Groq
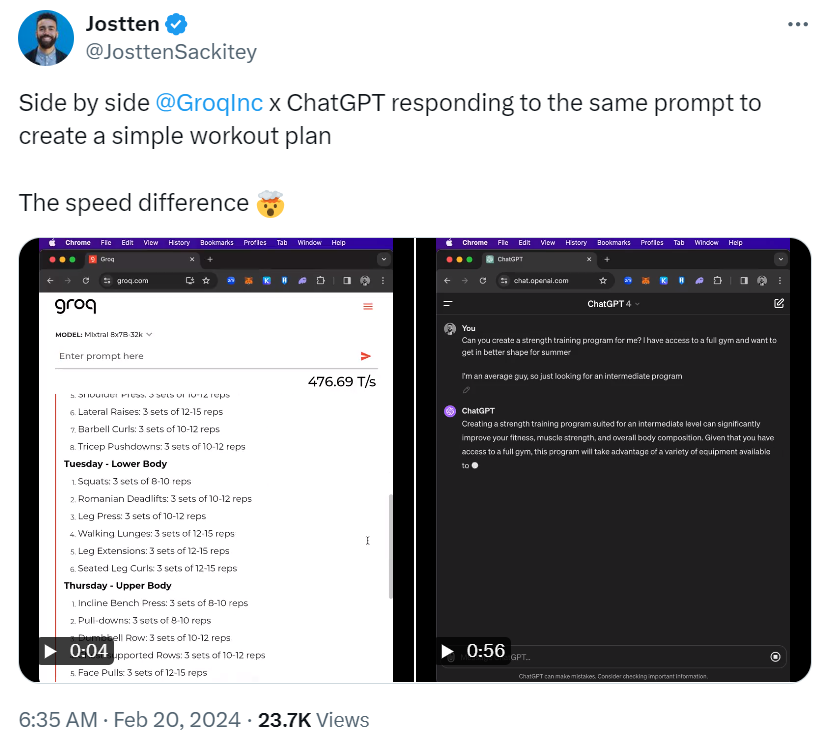
2016年便創立的Groq在這幾天成為全球AI社群最關注的話題,X上開始出現以Groq LPU推論引擎來執行大型語言模型(LLM)的展示,顯示它的執行速度飛快,更有不少人將Groq與ChatGPT作比較,在兩個機器人聊天室中輸入同樣的提示,ChatGPT花了60秒生成了答案,Groq卻只花了12秒。
不過,Groq主要開發的並非聊天機器人或模型,而是語言處理單元(Language Processing Unit,LPU)推論引擎(LPU Inference Engine)。
Groq於官網上闡明,該公司的任務是設立生成式AI(GenAI)推論速度的標準,以實現生活上的即時AI應用,所開發的LPU推論引擎為一新型態的端對端處理單元系統,可替諸如AI語言應用等具順序元件的運算密集應用提供全球最快的推論服務。
現代的AI系統多半是在GPU上執行,而LPU的設計是為了克服LLM在運算密度與記憶體頻寬上的兩大瓶頸,就LLM而言,其運算能力大過CPU與GPU。
Intuition Machine共同創辦人Carlos Perez指出,在新一代的AI晶片新創公司中,Groq以一種完全不同的方法脫穎而出,聚焦於利用編譯器技術來最佳化極簡而高效能的架構,此一以編譯器為優先的設計避開了複雜性,轉而追求效率。
Perez說明,Groq架構的核心是個單純支援平行吞吐量的裸機,如同一個專為機器學習設計的ASIC,但有別於只具備固定功能的ASIC,Groq可利用客製化的編譯器來支援不同的模型,流線型架構再加上智慧型編譯器令它與眾不同。
相較於像是GPU等利用許多元件堆疊而成的AI晶片,可能含有無關的硬體或顯得臃腫,Groq則回歸基本原則,意識到機器學習的工作負載是關於簡單的資料類型及操作,藉由消除通用硬體或局部性等概念,最大化其吞吐量與效能。
LPU Inference Engine在推論上究竟有多快?可以從AI應用平臺Anyscale對8款不同LLM推論供應商的測試中(下圖)看到,在基於700億參數的模型上,Anyscale於各推論平臺上輸入了150個請求,同時計算它們每秒所回應的Token數量,而Groq的LPU推論引擎吞吐量即以185個Token,遠遠領先第二名Anyscale的66個Token。
.jpg)
現階段Groq支援標準的機器學習框架,包括PyTorch、TensorFlow及ONNX等,但僅用於推論,LPU推論引擎並不支援機器學習訓練。Groq歡迎硬體供應商、軟體供應商、雲端服務供應商或AI加值服務開發商尋求合作,也提供Groq API與Groq Compiler來執行LLM應用,使用者則可直接造訪Groq官網來試用其推論能力,目前官網上使用的模型為Llama 2與Mixtral。
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05