
photo by Greg Bulla on unsplash
報導更新 臉書公布大當機始末報告:日常維護出錯所引發的骨牌效應
報導更新 臉書公布肇事原因:配置錯誤造成大當機
從臺北時間周二(10/5)凌晨12點20分左右,涵蓋臉書、Instagram與WhatsApp等臉書家族的服務同時中斷,且全球皆傳出災情,一直到早上7點多才逐步恢復正常。剛恢復平穩的臉書尚未公布肇事原因或是影響規模,Cloudflare則猜測,很可能是BGP惹的禍。
根據臉書今年第二季的財報,臉書家族的每日用戶數為27.6億,每月用戶數則達35.1億,顯示全球有接近一半的人口至少使用了其中一項服務。
該平台的故障不僅影響一般的臉書用戶,也影響了其它透過Facebook Login登入的應用。
此外,根據《紐約時報》的報導,這次的意外還波及到臉書內部的系統與工具,包含安全系統、內部行事曆、調度工具及內部通訊平台Workplace;員工不僅無法以工作手機打電話,也不能接收來自外部的電子郵件;有些員工甚至因為他們的數位員工證也失效了,而無法進入辦公大樓;另也派出一隊員工到資料中心,打算重啟伺服器。
雖然臉書的反應很迅速,但似乎都無濟於事,在當機發生的3個半小時之後,臉書技術長Mike Schroepfer透過Twitter表示,臉書遭遇了網路問題,團隊正在努力除錯與回復服務。
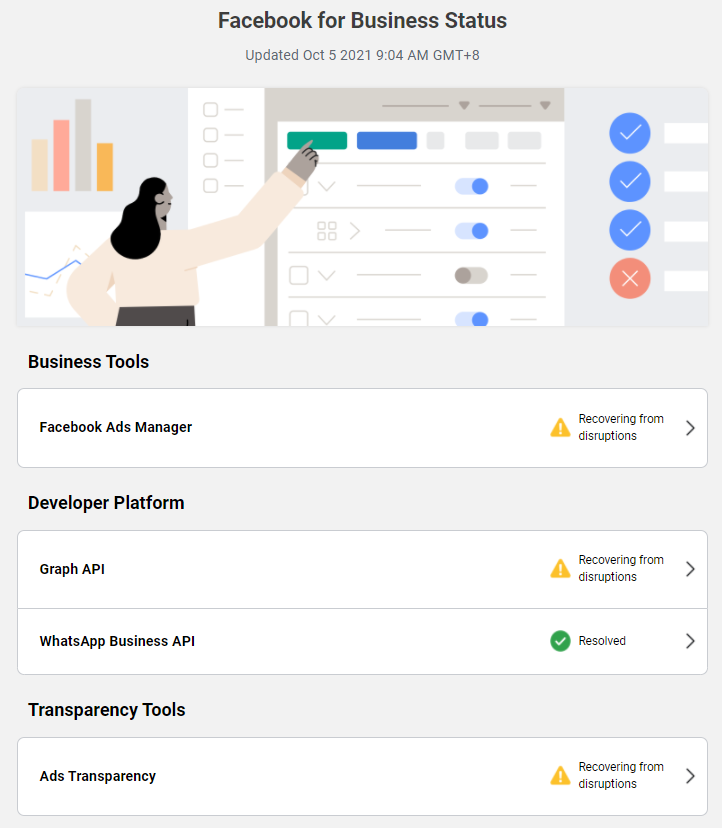
根據Facebook for Business今天早上9點更新的狀態,臉書的廣告管理工具與Graph API,皆仍處於故障的狀態。
雖然臉書並未公布當機原因,不過CDN暨安全服務供應商Cloudflare說話了,當他們查詢臉書DNS卻發現「服務失敗」(SERVFAIL)的回應時,原本以為是自己的DNS解析器1.1.1.1出錯了,正要張貼公告時,才知道不只是臉書,連WhatsApp與Instagram都當機了,它們的DNS名稱都停止解析,基礎架構的IP亦無法存取,彷彿像是有人把資料中心的所有線都拔掉了,使得它們同時從網路上消失。
Cloudflare認為,造成Facebook、Instagram與WhatsApp同時消失最有可能的因素是BGP。
BGP的全名為邊界閘道協定(Border Gateway Protocol),是全球網路自治系統(Autonomous System)之間用來交換路徑資訊的機制,這些讓網路得以運作的大型路由器不斷更新所有可能的路徑列表,以將每一個網路封包傳送到最終目的,少了BGP,路由器便不知自己該做什麼,全球網路亦無法運作。
Cloudflare說明,全球網路其實是由不同網路組成的一個大型網路,BGP扮演綁定它們的角色,它允許一個網路(如Facebook)向其它網路宣告自己的存在,在此次的事件中,Facebook並未宣告自己的存在,使得不論是ISP業者或其它網路都無法發現Facebook,因而無法存取。
每個AS會有自己的號碼(ASN),也會有統一的內部路由政策,AS可以產生前綴(控制一組IP位址),也能傳輸前綴(如何存取特定的IP群),每一個ASN都必須透過BGP向全球網路宣告自己的前綴路由,否則其它人就無法發現或連結。
但今天凌晨Cloudflare卻注意到Facebook不再發布其DNS前綴的路由,這至少代表Facebook的DNS伺服器停擺了,也讓1.1.1.1 DNS解析器無法再回應針對Facebook或Instagram的IP位址查詢。而且不只是1.1.1.1,Google的8.8.8.8或其它的公共DNS也都找不到Facebook、Instagram與WhatsApp。
其實Cloudflare在臉書家族當機的五個多小時之後,就重新在1.1.1.1上看到Facebook了,但要回到全球網路還需要多一點時間。
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-04

2026-03-02