")
Uber大量運用開源Hadoop生態系技術來打造大數據平臺,作為上層各種數據分析應用和AI/ML應用所需。近年來數據量達到數百PB的規模,也帶來成本效益的挑戰。(圖片來源/Uber)
4年前,如果沒有下定決心改變戰略,靠大數據平臺媒合顛覆了全球交通產業的Uber,就算現在手上現金多達68億美元,恐怕也撐不到1年就會用光。
因為Uber手上大數據資料量在4年內暴增了100倍,從數PB,增加到數百PB。可是,Uber在2018年時,一年軟硬體IT支出高達12億美元,資料暴增百倍,若採用同樣技術架構,恐怕需要10倍,甚至是數十倍的軟硬體投資才能負擔。這正是4年前,Uber大數據平臺資深主任工程師Zheng Shao所率領的大數據成本效益團隊,必須解決的難題。
創立於2010年的Uber,創新的叫車服務快速在全球爆紅,2018年中累計超過100億趟,光是2020年一年就有50億趟。而在2015年推出的餐點外送服務Uber Eat,在2020年疫情之後反而成了主要營收來源,超越了Uber叫車服務。2020年,全球叫車與外送訂單總金額達到580億美元。Uber服務快速擴張,呈現爆炸式成長,也導致他們手上的資料也是指數型成長,不論是資料儲存和分析運算需求都年年大幅增加。
2014~2015第一代大數據平臺:用商用軟體打造資料倉儲平臺
2014年時,Uber的資料量約100GB左右,資料量還算不多,Uber一開始用傳統OLTP資料庫,例如 MySQL和PostgreSQL。當時開發者必須自行存取不同資料庫中的資料表,沒有跨資料庫的整體性資料管理或存取作法。
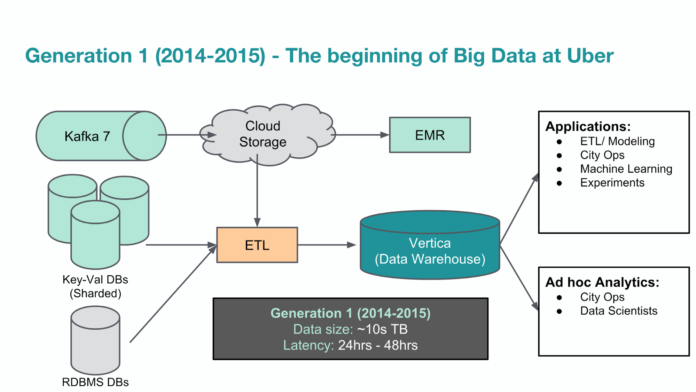
後來叫車業務開始大爆發,資料量成長到數TB,Uber採用商用資料倉儲軟體Vertica來建立資料倉儲系統,也開發許多ETL處理機制,來處理不同資料源,包括雲端S3或線上服務的Log等,也開始可以透過單一平臺來提供大數據資料的整體視野和存取管理,來支援上千人的數據分析和運算需求,例如城市維運經理,資料科學家或工程團隊。以資料倉儲來處理TB級的資料量,Uber第一代大數據平臺的延遲時間不到一分鐘內。有了這套好用的分析平臺,Uber分析性資料更是快速累積到數十TB,增加了10倍。
這套資料倉儲系統因為大量利用了特定ETL來獲取資料,但缺乏了與不同資料源開發團隊之間的溝通機制,代價是,資料可靠性變成一大問題,程式碼變動就會影響資料源。再加上Uber業務繼續快速成長,資料繼續暴增,也導致資料倉儲系統的費用越來越昂貴。可是,Uber第一代大數據平臺無法支援水平式擴充,因此,Uber經常得刪除舊資料,才能挪出空間來儲存新資料。再加上缺乏統一的資料格式,大量ETL處理所獲取的資料,得先多儲存一份來整理格式,才能確保資料品質,更讓Uber大數據平臺的儲存量嚴重不足。
下圖是Uber在2014~2015年間所用的第一代大數據平臺架構,主要利用商用資料倉儲軟體來打造,資料量最大達到10TB。
2016第二代大數據平臺:改用開源Hadoop打造資料湖
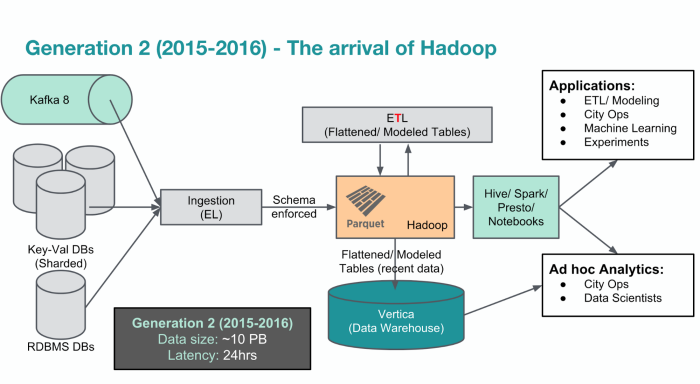
為了解決資料爆量的需求,以及越來越昂貴的平臺軟硬體支出,Uber改用了許多免費的開源Hadoop生態系技術,例如用HDFS打造資料湖,來重新架構第二代的大數據平臺,將所有線上服務的資料源的資料都集中到單一地方。這個架構可以提供高度的擴充能力來獲取海量資料。另外也引進Presto提供互動式的查詢引擎,或是用Spark來進行程式化存取資料的處理,也建置了Hive來提供超大型的資料查詢需求,並且採用了Hadoop主流的Parquet 檔案格式來取代JSON資料格式,來提高分析查詢的運算資源利用率。這些開源工具可以讓Uber第二代大數據平臺更有彈性,也更方便使用。
為了確保擴充性,在這個時期,Uber也將所有資料模型和處理都在Hadoop上進行,只有少數關鍵資料才多儲存一份到原本的資料倉儲系統中。如此一來,大大降低了資料倉儲的維運費用。這個Hadoop資料湖打造的大數據平臺,成了Uber所有分析資料的主要來源。
這時期的Uber處於業績高速成長的拓展期,省錢不是Uber當時最迫切的問題,而是開源Hadoop所打造資料湖可以採取水平式擴充架構,能夠支援數據大暴增的需求。Uber當時大數據平臺的資料規模已經達到10PB之多,比2014年資料倉儲軟體最初的100GB規模,足足大了10萬倍,Uber只有改用開源Hadoop才能滿足這個指數暴增需求。不只儲存量大增,運算量也暴增,為了處理高達10萬個批次處理任務,第二代大數據平臺的核心數更是多達上萬個。但是,為了這個海量擴充能力,第二代平臺犧牲了資料即時性,當時最大的缺點是延遲時間非常久,甚至得等到24小時後,批次運算才能得到結果,這對大量仰賴即時分析的叫車服務來說,非常不利。
下圖是Uber改用開源Hadoop生態系所打造的第二代大數據平臺架構(2015~2016),資料量已經暴增到10PB規模,是第一代後期10TB規模的1千倍。最大問題是批次處理的延遲時間長達24小時。
2017第三代大數據平臺:優化Hadoop效能支援即時分析
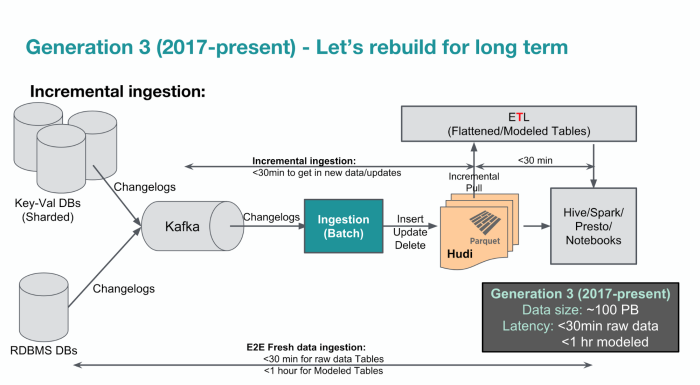
2017年,Uber大數據平臺資料量繼續成長,在HDFS叢集上累計超過了100PB,運算叢集核心數高達10萬個,每天有10萬個Presto查詢,1萬個Spark任務和2萬次Hive查詢。不過,因為Hadoop生態系軟體可以勝任這個架構的資料量,因此Uber決定繼續使用同一個平臺,但要開始展開效能和擴充性的優化。
特別是,當資料量達到PB等級時,HDFS叢集的NameNode會出現瓶頸,尤其儲存了大量小型檔案時,會開始影響效能。尤其資料量達到50~100PB時,這個影響就會變成大問題。因此,Uber採取一些分散式架構機制,例如NameNode Federation架構,或者將不同類型的小檔案切割分散到不同的叢集上來降低對效能的影響。
另外,Uber也開始重新思考資料處理流程,如何能因應即時資料分析的需求,想辦法來解決新資料得等上24小時的延遲問題,開始尋找方法提供更快的ETL處理和建模機制。
後來Uber打造出了Hudi專案,這是一個在HDFS和Parquet上的Spark函式庫,可用來處理龐大資料更新和刪除的維運問題,透過建立資料時間戳記,來對歷史性資料進行遞增式的維護,不用進行完整的資料表掃描,能讓新獲取資料的延遲時間,從24小時,縮短到1小時以內,以提供更即時分析之用。後來,Uber還聚焦資料品質,資料延遲,資料擴衝和可靠性繼續優化大數據平臺的機制,這些都是第三代大數據平臺的重要優化任務。
在持續改善大數據平臺之際,Uber開始大量使用ML和AI技術,利用這些技術來優化服務和用戶體驗。尤其Uber服務上的決策,都是利用資料,進行自動化精準判斷,從預估市場供需,到計算駕駛到達時間ETA,都需要靠AI。因此,2017年,Uber打造了一個分散式深度學習框架Horovod,更發展出自己的ML平臺稱為米開朗基羅,可以自動擴充,演化和延伸。可是,這些AI平臺和框架,都增加了大數據平臺的儲存和運算負載。2017年時,Uber大數據團隊最重要的任務就是,盡可能支援新應用和使用案例,讓大數據平臺的使用者可以享有跟過去一樣的可靠度,能夠營收持續增加時,不會出現問題。
下圖是Uber在2018年公布的第三代大數據平臺架構(2017~2018),繼續使用開源Hadoop生態圈技術,但開始考慮優化,將延遲時間縮短到1小時以內。
2019年11.5億美元IT支出,Uber大數據平臺最大宗的支出
以支援營運發展優先的大數據平臺發展戰略,對5年前的Uber而言,成本的問題不大,Uber大數據平臺資深主任工程師Zheng Shao在自家部落格上透露,因為2017年時,Uber大數據平臺的規模還小,只是Uber全球基礎架構的一小部分,但是不到3年,到了2019年初,大數據平臺成了Uber內部三大平臺中最花錢的一個。
根據Uber在2019年揭露的資料,2018年一整年,Uber在IT支出花了11.97億美元(相當於臺幣330億元),其中電腦硬體占了大宗,11.46億元,軟體費用只花了5,100萬美元。當時Uber已經改用免費的開源Hadoop生態系技術,但花在大數據平臺所需的運算設備和儲存設備需求上的IT支出仍舊非常高。到了2019年時,Uber大數據平臺的資料量更是達到100PB的規模,Hadoop叢集擁有2萬臺伺服器,多達20萬個vCore。還有2千臺Kafka主機,每天Presto和Hive平臺的查詢多達10萬次,Spark任務一天10萬件。
可是,2019年Uber營收不過13億美元,當年IT支出,包括軟硬體加起開就高達15.93億美元,比一年賺得錢還要多。如果,Uber繼續沿用同樣的Hadoop大數據技術架構,達到數百PB時,IT支出又需要暴增到什麼樣的天價,才足以負擔翻了幾倍的大數據平臺成長量?
所以,就在2019年,Uber下定決心,要改變「大數據平臺全力支援業務成長」的戰略,「我們開始認真思考,如何讓大數據平臺,維持一貫的可靠性、生產力和對業務的價值,又能降低成本。」Zheng Shao幾年後在技術部落格公開了這段經歷,他正是Uber大數據成本效益改善團隊的關鍵人物之一。
除了因為業務指數成長,導致資料大爆增之外,Zheng Shao剖析Uber大數據平臺燒錢的原因還有幾項。其中一項是為了因應災難備援而採取的Active-Active架構(雙A備援架構)。Uber 從2016年後,將大數據平臺從單一區域架構,擴展成AA架構,任何一項任務,一種是採取雙倍運算量模式(在兩個區域各執行一份相互備援),或者是採取單一運算加副本模式,也就是只在一個區域執行一項任務,而將輸出的資料集儲存在另一個區域中。
這樣的AA架構設計,的確讓Uber避免了兩次大數據平臺的大災難,一次是2017年夏天時,有一座資料中心冷氣故障事件,另一次則是人為操作錯誤,這兩次都因為雙A架構,只在一個區域出錯,馬上由另一個區域接手提供服務,對顧客沒有造成影響。
可是,「雙A架構的代價就是支出沒有效率,雙倍運算需要雙倍運算資源,單一運算加副本模式也要多備一份運算資源避免故障失效的備援,如何避免付出兩倍成本,或是否能將備用運算資源支援其他事呢?」Zheng Shao指出。
不只是AA架構的挑戰,如果要控制大數據平臺的成本,開始限制可用的硬體資源,要如何決定重要任務的優先度和QoS?如何確保遇到突發需求時,重要任務仍保有足夠的容量,不會因為過度節省而當機,或者能否善用臨時性的硬體資源來處理事後分析任務等,這得需要對使用者的大數據任務有詳細的了解,才能進行評估。 可是,Uber大數據平臺有數千位內部使用者,從資深技術專家到不懂技術的業務人員都有,還有如後端工程師、產品工程師、ML工程師、資料工程師、資料分析師、資料科學家、產品經理、商業分析師、城市維運人員、行銷經理等不同角色。
各式各樣來自不同產品線,不同部門的使用者,讓Uber無法更深入了解所有的使用案例,一旦要開始限制大數據平臺的容量或運算量時,很難決定哪些人應該獲得資源,甚至,2019年時,Uber也因為用戶組成太複雜而無法掌握資料的擁有權和彼此之間的相依性關係,這意味著,也就無法決定該由哪些人來負擔資料使用的成本,「龐大的異質用戶不利於降低成本。」Zheng Shao表示。
要解決成本問題,除了得想辦法減少硬體需求來節省成本,Uber大數據團隊也從另一個角度來思考,從提高硬體利用率著手,來提高成本效益。如果將大數據叢集的CPU平均利用率從30%提高到60%,Zheng Shao觀察,如果不會影響延遲性的需求,那就可以省下一半硬體,仍舊可以執行同樣份量的任務。但是在Uber大數據平臺的叢集中,P99(利用率達到99%)的機器數量,比P50的機器多了好幾倍,這代表了,工作負載的分配不均,叢集中經常出現不少熱機,也會大大影響了使用者體驗。如何提高一天的工作負載平均效率,固定一定比例的P99熱機數量,又能讓CPU平均利用率提高,同樣的工作負載需求下,就可以減少實體硬體的數量來提高成本效益。這是另一個Uber大數據平臺想要實現的成本效益改善作法。
另外,在2019年,Uber也開始考慮將大數據平臺上雲的可行性,為了更好的網路頻寬來支援水平擴充架構的Hadoop叢集,Uber大數據平臺完全部署在本地端,是否能改用雲端主機來節省成本,成了2019年Uber大數據團隊思考如何省錢的另一個也必須思考的課題。
靠分析CAP方程式評估成本效益的改善
經過這些大數據平臺成本效益不同挑戰和可能作法的評估後,Uber歸納出一個根本的成本效益衡量原則,若要提高大數據平臺的成本效益,就要同時考慮成本效益(Cost-Efficiency),準確度(Accuracy)和效能(Performance)三者的拿捏,這三者的相乘是一個常數,Uber將其稱為分析CAP方程式。
例如,使用抽樣作法來降低查詢結果的精準度,就能提高查詢效能也能增加查詢的成本效益。或者改用便宜硬體(成本效益高)來維持查詢的準確率達到100%,但就得犧牲效能。若用昂貴硬體(損失成本效益),但可以來確保效能和準確度。 透過這三個面向的思考,Uber利用這個方程式來思考大數據平臺的優化策略。 但更重要的是,「大數據成本效益問題,是一個必須整體考量的問題,而不能只是單點優化。」Zheng Shao強調,「否則,壓榨這一頭,另一頭就會變成瓶頸。」
所以,Uber後來發展出了三大省錢戰略框架,來分類這些各式各樣的成本效益挑戰。這個框架就像Uber在交通產業中的角色,在供應和需求之間扮演媒合平臺,Uber大數據省錢戰略,也分別從供應端戰略(用來執行大數據儲存和運算工作量的硬體資源如何優化)和需求端戰略(各式各樣的工作量需求如何優化)以及媒合大數據供應和需求之間的平臺效益戰略,從這三大戰略來提高成本效益。
2021年降低25%支出,更喊出3年後要大省一半
正是因為在2019年調整大數據平臺發展策略,開始重視成本問題,光是2019年第一年,就省下了數百萬美元的成本。Uber也繼續在2020年訂定了大數據省錢發展藍圖,經過2年努力,在2021年8月時,就達到大數據支出節省25%的成果,新的目標是要在未來2 ~3 年要將大數據支出減半,甚至,Uber要將這些大數據省錢做法,套用到線上服務,包括線上儲存,線上服務等。目前正和線上運算平臺團隊和線上儲存平臺合作,最終希望可以大幅降低Uber整體基礎架構的支出。

熱門新聞

2026-03-06


2026-03-11




2026-03-06

2026-03-09