Databricks旗下Mosaic AI Research團隊發表MemAlign,這是一套用雙記憶系統累積專家自然語言回饋的LLM評審對齊框架,並宣布將其導入模型生命周期開源平臺MLflow,使企業LLM評審判斷更貼近領域標準。開發團隊指出,提示詞工程在規則逐步增加後容易出現前後不一致、覆蓋範圍難以控管等問題,也會受限於上下文長度,而微調則需要較高的資料與時間成本,因此改以記憶機制讓評估標準能隨回饋累積而調整。
企業在導入生成式AI後,常以LLM評審也就是讓大型語言模型充當自動評估器,檢查代理程式與客服機器人的輸出是否安全、正確且合乎規範。不過這類通用評估器的判斷,往往和領域專家在實務上看重的品質要求不一致。Mosaic團隊舉例,模型可能只從措辭是否禮貌下結論而忽略使用者意圖,也可能認為客服只要交代原因與處理時程就算合格,卻沒有把先安撫情緒、使用支持性語氣收尾等服務標準納入判斷。
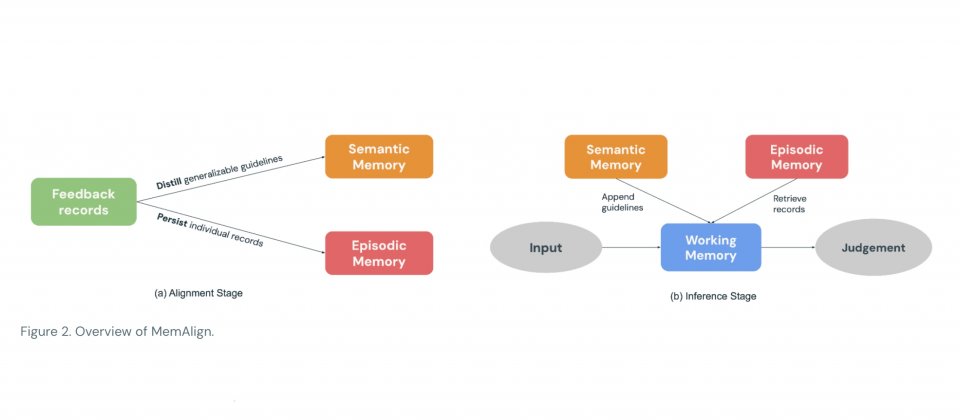
MemAlign採用雙記憶體架構,不必更新模型權重。系統會把專家以自然語言寫下的回饋,萃取為可在不同情境重複使用的原則,存入語意記憶,同時把較難用原則完整涵蓋,也較容易出錯的具體案例保留在情節記憶。當新輸入到來時,MemAlign會先彙整既有原則,並從情節記憶中檢索相近案例,一起組成工作記憶作為當次評估的參考脈絡,再交由LLM完成評分。記憶內容也支援刪除或覆寫,方便因應規定調整、需求變更,或資料清除等情境。
在Prometheus-eval LLM評審基準測試的10個資料集上,團隊以最多50筆回饋樣本進行對齊。結果顯示,MemAlign在該設定下以約0.03美元的對齊成本,約40秒的對齊時間達到最高品質。相較之下,DSPy系列提示詞最佳化工具在同一對照中約需1至5美元成本,9至85分鐘才能完成一次對齊迭代。
Databricks也提醒,推論階段因需要對記憶執行向量搜尋,單筆評估可能額外增加約0.8至1秒延遲。MLflow文件則把MemAlign標示為實驗性最佳化工具,提醒介面可能異動,並建議在評估追蹤紀錄中提供人工評估結果與自然語言理由,以方便對齊過程吸收專家判斷依據。Databricks表示,MemAlign已可在開源MLflow與Databricks平臺使用。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-02

2026-03-03