
郭又華攝
今(12/14)英特爾第五代Xeon Scalable伺服器處理器(代號Emerald Rapids)上市。英特爾強調,有意用此產品進攻AI運算市場,尤其是100億參數以下的AI推論運算。
第五代Xeon Scalable相較前一代的主要升級內容包括核心數從60顆增為64顆、DDR5記憶體傳輸速度從4,800MT/s增為5,600MT/s、L3快取(Last Level Cache,LLC)容量從112.5MB增為320MB、多顆處理器互連速度從16GT/s增為20GT/s,也正式支援CXL 1.1 Type 3裝置。原本外界預期這代CPU也會支援CXL 2.0,但這次並未正式註明支援。效能上,英特爾表示第五代Xeon Scalable相較第四代在一般運算、AI推論、高效能運算,以及網路和儲存吞吐量,分別提升了21%、42%、40%及70%。
資安做法上,英特爾機密運算技術TDX(Trusted Domain Extensions)在第4代CPU時只支援部分型號,現在則會支援第五代所有型號,且可以遷移TDX加密的VM到其他環境。第五代Xeon仍支援英特爾軟體防護指令集SGX(Software Guard Extensions),每個處理器與第四代一樣,最大可支援512GB容量的SGX Enclave。
第五代Xeon大多型號的最大熱設計功耗(TDP)與第四代同為350瓦。(唯一例外是一款液冷式型號,為385瓦。)不過,英特爾表示,第五代每瓦效能較前一代高出36%。不只如此,他們還進一步優化低CPU利用率(小於50%)時耗能。英特爾資深院士暨Xeon首席架構師Ronak Singhal表示,伺服器CPU常在20%至50%的低利用率運作。這個利用率範圍中,第五代耗電不僅較第四代低,在開啟能源優化模式(Optimized Power Mode)後,更能在利用率為30%的狀態下達到比預設模式省110瓦的節能幅度。
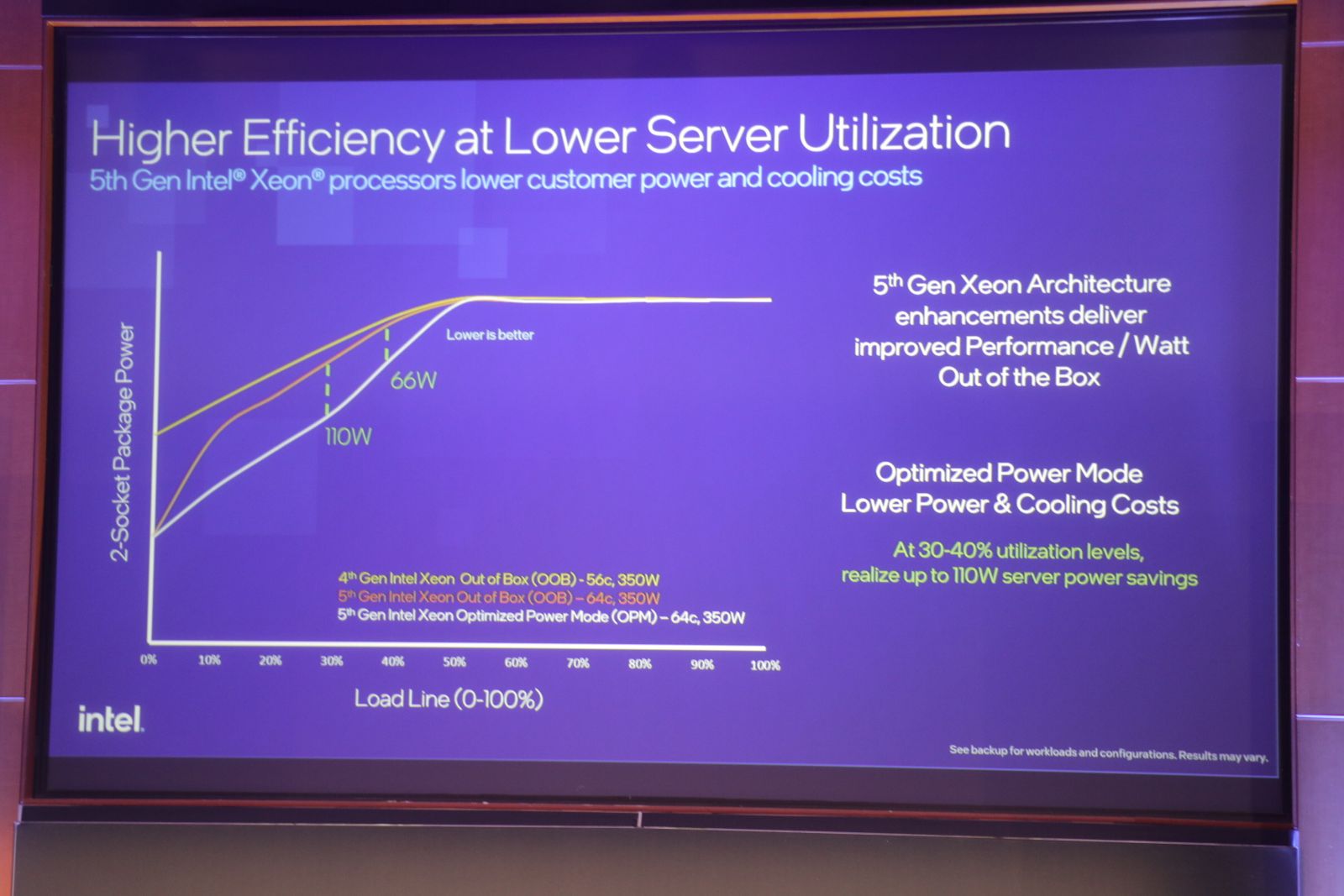
圖中是兩代Xeon Scalable處理器在不同CPU利用率下的耗電走勢。30%CPU利用率時,第五代能源優化模式可以額外節省110瓦。最上面這條折線是第四代預設模式、中間是第五代預設模式,最下方則是第五代能源優化模式。圖-郭又華攝
這一代Xeon Scalable與第四代同樣使用Intel 7製程,採用LGA 4677插槽,及採用Eagle Stream平臺,是此平臺最後一代CPU。英特爾預計明年推出的CPU Granite Rapids與Sierra Forrest則會改用Birch Stream及Mountain Stream平臺,插槽規格也會不同。
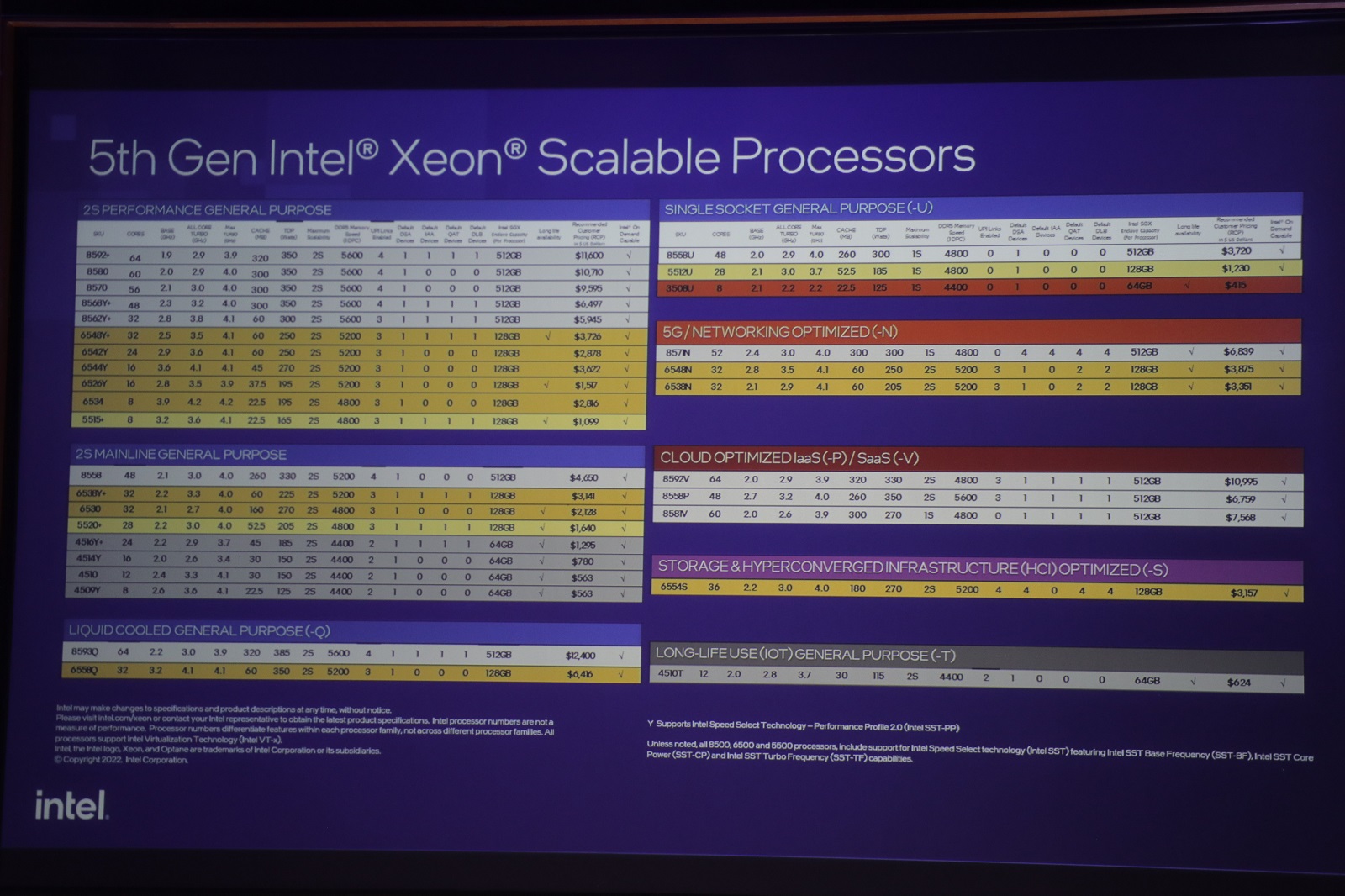
今天推出的Xeon Scalable中,英特爾公布了32款型號,涵蓋高效能、一般用途、5G網路、雲端等運算需求。圖-郭又華攝
主攻AI推論市場,鎖定100億參數以下的模型推論
英特爾強調,此代CPU有幾項規格升級尤其有利於執行AI推論任務。例如記憶體頻寬和LLC容量增加,以及支援CXL 1.1 Type 3記憶體擴展,對於要求高記憶體頻寬的推論任務都有幫助。AI推論任務注重時效性,因此降低運算延遲也相當重要。前一代Xeon從單晶磚改為4晶磚設計,到了第五代,晶片設計又精簡為雙晶磚(Tile)設計。英特爾設計工程事業群資深院士暨首席架構師Sailesh Kottapalli表示,雙晶磚設計好處在於,運算任務需要較少跨晶磚溝通,因此能降低延遲。
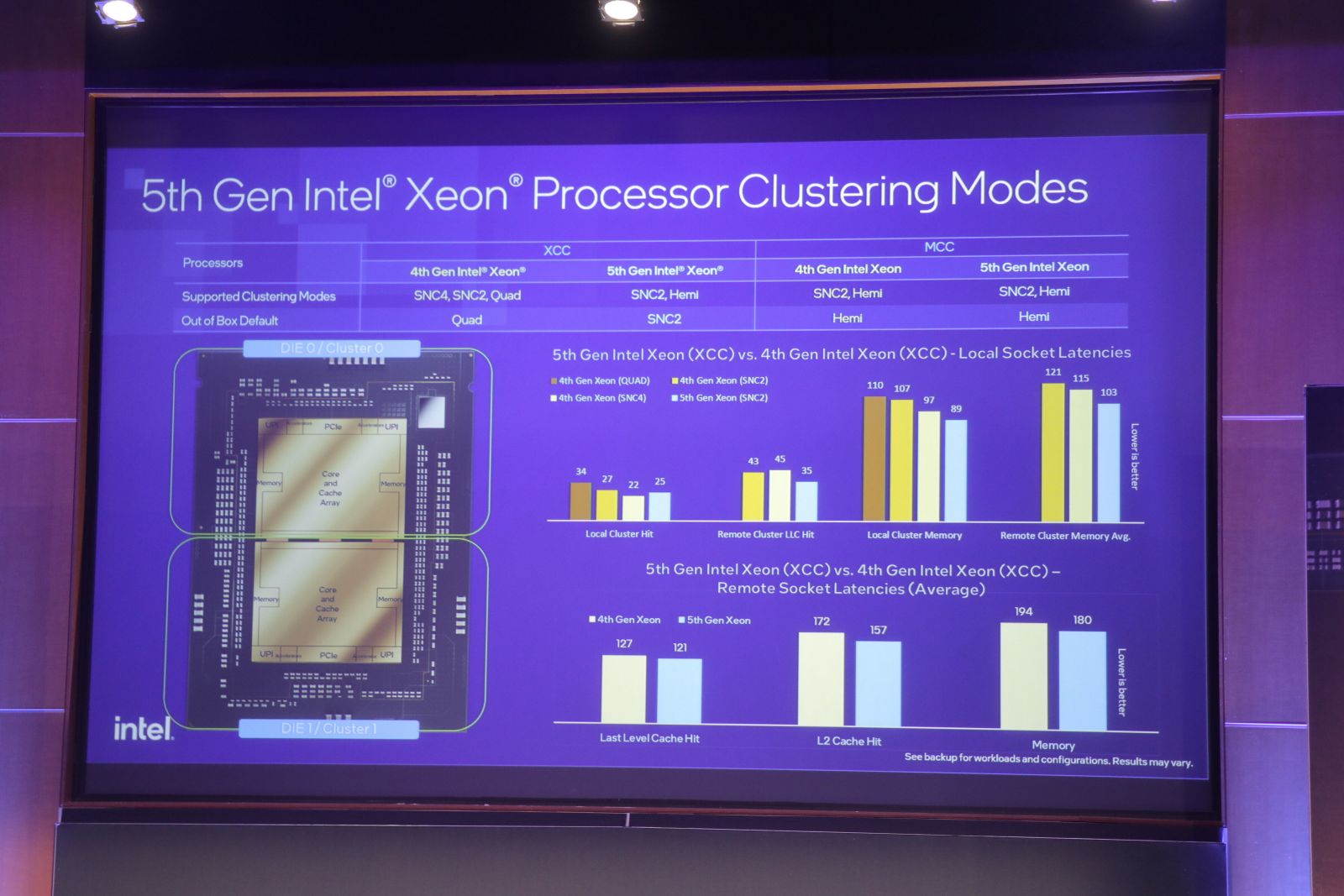
上圖中,英特爾呈現了採取雙晶磚設計的第五代Xeon,延遲較4晶磚設計的第四代Xeon更短。右下圖表可分為兩組,上方是本機延遲,下方則是遠端存取延遲。上半4個圖表中,左邊3直條分別為第四代Xeon不同晶磚利用模式的延遲時間,最右邊則為第五代延遲時間。存取L3、L2及記憶體的延遲時間上,第五代大多低於第四代6至20毫秒。圖-郭又華攝
他們還專門強化了新CPU在特定AI任務的效能。例如,英特爾資料中心效能及競爭力行銷處長Allen Chu表示,客戶通常要求AI推論任務延遲最高不能超過100毫秒。不過,這在研發第五代Xeon Scalable初期,是無法達到的目標,經過特別優化後,才將延遲壓在目標範圍內。根據他們內部測試結果,若應用在聊天機器人、搜尋及各式內容生成等任務,搭配60億參數GPT-J模型能做到延遲低於50毫秒,用更大一點的130億參數Llama2模型推論時仍低於75毫秒。
英特爾不諱言,第五代Xeon Scalable是瞄準100億參數以下模型的推論任務,因此他們強化CPU推論能力時,也聚焦在這個算力需求範圍。根據他們內部測試,應用在100億內參數LLM、推論模型及物件辨識模型的訓練、即時推論(Real time inference)及批次推論(Batch inference),第五代表現比第四代高出了20%至40%。
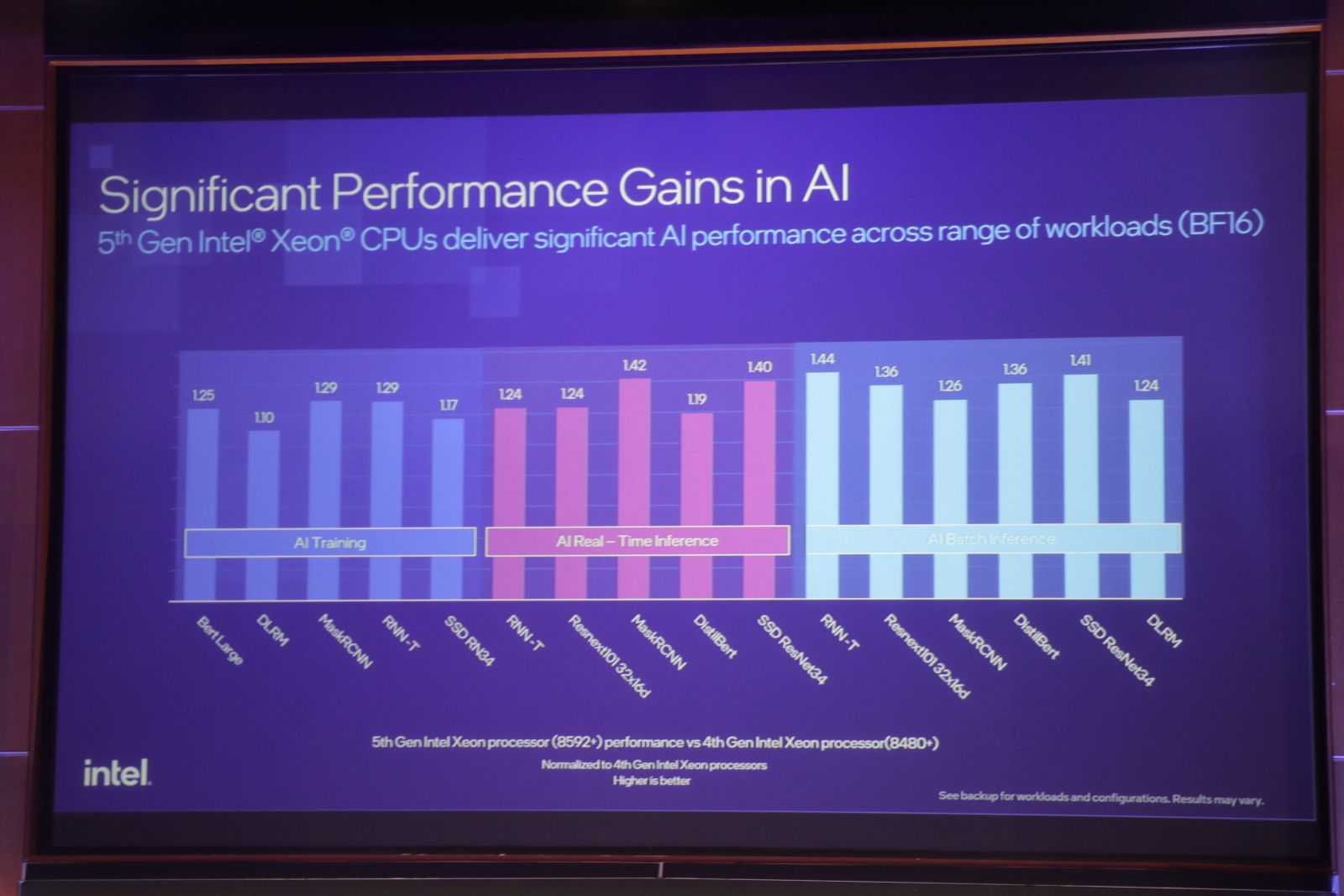
第五代在AI任務的效能相較前代都有不同程度的提升(10%到44%)。英特爾公布他們進行3種AI任務的效能測試數據,包括不同AI模型在訓練、即時推論(Real time inference)及批次推論(Batch inference)的任務。以執行RNN-T批次推論而言,第五代表現是第四代1.44倍。圖-郭又華攝
上面資料呈現了兩代間AI運算效能進步幅度,那麼,第五代執行常見任務具體來說會花費多少時間呢?英特爾舉一個內部實測案例說明,他們利用400億參數的Falcon模型來將西語書籍翻譯成英語版,由4個搭載2路第五代Xeon來執行離線推論任務。這本書有200萬字元、1,300頁,翻譯時間總共費時22分鐘。
針對雲地混合AI運算需求發展多種硬體產品及統一軟體開發工具
這次上市的新資料中心CPU,以及同日上市的電腦CPU Core Ultra,都是英特爾AI Everywhere產品布局一環。執行副總裁暨資料中心與AI事業群總經理Sandra Rivera表示,AI崛起是繼雲端崛起之後第二波算力需求暴增。他們認為,如今AI從學術研究和概念驗證開始落地,成為真正可帶來商業價值的技術,會為企業創造更多算力需求。舉凡金融、醫療、零售及製造,都是他們看到已經大規模應用AI的垂直產業。

英特爾對AI Everywhere的想像及軟硬體布局。圖-郭又華攝
Sandra Rivera說,AI算力市場中,有足夠資源和能力訓練大型AI模型的企業非常少,大部分AI使用者都是在做邊緣推論、模型微調,或是根據自有資料訓練特定用途小型模型。她也引述英特爾執行長Pat Gelsinger對整體AI需求的觀察:「多少人做天氣模型,又有多少人會用?這就是訓練與推論市場的差別,真正戰場在推論。」
英特爾有多看好邊緣推論市場?Sandra Rivera表示,他們預估AI推論市場成長幅度會是訓練市場2倍,尤其是於邊緣執行推論。企業邊緣推論需求來自於降低延遲、控制成本及能耗,以及確保資料隱私性。這個需求崛起,會促使雲地混合AI(Hybrid AI)模式成為主流,也就是將AI運算任務分散於雲端及地端,成為AI Everywhere的現象。
產品布局策略上,英特爾今日推出的Core Ultra及第五代Xeon Scalable分別是針對PC及伺服器AI推論需求的CPU。針對更強算力需求,則有Data Center GPU Max跟Flex系列,以及AI加速卡Gaudi系列產品。軟體方面,他們則是提供OpenVINO開發者工具,喊出「Write once, deploy everywhere」口號,要讓使用者只須寫一次支援AI模型及應用部署的程式碼,便能部署前述不同硬體環境。
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09

2026-03-09

2026-03-06