程序(Query Processing)的系統;隔年他們又將SQL/DS一部份作為新的資料庫產品Database 2的基礎,DATABASE 2即為我們目前慣稱的DB2。也就是說,SQL/DS是DB2的前身,所以DB2也算是從System R衍生出來。
為什麼叫做Database 2?原因是IMS是IBM發展出的第一套階層式資料庫管理系統,而相對於階層式模型,他們認為這套新的系統是第二代的資料庫系統。
DB2的第一個版本,當時主要用在決策支援方面的少量查詢,還無法真正運用在交易上,例如銀行的核心業務。到了1988年第二個版本發行時,又有了一個革命性的改變,Don Haderle、Jim Teng(鄧之嘉)、Howard Herron帶領開發團隊,將交易率大幅提升,讓DB2成為可以真正用在交易的資料庫系統。
加入並行處理演算法和資料分享的架構
一套資料庫管理系統除了能簡化資料存取、負擔線上交易,在可用性、延展性和可靠度也需要提出保障。
可用性的強化上,主要是Aries的並行處理演算法,它是由C. Mohan和Don Haderle在1980年代中、晚期所發展的。這個計畫主要是針對並行處理的控制(Concurrency Control)上,把鎖定(Lock)的技術從資料頁(Page)降到資料列(row)的等級,因為粒度變小了,所以並行處理的效率大大提升,這也讓系統復原比較有效率。
在可用性和延展性,還有一項關鍵技術,傅毓勤特別強調是DB2至今仍獨有的,那就是資料共享(Data Sharing)。在1988到1994年當中,IBM極力想讓這個平臺的處理能力能夠獲得突破性的改變,他們提出了Sysplex的架構和資料共享的技術,這是由Inderpal Narang、C. Mohan, Don Haderle、Jim Teng和Jeff Josten帶領的團隊所發展出來的。在DB2 for MVS V4,IBM也開始運用這樣的技術。
這個架構是指,你可以同時有多個執行DB2系統的成員,它們能在不同的主機上執行,然後合起來成為一個叢集,共享同一個資料庫;它們可以各自執行自己的應用程式,也可以合起來執行同一個應用程式。
傅毓勤表示,以可用性來說,合起來之後,它們之間是共享的,假設成員當中有一個停機、無法運作,其他成員會自動繼續維持運作,系統不需要額外執行其他容錯的機制,除非全部成員停止運作。
Sysplex還能用於延展性和工作負載平衡,例如動態加入新成員來分攤處理。這些成員共享了資料庫,它們可以執行在相同或不同的邏輯分割區(LPAR);如果分散在不同硬體上,它們彼此還可以相互支援處理,將工作負載分配至同時段比較閒置的主機上。文⊙李宗翰
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05