")
國泰金控表示,要透過和Nvidia合作,打造臺灣首個金融AI Agent。(圖片來源:國泰金控)
國泰金控今日在Nvidia GTC Taipei上宣布,未來會聚焦發展AI Agent,要透過和Nvidia合作,打造臺灣首個金融AI Agent。此外,在活動上,國泰金控發表了一項臺灣金融知識LLM的實驗案。這個由國泰金控打造的臺灣金融知識LLM,未來也將作為金融AI Agent背後的核心大腦引擎,支援多元金融服務應用。
早在去年九月,國泰金控就公開自家GenAI技術框架GAIA。這是國泰發展生成式AI的基礎框架,也是他們發展AI即服務(AI as a Service)的核心。當時,這個技術框架僅包含三個核心模組,分別是知識庫、Model Hub,和護欄。
然而,國泰金控副總經理劉浩翔表示,為了強化AI Agent發展,國泰金控也調整了GAIA技術框架,在框架中新增了AI Agent模組。他也表示,未來要透過和Nvidia合作,強化AI Agent應用的環境互動能力、記憶處理能力、學習成長能力和自主化能力。「這些都將是我們在發展金融 AI Agent 時,技術建設上必須完成的方向。」劉浩翔說。
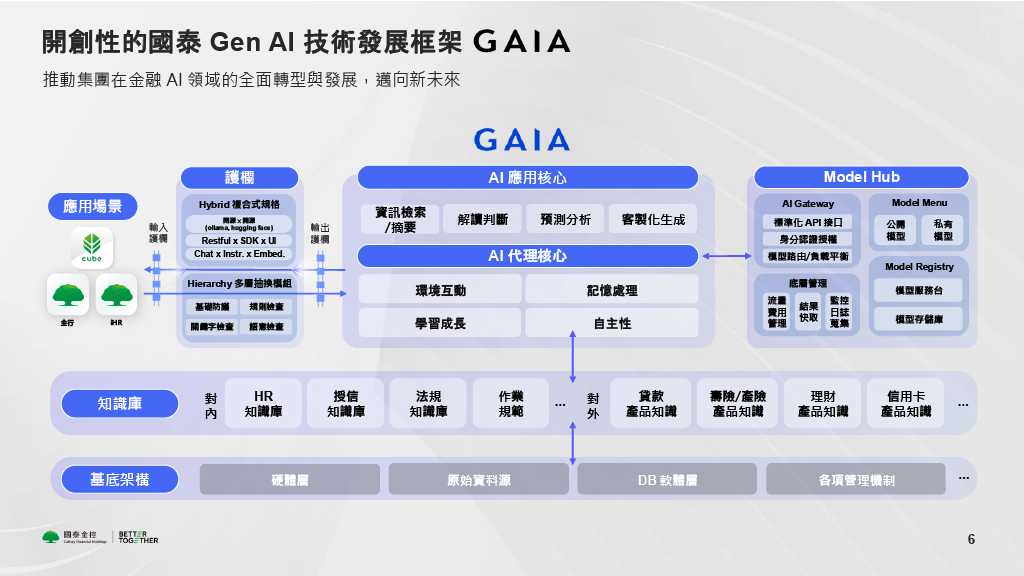
為了強化AI Agent發展,國泰金控調整了生成式AI技術框架GAIA,在框架中新增了AI Agent模組。(圖片來源:國泰金控)
劉浩翔提到,國泰金控對於AI Agent長期願景,則是能發展出各種金融服務的AI Agent,例如信貸AI Agent、貸款AI Agent、信用卡AI Agent、保險AI Agent,和財管AI Agent等。「我們希望未來各種AI Agent,除了能在國泰內部互相溝通協作,也能跟異業合作夥伴做Agent to Agent的協作溝通。」他說。這是國泰金在發展金融AI Agent生態系的長遠目標。
不過,要能實現這個長遠目標,「有個最關鍵的成分,是背後需要一個具備臺灣金融授信知識的LLM。」劉浩翔說。這也是國泰金控今日在Nvidia GTC Taipei上發表的一項實驗案。他們運用包括財經新聞、臺灣金融法規和臺灣金融知識等資料,透過NVIDIA NeMo訓練框架,在本地端環境預訓練、微調多個開源大型語言模型,並且,國泰金控將金融授信證照相關考試,作為模型的驗證目標。
這個實驗案中的模型訓練框架包含資料處理、模型選擇,和驗證方式,底層架構則包含訓練框架和算力基礎。國泰金控在資料處理中有運用資料清洗,以及由金融專業人員進行資料標註,和運用NVIDIA NeMo Curator協助生成資料,進行資料增強。
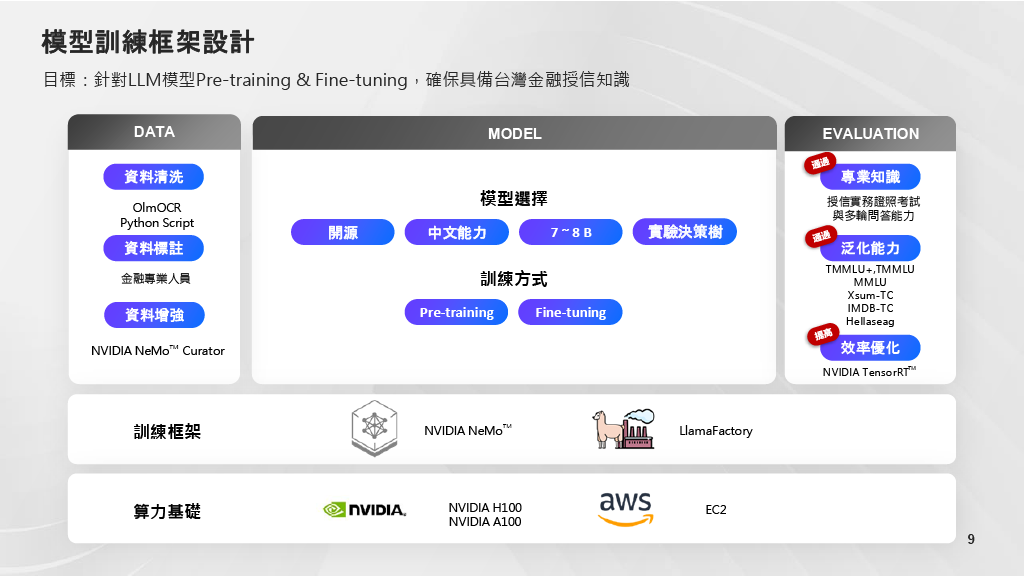
國泰金控針對金融LLM設計一套模型訓練框架,以進行預訓練和微調。(圖片來源:國泰金控)
而在模型選擇上,國泰選擇三個模型,分別是Nvidia的Nemotron模型、國科會打造的TAIDE模型,和Project TAME模型,模型參數量大約在7B至8B左右。另外,國泰採用了微調和預訓練的方式來訓練這些開源模型。
而在模型訓練階段時,國泰先是透過預訓練建立模型對金融語言和知識的理解基礎,再運用微調模型,來進行任務導向調整,讓模型具備金融語境推理能力和授信流程專業知識回應能力。另外,他們國泰也有整合Deepspeed框架來加速訓練模型,降低GPU和記憶體使用。
最後在驗證方式上,國泰金透過三類驗證機制來衡量模型是否訓練成功。第一類是金融專業知識,包括讓模型進行授信實務證照考試,並測試模型的多輪問答能力。第二類是泛化能力,也就是訓練模型在基礎知識上的能力。劉浩翔解釋,有許多模型過度訓練,反而可能失去基礎知識能力,因此國泰仍有設立相應的驗證機制,來確保模型在基礎知識的能力並未減損。第三類是驗證效率優化。國泰運用Nvidia服務來測試模型的效率優化程度。
國泰金控表示,模型訓練結果顯示,完成訓練後的模型可以通過授信證照考試,並維持繁體中文泛化理解能力。三種開源模型在完成預訓練和微調後,進階金融授信知識正確率都有近九成,甚至超過九成的正確率。繁體中文泛化理解能力則是和原始模型維持相近的水準。
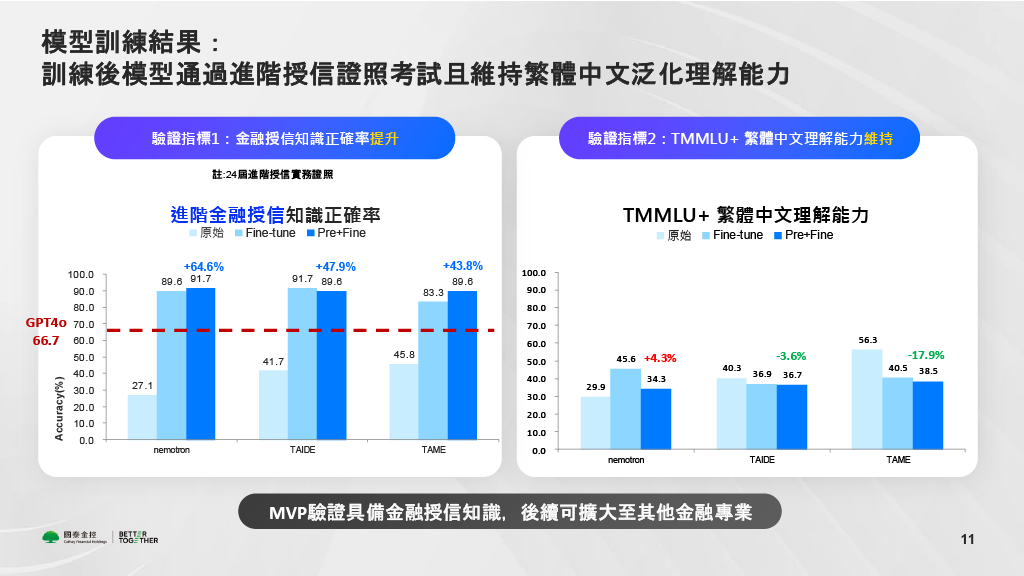
實驗案中的模型訓練結果顯示,完成訓練後的三種開源模型都可以通過金融授信證照考試,並維持繁體中文泛化理解能力。(圖片來源:國泰金控)
國泰金控表示,未來他們會延續這項實驗案的成果,讓這個臺灣金融知識LLM作為打造金融AI Agent背後的核心金融大腦引擎,進一步串接至各項金融服務的工具,打造出臺灣首個金融AI Agent。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-25

2026-02-23