,可處理複雜的多步驟推理任務,透過2個階段不斷迭代。")
來自Meta、艾倫AI研究院和華盛頓大學的研究團隊開源一款語言模型代理哈士奇(HUSKY),可處理複雜的多步驟推理任務,透過2個階段不斷迭代。
重點新聞(0619~0625)
Husky-v1 語言模型 代理
Meta開源一款AI代理「哈士奇」
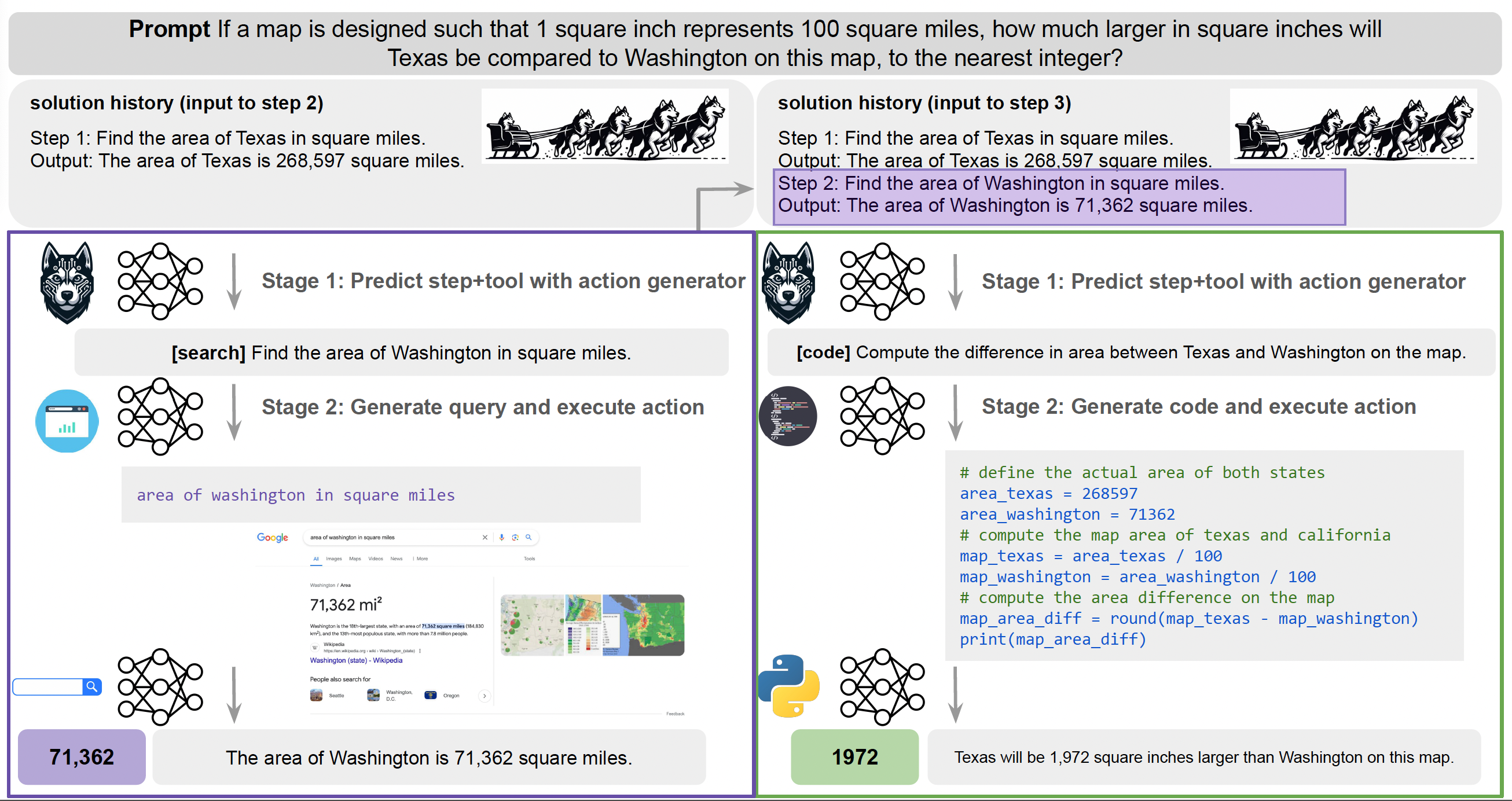
最近,來自Meta、艾倫AI研究院和華盛頓大學的研究團隊開源一款語言模型代理哈士奇(HUSKY),可處理複雜的多步驟推理任務。進一步來說,AI代理(Agent)是指由AI模型驅動的智慧系統,可從環境中學習、適應並自動完成特定任務,比如Siri。而哈士奇這個代理在統一空間中執行運算,意味著單一個哈士奇就能處理多類型任務,像是數值、表格和知識推理,而非只專注特定任務,如程式碼撰寫代理。
團隊發表的第一代哈士奇代理為Husky-v1,透過2個階段不斷迭代:首先是根據給定任務,來生成下一步的解決動作,再來是用專家模型執行這個動作,同時不斷更新解決方案。其中,第一代哈士奇的專家模型包含程式碼生成器、詢問生成器和數學推理器等3款,它們皆用合成資料訓練而成。團隊也用14個不同任務來評測Husky-v1,發現它的表現優於其他代理,如CoT、ReAct、Lumos等,甚至在混合工具推理任務中,勝過GPT-4-Turbo。(詳全文)
蘋果 LLM MLX
開發者可用MLX函式庫,聯合多臺蘋果裝置跑大模型了
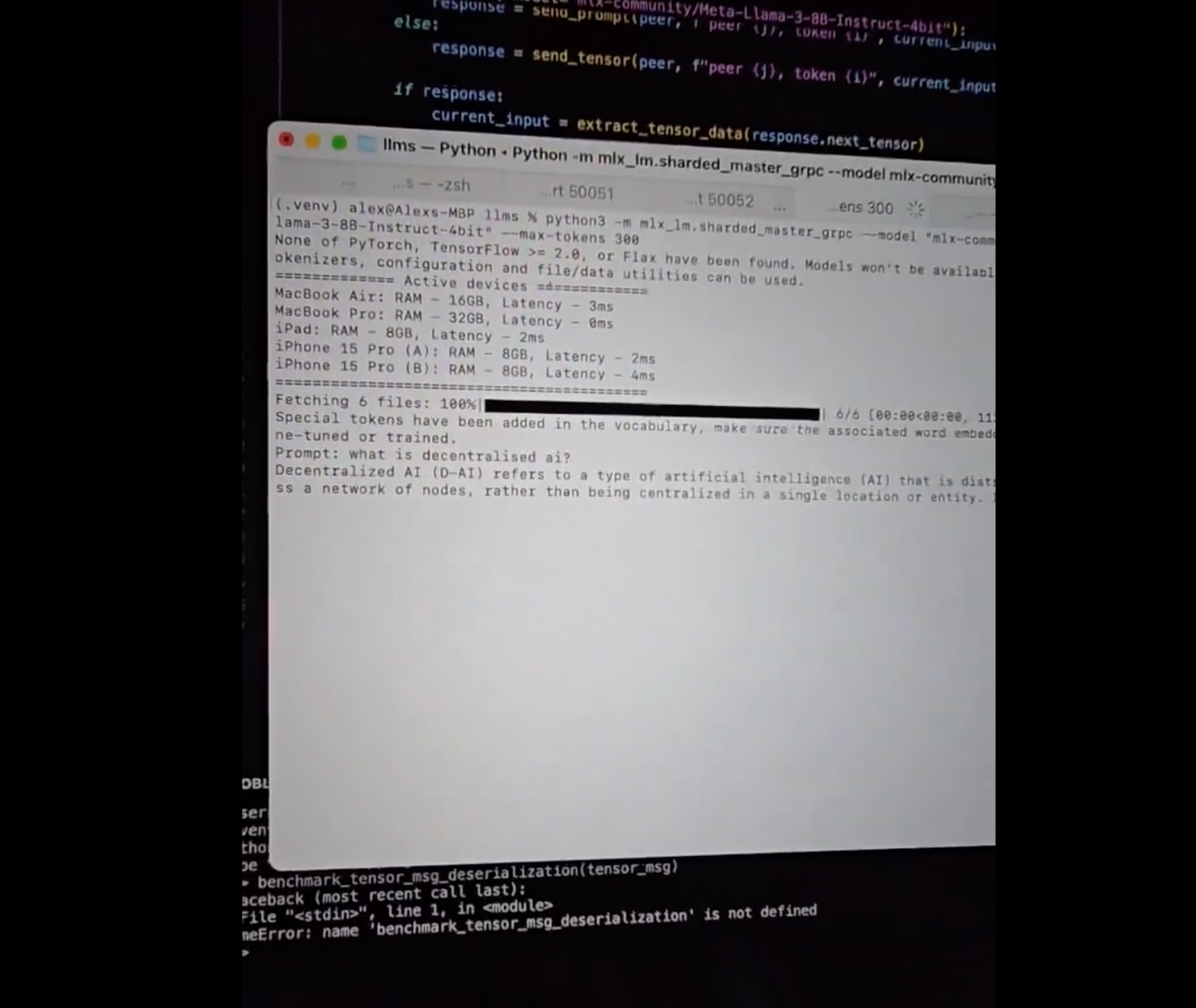
最近,蘋果才結束今年度發表大會WWDC,主打Apple Intelligence、聚焦個人化AI功能和隱私保護,但還留了一手。也就是,開發者可用蘋果的開源機器學習函式庫MLX,來聯合蘋果裝置(如Mac筆電、iPhone手機和iPad等)算力、形成一個AI叢集,來執行大型AI模型。
日前就有位開發者Mohamed Baioumy分享經驗,他使用了2臺MacBook、2支iPhone 15 Pro和1臺iPad,來執行80億參數的Llama 3 instruct 4 bit模型,可以非常快的速度回答文字問題。另有位開發者Mohamed Baioumy表示,就算不是蘋果裝置也可以,也就是說,只要所有裝置都使用同一個網路,開發者就可堆疊多個裝置來跑大模型。這代表,開發者可透過多個裝置來執行先進的AI模型了。(詳全文)
金管會 AI指引 金融業
金管會發布金融業運用AI指引
最近,金管會終於發布「金融業運用AI指引」,與去年12月底提出的草案大方向一致,除提供AI系統和生成式AI定義,也說明4個AI系統生命周期階段,並提供業者在各階段中落實6大核心原則的處理機制。
進一步來說,這份AI指引就像是一份AI操作建議書,分別引導業者在導入AI或使用生成式AI時,如何在4個階段中,包括系統規畫及設計、資料蒐集及輸入、模型建立及驗證、系統部署及監控等階段,落實6大核心原則,也就是建立治理及問責機制、重視公平性及以人為本的價值觀、保護隱私及客戶權益、確保系統穩健性與安全性、落實透明性與可解釋性,和促進永續發展。
比起草案,這份正式版多出了實務作法,也提及更多第三方業者的監督管理方式,對自建、委外和外購等不同部署方式增訂相關內容,也修改風險評估因素的敘述方式、增加指引適用的彈性。綜合規畫處處長胡則華指出,目前採用生成式AI的金融機構有29家,銀行業占最多,使用場景大多為內部作業,第二是智能客服,第三則是行銷廣告。(詳全文)
語言模型 Meta 程式撰寫
Meta揭露4款語言模型,涵蓋程式撰寫、音樂生成和音訊浮水印
日前,Meta AI研究院最近發表4款語言模型,包括Meta Chameleon,含70億參數(7B)和340億參數(34B)版本,支援多模態輸入值,但只以文字輸出。另一款模型是Meta Multi-Token Prediction,是一款預訓練語言模型,專門用來處理程式碼撰寫任務。這是因為該模型採用多Token預測方法,可即時預測好幾個字,而非只預測一個,也因此提高了作業效率和回應速度。
第三款模型是Meta JASCO,是一款生成式文字轉音樂模型,預計晚些時候釋出預訓練模型。最後一個模型是Meta AudioSeal,是一款音訊浮水印模型,能在裝置端偵測AI生成的語音,並配上浮水印;該模型開放商用授權。除了模型,Meta也發表負責任AI研究成果,包括了研究本身、資料和程式碼,可用來衡量和改善AI系統中的地理表徵、文化偏好和多元性。(詳全文)
Luma AI 影片生成 Dream Machine
美AI新創開源高品質影片生成模型
舊金山一家AI新創Luma AI最近發表AI系統Dream Machine,可根據簡單的文字描述,來生成高品質影片,且號稱幾分鐘就能完成。有別於OpenAI的影片生成模型Sora和快手的Kling、只對特定群眾開放,Luma AI開放各界免費在自家網站嘗試這款系統。
Luma AI表示,Dream Machine目前雖只能生成5秒長的影片,但在品質上相對寫實逼真,可應用的領域更廣。(詳全文)

Claude 3.5 Sonnet Anthropic 語言模型
Claude 3.5 Sonnet問世了,評測表現勝過GPT-4o
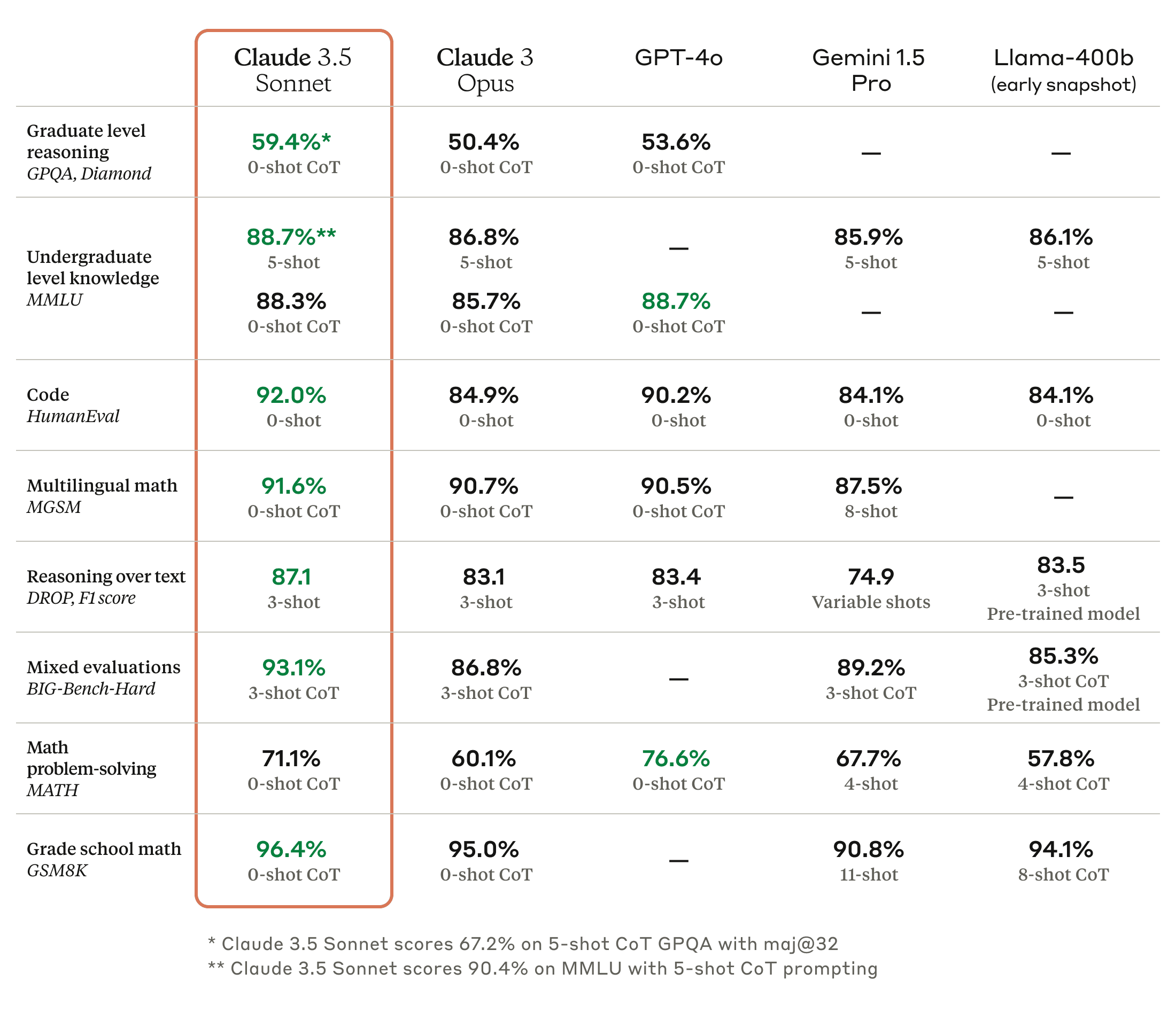
Anthropic日前發表了新款大型語言模型Claude 3.5 Sonnet,是Claude系列的中階模型,但表現和效率都超越Claude 3.0的高階模型Opus,在大多數的評測上也勝過OpenAI今年5月推出的GPT-4o。進一步來說,Claude 3.5 Sonnet的執行速度是Claude 3 Opus的兩倍,Anthropic自己也以自然語言指令,要求不同模型修補開源程式碼臭蟲或新增功能,發現Claude 3.5 Sonnet解決了64%的問題,超越Claude 3 Opus的38%。
在提供指示與相關工具後,Claude 3.5 Sonnet得以獨立撰寫、編輯與執行程式碼,可執行複雜的推論及故障排除能力,輕鬆處理程式碼的轉換,能更有效率更新老舊應用程式並遷移程式碼庫。Claude 3.5 Sonnet不僅在所有基準評測上勝過Claude 3 Opus,它在GPQA、HumanEval、MGSM、DROP、BIG-Bench-Hard或是與視覺有關的MathVista、AI2D、Relaxed accuracy及ANLS score等評測上也超越了GPT-4o,只有在MMLU、MATH及MMMU上略遜GPT-4o。(詳全文)
EVI Hume AI 情緒辨識
Hume AI推出懂53種情緒的iOS App:EVI
最近,Hume AI上架一款號稱讀懂人類情緒的iOS應用程式EVI,由Anthropic最新的語言模型Claude 3.5 Sonnet驅動。特別的是,EVI背後的同理心大語言模型可解讀語調、強調字眼和非口語的暗示,來優化互動體驗。EVI可理解53種人類情緒,如開心、生氣、困惑、欺騙等。至於EVI採用的聲音模型Kora,則能以API方式提供給開發者,目前也支援Anthropic、OpenAI和開源語言模型,預計之後很快就會納入Google模型。開發者可以建立他們的應用程式,並加入EVI的Discord來獲得更新資訊。
EVI的情緒理解能力,是來自Hume AI對非話語的情緒性語音研究成果,這類語音是指透露情緒的語助詞,或單純是透露情緒的發聲詞。為訓練EVI的情緒理解模型,Hume AI收集了來自1萬6千多人共數千個語音片段檔案,橫跨美國、中國、印度、南非和委內瑞拉。Hume AI表示,未來,他們打算擴展EVI能力,增添全球通用的臉部表情辨識能力。(詳全文)

Databricks AI治理 Unity Catalog
Databricks揭露一款資料與AI治理工具,採開放API和通用介面
Databricks最近宣布,將於今年第3季發表一款統一、可跨雲和資料平臺的資料與AI治理解決方案Unity Catalog OSS預覽版。Databricks希望藉該工具,來建立AI治理可互通的開放標準。
這款Unity Catalog OSS提供通用介面,可支援多種資料各式和運算引擎,還能統一治理表格類資料、非結構化資料、機器學習模型等AI資產。在AI治理部分,這款工具可自動監控模型、診斷錯誤並維護資料和模型品質。該工具也會主動發出警報、自動偵測個人識別資訊(PII)資料、追蹤模型是否漂移,並能解決資料和AI工作流程中的問題。透過開放API和Apache 2.0授權,使用者可免於被廠商綁死,不過,AWS、Google Cloud、微軟、Salesforce、Confluent、dbt Labs、Immuta等多家業者都表示支援Unity Catalog OSS,認為此舉為使用者帶來更大的彈性,還與開源生態系原則相符。(詳全文)

圖片來源/Meta、Mohamed Baioumy、Luma AI、Anthropic、Hume AI、Databricks
AI近期新聞
2. 前OpenAI首席科學家Ilya Sutskever成立新公司,瞄準AI安全性
3. Pixel 8、Pixel 8a終於也有Gemini Nano了
資料來源:iThome整理,2024年6月
熱門新聞

2026-03-06




2026-03-06

2026-03-09

2026-03-09

2026-03-09