
此為一般深度學習推薦模型的組成圖,綠色區域為推薦模型的基線,黃色區域則是臉書團隊提出的模型壓縮設計TT-Rec,可取代綠色區域來縮小模型。
臉書
重點新聞(0219~0225)
推薦模型 模型壓縮 臉書
推薦模型太大跑不動?臉書最新壓縮術讓模型縮小成百分之一
臉書聯手喬治亞理工學院(Georgia Tech),發表一項推薦模型縮小術,可將模型大幅壓縮至原本的112分之一,且表現不受太大影響。這個方法叫做TT-Rec,是深度學習推薦模型(DLRM)張量訓練的縮寫,TT-Rec專門用來縮小耗費記憶體的推薦模型,讓大規模部署變得更容易。它的創新之處,在於用張量分解(Tensor train decomposition)的矩陣乘積序列,來取代推薦模型的大型嵌入表(Embedding table)。
推薦模型幾乎是內容大廠的標配,比如YouTube、Netflix、臉書等,其中,推薦模型由2大部分組成:多層感知器(MLP)和嵌入表。MLP負責處理連續性特徵,如使用者年紀,嵌入表則將稀疏、高維度的輸入值,編碼成高密度的向量示例,來處理類別型的特徵。但現今產業所用的推薦模型嵌入表,記憶體耗費量從GB等級躍升到TB等級,以臉書的推薦模型來說,光是嵌入表就占了99%的容量,若加入新的推薦模型,所需的記憶體容量又會成指數成長。
為解決問題,團隊設計了TT-Rec壓縮技術,用張量分解來取代嵌入表。團隊比喻,這個方法就像是用查詢表(Lookup table)來換取記憶體容量和頻寬。為評估,團隊訓練了MLPerf-DLRM,用TT-Rec後可縮小為原本的112分之一,而訓練時間只增加13.9%。目前TT-Rec已於GitHub上開源。(詳全文)
雲象 全玻片辨識 Nature Communications
不必再切割和標註了!雲象新方法讓電腦一次就懂上億畫素的病理全玻片影像
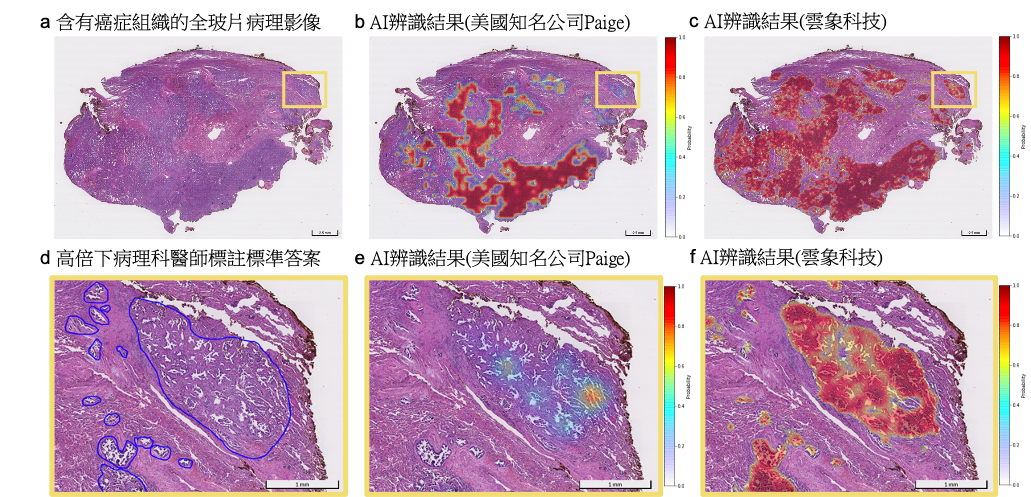
數位病理AI新創雲象科技費時3年研究,終於找出新方法突破算力障礙,讓深度學習模型可以上億畫素的全玻片影像來訓練、判讀,不必像過去要切割影像才能做得到;這個研究成果,最近也登上國際頂級期刊Nature Communications。
雲象科技執行長葉肇元指出,數位病理AI一直有個瓶頸,也就是難以完整的病理全玻片影像來訓練。這是因為,全玻片影像是由許多顯微鏡下放大的視野拼接,解析度可達數十億,要用這些影像來訓練深度學習模型,非常耗費記憶體和時間。而傳統方法是將影像切割為多個區塊(Patch),以低畫素(如256*256或512*521)影像來訓練模型、讓模型判讀。但這個方法,需要在每個區塊進行標註,因此相當耗費醫師人力。
於是,雲象決定找出方法,讓AI模型可用未標註的全玻片影像來訓練,並進行判讀。他們先是解決記憶體問題,在訓練階段,讓電腦不只運用GPU記憶體,還加上系統記憶體來一起解析影像。接著,他們再以資料搬遷方法,來解決速度慢的問題,比如優化算圖(Computation graph)、將計算工作分群分階段,降低資料在GPU和系統間搬遷的頻率,此外,他們也採用Pre-fetch,將下一階段所需的資料,提前搬到GPU記憶體。最後,他們運用科技部巨量醫療影像計畫中的9,000多張肺癌影像資料集,用近5億畫素的全玻片影像來訓練AI模型並辨識癌症和分類,發現AUC高達0.959,優於現有最佳方法。這個成果的意義,不只AI全玻片影像訓練和判讀,更重要的是不需人為標註。 (詳全文)
Transformer 蛋白質 長序列
Transformer不只突破NLP天花板,還完勝蛋白質預測權威方法
「這是Transformer架構的巨大進展!」臉書AI首席科學家、CNN之父Yann LeCun日前在Twitter上寫道。這次,臉書AI研究院聯手柏克萊大學和紐約大學,利用Transformer來預測蛋白質接觸的結構變化,而且,輸入值不只單一個蛋白質序列,而是好幾個。
3年前,Transformer架構因Google BERT聲名大噪,在NLP領域寫下里程碑。這次,臉書團隊用Transformer來解決半世紀難題:蛋白質結構預測。一般來說,蛋白質結構預測常用神經波茨模型(Neural Potts Models),透過共享參數來模擬多個蛋白質家族的分布,後來因未標註序列資料集的誕生,延伸出另一種新方法,也就是非監督學習的蛋白質語言模型。但缺點是,它一次只能輸入一個蛋白質序列,因此需要大量參數。
為解決問題,臉書團隊開發MSA Transformer模型,能一次輸入好幾對對齊的蛋白質序列,並跨序列家族共享參數。簡單來說,團隊把Transformer預訓練擴展到MSA演算法上,將Transformer強大的配對能力用來對應序列內的交互作用,成為殘基對殘基的對應圖。經測試,團隊發現MSA Transformer模型在非監督蛋白質接觸預測上,完勝現有高階蛋白質語言模型和傳統的Potts模型。(詳全文)
Google 機器學習模型搜尋 Model Search
找模型好麻煩?Google開源模型自動搜尋工具幫你挑最好的
Google開源機器學習模型搜尋平臺Model Search,要讓研究社群更容易找出適合特定問題和資料集的ML模型、大幅減少程式開發時間與工作量。
Google表示,好用的類神經網路(NN)有賴於泛化任務的能力,但要做到這一點很有挑戰性,因為社群理解有限。比如,適合解決特定問題的NN,會長怎樣?要多深?隱藏層只用LSTM就夠了,還是要結合Transformer?因此,這幾年出現許多AutoML演算法,比如NAS、演化演算法、RL等,要將這段重手工的過程自動化,但這些演算法需要大量算力,又是一大負荷。
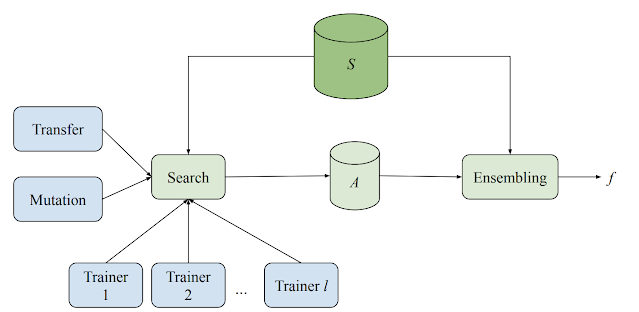
為此,Google研發Model Search平臺,由多個訓練程式(Trainer)、搜尋演算法、遷移學習演算法和用來儲存各種評估模型的資料庫所組成,能以自適應的方式,執行各種機器學習模型的訓練工作和評估實驗。Model Search中實作的搜尋演算法具適應性、貪婪和漸增特性,所以收斂的速度比RL要快,也能模仿RL,因此兼具深度與廣度,能更快找到最佳結果。Google也將Model Search用來探索關鍵字標記與語言辨識模型,不到200次迭代,就能獲得比專家設計更好的模型,少用了13萬可訓練參數。最後,Model Search以Tensorflow建成,可在單機或分散式裝置中運作。(詳全文)
蘋果 聯合學習 FE&T
蘋果研發裝置通用聯合學習系統FE&T
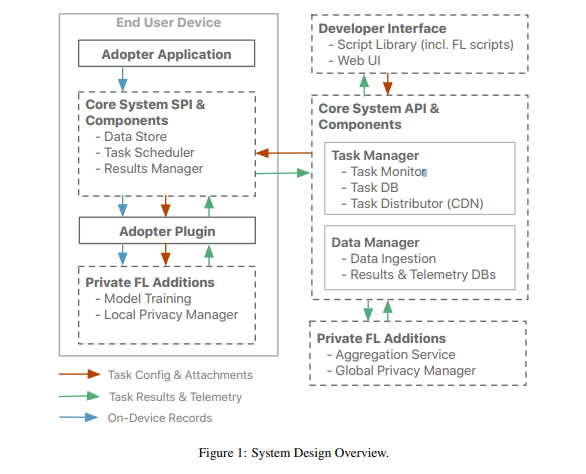
蘋果研發一套在裝置上執行的通用聯合學習系統FE&T,讓資料在不離開裝置的情況下,在個別裝置上改善特定分能的準確率。FE&T包含了資料儲存器、任務排程器、成果管理器,其中,資料儲存器有一套資料保留策略,確保裝置上留存的資料是有限的、最近的,而任務排程器則會定期下載一系列描述器,最後的成果管理器則會回傳任務結果,並在裝置上產生一個資料庫,讓終端使用者檢視哪些資料是與中央伺服器分享的。(詳全文)
LinkedIn 會員大數據 銷售分析
LinkedIn靠7億會員大數據推出銷售分析平臺
LinkedIn正式發布分析平臺Sales Insights,運用LinkedIn上7億多筆會員資料,來提供銷售團隊即時分析數據。銷售主管可透過Sales Insights掌握企業分布和即時人力資源,包括特定區域的企業、企業員工特性,來了解這些人所需的產品和服務。
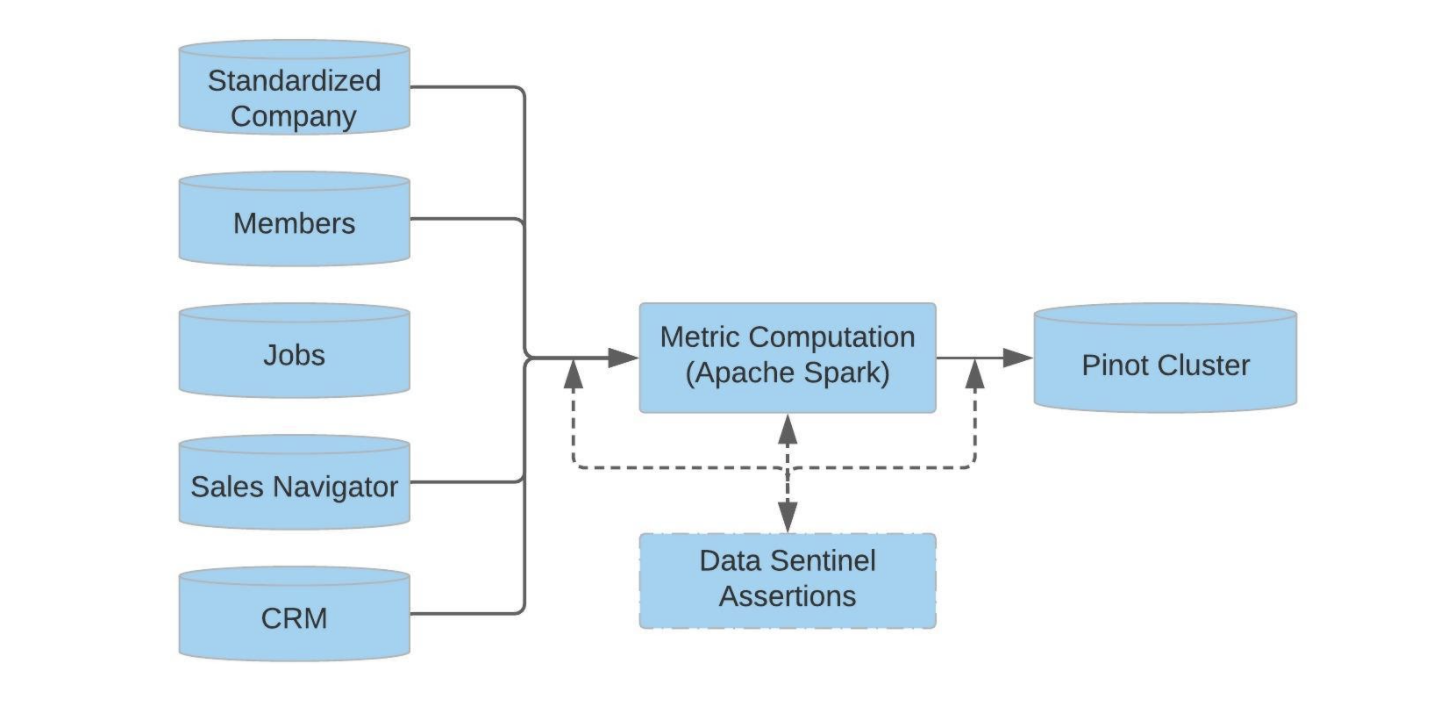
Sales Insights運用LinkedIn Economic Graph資料集,來反映人、企業、技能、工作和學校等各種實體間的關係,而且,該平臺透過分析帳號、市場與關係強度等資料,讓銷售團隊將資源集中在最有機會的客戶上。其中,平臺也運用多種AI和資料探勘技術,來清洗、整合資料,確保資料正確性,並透過AI自動配對公司屬性,將乾淨的資料整合進企業CRM系統。(詳全文)
未知的未知物 群眾外包 影像辨識
Google要藉群眾外包力量打造未知物資料集,改善AI辨識力
Google發起機器學習群眾外包不良測試集CATS4ML挑戰,要挑戰者以創新方法,來改善ML模型辨識未知的未知物(Unknown Unknowns)能力。Google指出,影響ML模型表現的兩大關鍵是演算法和資料,而資料又可分為訓練資料和評估資料,現有的評估資料卻過於直白簡單,往往忽略現實世界的模稜兩可性,造成辨識弱點。
這弱點又可分兩種,包括已知的未知和未知的未知,前者是指模型無法確定的分類,後者是指模型分類錯誤的例子。於是,Google發起CATS4ML挑戰第一版,要收集未知的未知物資料集,用來評估ML模型辨識能力。目前第一版鎖定電腦視覺,挑戰者可透過資料集現有的標籤,來找出未知的未知物,或以創新的方法來探索資料集。(詳全文)

圖片來源/雲象、蘋果、Google、LinkedIn
AI趨勢近期新聞
1. Google雲端整合資料科學平臺Databricks
2. AWS加入開源框架PennyLane指導委員會,要融合機器學習和量子運算技術
3. Google開除另一位AI倫理研究員Margaret Mitchell
資料來源:iThome整理,2021年2月
熱門新聞

2026-03-02

2026-03-02


2026-03-02

2026-03-02

2026-03-02

2026-03-02

2026-03-03