
Hugging Face
繼於6月釋出Gemma 2,提供9B及27B兩種版本之後,Google周三(7/31)再接再勵開源了Gemma 2 2B,並宣稱此一小型模型在聊天機器人(Chatbot)評測上超越所有GPT-3.5模型。同一天Google還開源了安全內容分類模型ShieldGemma,以及可用來解釋模型內部作業的Gemma Scope。
Google在今年2月開源的Gemma屬於輕量級模型,但採用與大型語言模型Gemini一致的研究及技術,可於高階遊戲筆電、高階桌上型電腦,以及雲端上執行。
而Gemma 2 2B則是Gemma 2模型家族中最小的模型,是藉由蒸餾從更大的模型中學習,而取得了超乎其規模的傑出成果,它不僅超越其它同樣大小的開源模型的表現,也在LMSYS Chatbot Arena Leaderboard上超越了所有GPT-3.5 模型,展示其強大的對話式AI能力。
.png)
Google亦強調了Gemma 2 2B的靈活部署能力,可支援邊緣裝置、筆電,以及使用 Vertex AI與Google Kubernetes Engine(GKE)的強大雲端部署,而為了進一步提升其速度,利用Nvidia TensorRT-LLM函式庫進行最佳化,並可作為Nvidia NIM使用。
此一最佳化適用於各種不同部署,涵蓋資料中心、雲端、本地工作站、個人電腦與邊緣裝置,並利用Nvidia RTX、Nvidia GeForce RTX GPU或Nvidia的Jetson模組來執行邊緣AI,也能在Google Colab平臺上免費的T4 GPU上執行。另外它也能無縫整合Keras、JAX、Hugging Face、Nvidia NeMo、Ollama、Gemma.cpp 以及即將支援的MediaPipe,以簡化開發。
至於ShieldGemma則是個安全分類模型,可額外部署在模型的輸入及輸出端,用以過濾有害內容,它主要篩選4大領域的內容,包括仇恨言論、騷擾、裸露的色情內容,以及危險內容。
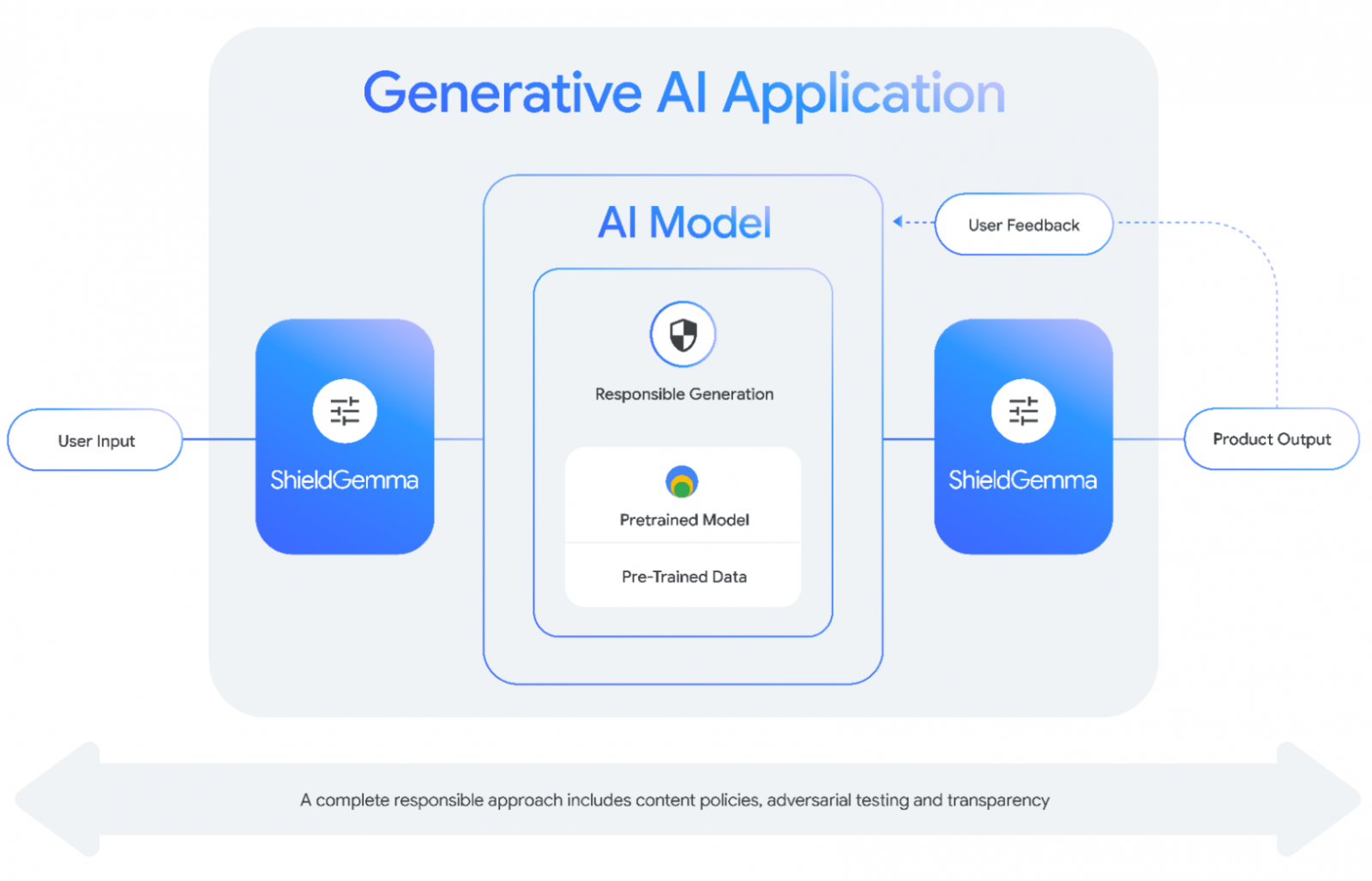
ShieldGemma具備2B、9B與27B版本以供開發者選擇,其中,尺寸較小的ShieldGemma 2B最適合線上分類,9B與27B則相對適合較無延遲考量的離線應用。
本周開源的還有稀疏自動編碼器(Sparse Autoencoder,SAE)Gemma Scope。Google是在Gemma 2 9B及Gemma 2 2B的每一層及子層輸出上訓練稀疏自動編碼器,製造了超過400個SAE,具備逾3,000萬個特徵,而Gemma Scope即是這些SAE的集合。
.png)
SAE為一特殊的神經網路,可於資料中找到有用的特徵,因此,ShieldGemma將協助研究人員理解特徵在模型中的演變、相互作用,或是如何形成更複雜的特徵,解讀Gemma 2所處理的密集與複雜資訊,進一步透明化相關模型的內部作業。
美國商務部旗下的國家電信暨資訊管理局(NTIA)日前才發布政策建議,指出開放權重的模型允許開發者利用既有的基礎建置與調整,把AI工具的可用性延伸至小公司、研究人員、非營利組織與個人,將擁抱AI的開放性,但也應該積極監控強大AI模型的安全風險。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09


2026-03-09