,剛開始一人開發AI應用,從開發到部署全都自己來,直到資料工程師孫韻如(圖左)加入,才開始導入相關工具來輔助AI開發,將MLOps付諸實踐。(攝影/洪政偉)")
Line AI團隊的第一位成員蔡景祥(圖右),剛開始一人開發AI應用,從開發到部署全都自己來,直到資料工程師孫韻如(圖左)加入,才開始導入相關工具來輔助AI開發,將MLOps付諸實踐。(攝影/洪政偉)
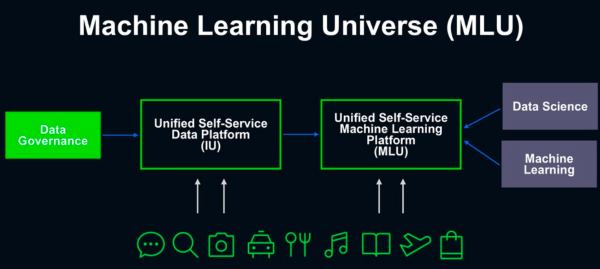
Line運用MLOps的概念,設計了AI開發的關鍵基礎架構平臺ML Universe(簡稱MLU),建立起如生產線般緊密分工的作業流程,要讓Line集團中的所有AI與IT團隊成員都能發揮所長,共同協作來提升AI開發的速度與品質。
這個由Line韓國總部建置的MLU平臺,Line臺灣團隊也參與了一部分的協作開發,去年中更正式導入了這套平臺,將各種ML應用遷移到MLU平臺中來加強協作。不過,在運用這套平臺之前,就如同所有剛起步的AI團隊,Line臺灣也經歷了一段摸索開發AI的時期。
從導入開發工具到採用ML協作平臺,Line臺灣資料工程部資深經理蔡景祥更進一步分享,Line臺灣如何從零開始逐步實現MLOps。
一人團隊:AI開發過度個人化成後續協作挑戰
蔡景祥回憶,Line臺灣在AI團隊成立之初,當時的團隊成員就只有自己一人,因此,他得身兼多種角色,同時擔任資料工程師、ML工程師、ML服務工程師,除了開發ML模型,更得開發API將模型部署上線。
雖然當時,所有的開發任務都只能靠蔡景祥自己完成,但也因此,他能清楚了解在ML開發的每一階段中,都做了什麼設置,也就不存在協作過程可能產生的溝通壁壘問題,「完全可以無縫接軌。」他說。
不過,儘管一個人開發ML的過程中,不存在協作挑戰,蔡景祥仍遇到了一些難題。比如在開發ML的前三個月,他就開發出第一版ML模型,卻在接下來調校模型時,發現成效不如預期,往後9個月甚至沒有前三個月來的有效率,「因為我要手動把ML Pipeline每一段都開發出來,非常花費時間。」
也是這時,他開始意識到,當前的開發方法有太多手動的操作,無法提高AI開發效率,且就算沒有他人插手,隨著開發時間不斷拉長,從第12個月回頭檢視第3個月所開發的程式碼,還是會忘記當時所做的事情。
不只如此,蔡景祥獨自開發AI約一年後,Line臺灣研發工程部資深資料工程師孫韻如成為AI團隊的第二位成員,隨著AI團隊從一人變為兩人,模型開發的複雜度也更加提升,因為兩人開始分工協作後,各有自己的開發方法,對彼此開發的程式碼也不了解,徒增了許多溝通成本。
「我們兩個開始分工後,就開始思考,是不是有一些方法論,能去較好的定義每個ML工作階段,以及是否有些工具,能輔助每個階段的進行?」蔡景祥發現,當前的AI開發過於個人化,對兩種角色以上的AI團隊來說,尤其帶來挑戰。
兩人團隊:根據協作痛點導入AI開發工具
面臨了協作需求後,Line臺灣決定開始實作MLOps。當時,孫韻如負責研究這類解決方案,發現市面上已經有些開源工具或軟體,能在不同開發階段促進不同角色的協作,於是,針對實作ML過程中遭遇的痛點,Line臺灣逐步將相應的開發工具導入ML開發工作流中。
比如剛開始,Line臺灣遇到的最大問題,是參數調校的版本控管問題。蔡景祥解釋,要提升模型的準確率,哪怕只是1%而已,都需要歷經多次的參數調校與實驗過程。不過,Line臺灣剛開始,是用Excel來抄寫每一個版本的實驗資料、參數及模型表現,隨著實驗次數增加,這種手抄記錄方法逐漸不敷使用,造成效率低、易出錯的問題,且角色分工時,更會礙於無法充分解釋每一步驟的用意,導致分工難以進行。
為此,Line臺灣導入了模型訓練的版本控管的工具MLFlow,來自動記錄實驗記錄,讓開發者可以輕易比較每一個版本實驗結果,更容易進行版本控管。
而後,Line臺灣面臨到另一個問題,是在進入模型部署階段時,團隊需要將模型服務打包成API,或是進行其他工程端的開發,但是,這對資料科學家來說,具有一定的開發門檻,若交由工程人員協作,又會產生額外的溝通成本。
「所以我們開始研究,有沒有工具能將模型快速打包成API來部署,同時又能兼顧穩定性?」蔡景祥表示,Line臺灣後來導入了KFServing,讓資料科學家能較輕易的自行部署模型,讓資料科學家能更專注在模型開發的工作上。
談到這裡,孫韻如特別指出,MLOps沒有一種標準化的導入方式,而是強調AI協作的概念,Line臺灣選擇的導入方法,是針對AI開發遭遇的痛點或協作挑戰,導入輔助的開發工具來克服,但不同企業的AI團隊,可能發展出不同的MLOps實作方法,「因為他們的痛點不一樣,就會導入不同的工具來因應。」
與總部協作,共同實踐MLOps
就在Line臺灣花費了一段時間,導入了版本控管與模型部署的工具後,臺灣AI團隊在一次與韓國總部的會議中,發現總部也同樣面臨了AI開發過於客製化的挑戰。當時,總部正著手導入相關開發工具,也更全面的規劃了ML Pipeline的角色分工與工具支援。在了解到彼此都有導入MLOps的需求後,雙方也一拍即合,展開了更進一步的協作。
蔡景祥表示,協作過程中,由總部作為主導的一方,將雙方在ML開發工作流各階段導入的工具,進行整合,也參考外部的最佳實例,內化為自身的作法,來打造一個整合多項工具的ML開發平臺,「我們希望,透過各種開發工具的輔助,能將參與到AI開發的所有角色,全部在平臺中串連起來。」
這套ML平臺,除了整合多項開發工具,能在平臺上直接呼叫來使用,而不用擔心個別軟體工具的部署與環境設定,更將部分工程端的程式開發環節,透過使用者介面的編輯器功能來取代,讓使用者能透過拖拉設定的方式來建立ML Pipeline,減少AI與IT人員的協作成本,可說是MLOps更進一步的體現。
ML平臺建置完成後,從原先的專案名Jutopia,正式命名為MLU,更與Line先前建置的資料平臺IU(Information Universe),共同作為AI開發的關鍵基礎建設。Line臺灣大約在去年年中,正式導入這個ML平臺,除了韓國之外,其他如日本、中國、泰國等地的AI團隊,也都逐步將ML專案轉移到該平臺上,截至去年7月,超過30個團隊、上百名工程師都已經採用。
擴散到各地AI團隊採用後,若各團隊發現,有些需求仍無法被滿足,也能向總部回報,由總部持續完善整個平臺。孫韻如就舉例,雖然MLU平臺已經與IU平臺串接,能取得各類經去識別化的資料來運用,但在實際的ML開發場景,仍有些資料並非來自於IU,而是其他的儲存空間,這時,就得請總部擴大整合更多資料儲存空間,以便開發者能直接從MLU設定,來取得所需的資料。
「因為每個ML專案的資料來源與服務性質都不一樣,如何讓平臺更加通用,就是MLU平臺的開發挑戰。」孫韻如表示,MLU建立的目的,就是要滿足各種各樣的AI開發需求,讓Line開發的AI應用,都能透過MLU實現。
Line建置了資料平臺(IU)與ML平臺(MLU),作為AI開發的關鍵基礎建設,來建立大多Line服務背後支持的AI應用,比如從Line Today、Line TV、Line Music到Line購物的個人化推薦,聊天訊息的事實查核機制,照片轉文字的OCR辨識功能都在其中。圖片來源/臺灣Line
MLOps協作還需納入業務端,成MLU平臺下一步挑戰
儘管MLU平臺已經整合了多項工具,加強AI開發與維運端的協作,但是對於開發端與業務端的協作仍有精進空間。蔡景祥認為,現行的ML開發流程中,對於ML模型的解釋度還不夠。
「AI開發跟一般軟體開發的最大不同,在於實作出ML模型後,模型表現會產生偏移,」蔡景祥指出,這是AI開發的特性,但也正因這種不確定性,會讓資料科學家難以解釋模型決策的原因,尤其,在向非技術專業的應用端人員解釋模型預測成效時,若沒有工具來輔助解釋,就可能帶來溝通上的挑戰。
雖然,目前MLU平臺已經整合了相關工具,能進一步分析訓練資料的特徵對模型決策的權重,來試圖解釋ML模型做出不同決策的原因。但蔡景祥仍認為,在模型表現的解釋上,技術上還是有其挑戰性,MLU平臺也還能未整合更多可解釋性AI工具,來提供業務單位更直觀的洞察。
「AI開發的本質,是要解決一個商業問題,」蔡景祥反問,要如何證明,透過ML模型真的解決了一個商業問題?或是向業務單位交代,這個問題是礙於哪些原因而無法解決?這才是業務單位真正關心的事。
因此,蔡景祥期許在未來,MLU平臺能整合更多模型分析工具,來增進技術人員與業務人員的協作,除了提供解釋模型預測力的視覺化工具,甚至能量化使用ML後的成效數據,比如能增加多少瀏覽量、降低多少成本,來進一步說服業務單位使用該預測服務。
完整系列報導在這裡
熱門新聞

2026-03-06



2026-03-06

2026-03-09

2026-03-09

2026-03-09
