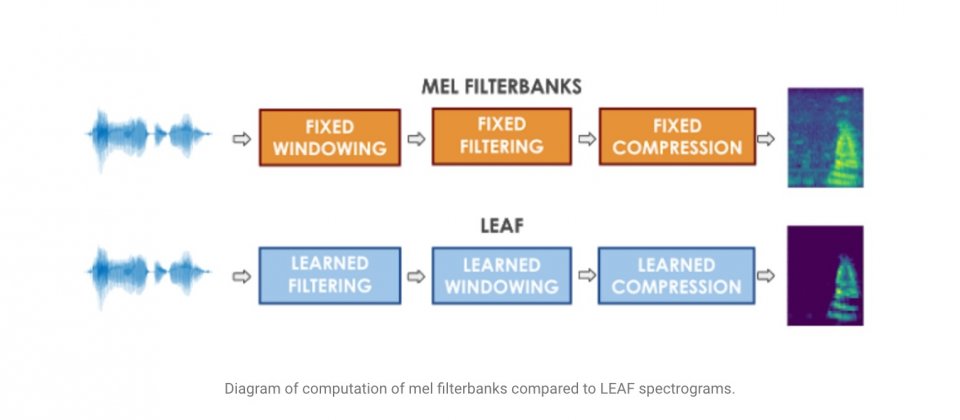
Google重新設計用來處理音訊分類任務的方法,發表了可學習的音訊前端LEAF,用來取代過去預處理音訊的方法梅爾濾波器組(Mel Filterbanks),以更好地處理像是分類鯨魚叫聲等音訊分類任務。
過去幾年,語音理解機器學習模型有了巨大的進展,透過從資料中學習參數的能力,該領域已經逐漸從過去複合手刻的系統,轉變成為深層神經分類器,用於語音辨識、音樂理解以及動物聲音分類等任務。但Google提到,用於音訊分類的深度神經網路跟電腦視覺模型不同,電腦視覺模型可以從原始畫素中學習,但是音訊分類深度神經網路很少使用原始音訊波型訓練。
音訊分類深度神經網路仰賴梅爾濾波器組預處理資料,這些濾波器使用經特別設計的梅爾縮放頻譜,目的是要複製人類聽覺回應的某些部分,雖然對梅爾濾波器組建模,過去的機器學習應用都很成功,使用固定梅爾縮放和對數壓縮,在一般情況也都效果良好,但是Google認為,沒有辦法保證這些也可以被良好應用到其他的任務上。
在與人類感知相對應的應用領域,像是語音辨識和音樂理解,目前標準梅爾濾波器組都提供了良好的歸納偏差,但是這些偏差可能對不需要模仿人耳的領域,像是辨識鯨魚叫聲這類的任務造成負面影響,所以為了獲得最佳的效能,需要為特定任務量身訂做梅爾濾波器組,但這是一個繁瑣的過程,不只需要專家知識,還需要許多迭代工作,因此在多數的音訊分類任務,開發者還是偏好使用標準的梅爾濾波器組,即便可能無法產生最佳的結果。
為了解決這個問題,Google提出梅爾濾波器組的替代方法LEarnable Audio Frontend(LEAF),這是一個神經網路,可以初始化逼近梅爾濾波器組,並且與任何音訊分類器一起訓練,以適應特定任務。
Google將LEAF應用在各種音訊分類任務上,包括語音辨識、說話者辨識、樂器辨識和鳥聲辨識,LEAF的平均效能比起梅爾濾波器組,以及其他可學習前端,如Time-Domain Filterbanks、SincNet和Wavegram都還要好,在不同的任務上,LEAF的平均準確率達76.9%,而梅爾濾波器組的平均準確率則為73.9%。Google使用TensorFlow 2實作LEAF,現在已經在GitHub儲存庫開源。
.png)
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-03

2026-03-02

2026-03-02