
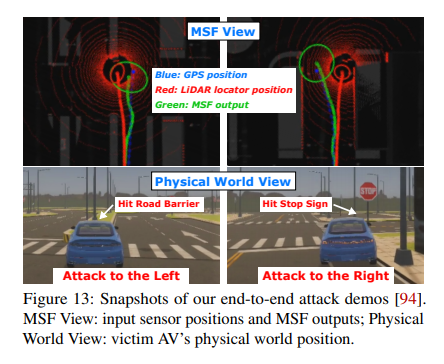
加州大學Irvine分校發現,自駕車用的定位MSF演算法雖能阻擋GPS干擾,卻有著接管漏洞。團隊研發一套攻擊FusionRipper,在模擬環境中以91.3%的成功率改變自家車的軌跡。
UCI
重點新聞(0122~0128)
自駕系統 MSF演算法 FusionRipper
自駕上路出現鬼飄移?加州大學揭露自駕車定位AI演算法有漏洞
全球吹起自駕風,Google Waymo One和百度Apollo Go就分別在美國和中國,提供高度自駕的Level 4自駕計程車服務。這種高度自駕的系統,不只要能感知周遭障礙物,還要能以公分等級的精確度,在地圖上定位自己。這種定位對自駕車來說至關重要,因為定錯位會導致開錯車道或走錯路。
這種定位系統的關鍵是MSF演算法,也就是融合多種感測器資訊的演算法,早期用來防範GPS干擾攻擊(GPS Spoofing),但現在卻少有人討論它在自駕車的安全性。
於是,加州大學Irvine分校研究了MSF演算法用於自駕車的安全性,發現MSF演算法雖能有效防止GPS干擾攻擊,但卻有個致命缺陷,也就是接管漏洞(Take-over vulnerability)。因此,團隊設計一套新式的通用攻擊FusionRipper,來評估它對MSF演算法的影響。
FusionRipper分為兩階段攻擊,首先是觀察漏洞出現的時機,再來藉機干擾。團隊發現,在Trace-based實驗和模擬測試中,FusionRipper的成功機率分別是97%和91.3%,都能讓自駕車偏離道路。目前,團隊已與29家自駕車業者聯絡,有17家開始調查,1家開始修復。(詳全文)
ImageNet 胸部X光片 SaMD
吳恩達花4年學到的一件事:ImageNet預訓練表現越好,並不會讓DL模型更擅長X光判讀
4年前,AI大師吳恩達帶領史丹佛大學團隊,打造出讓人驚豔的醫療AI模型CheXNet,可在胸部X光片上標出肺炎病灶,準確度高過放射科醫生。4年後,用來偵測胸部X光片的深度學習(DL)模型,大多靠遷移學習來完成訓練,也就是先以大型資料集ImageNet來預訓練,再用少量醫療資料來訓練、優化模型。這就是假定ImageNet預訓練模型的參數,可讓模型表現更好,而且用ImageNet訓練出的模型架構,一定更會判讀胸部X光片。
不過,吳恩達與史丹佛大學學生發現,事實並非如此。他們用16種熱門的CNN模型和CheXpert資料集中的5種X光片判讀任務,來評估ImageNet遷移學習和參數效率,這些模型包括DenseNet、ResNet、Inception、MNASNet和EfficientNet。
他們得出4個結論:首先,不管有沒有預訓練,模型在ImageNet上的表現和在CheXpert的表現,都沒有任何關聯,也就是說,以ImageNet改善的架構,並不會改善模型在胸部X光片的判讀表現。再來,在沒有預訓練的情況下,模型家族類別其實比模型大小,更容易影響表現;第三,ImageNet預訓練可提升整體架構性能,特別是小型模型架構。最後,若捨棄ImageNet預訓練模型的最終層數,來縮小模型,在統計學上並不影響模型X光判讀表現,且平均可提高3.25倍的參數效率。(詳全文)

MLaaS 電商 模型穩定性
林守德:訓練數據難完美,MLaaS要支援數千個模型,不斷反覆建模是最大挑戰
為了加快開發和翻新AI應用的速度,來因應快速變化的顧客行為,越來越多企業開始建置自家的機器學習即服務(MLaaS),將機器學習模型變成一個容易重複利用的服務架構。
不過,Appier首席資料科學家林守德指出,打造MLaaS的挑戰是模型建構。通常,ML的模型研發多聚焦於單一模型的設計,也就是用一組數據來訓練模型,再用測試數據來預測。但現實狀況是,為滿足真實世界中不斷變動的顧客需求,企業用來訓練和測試的數據不能清楚地一分為二,因為,今天用來測試的數據,很可能成為明天用來訓練的數據。除了來源不完整,訓練資料也存在一定的偏見,比如,用來訓練推薦模型的數據,通常來自另一個推薦系統蒐集到的反饋;正因為訓練模型的數據存有另一個模型的影子,偏見不可能消失。
此外,用來預測結果的數據,非常複雜。以電商為例,常見的用戶旅程是點擊商品、查看商品、加入購物車、購買商品,但系統紀錄的軌跡並非如此簡單。因為,消費者可能在不同設備上多次查看某件商品,也可能將商品從購物車移除後,再重新加入,甚至,得知用戶是否購買,會比取得其點擊或瀏覽的數據更加困難,因為顧客可能在別的平臺上結帳。
因此,模型訓練數據不可能完美,也難以用完全乾淨的資料來預測。林守德認為,對打造MLaaS的企業來說,每天得維持數千個模型在線上提供服務,且須不斷再訓練模型、更新數據,好讓模型因應現實中不斷變化的任務。也就是說,模型開發者不僅要完善模型自動訓練的流程,還得確保模型發生局部誤差的機率接近零,才能持續滿足客戶的業務目標。他總結,這是非常有挑戰的任務,需仰賴不斷的投資、研究和實驗才能辦到。(詳全文)
文字生成 表格文字 ToTTo
如何讓NLG更精準?Google最新NLG表格文字資料集有方法
Google近日發布一套表格轉文字的自然語言生成(NLG)資料集ToTTo,以新穎的標註方法和特殊的文字生成任務所打造,可用來評估NLG模型幻覺程度(Hallucination,也就是模型產生出可讀的文字,但不忠於源語),幫助NLG模型產生更精準的文字。
Google指出,過去幾年,NLG研究有長足的進展,比如文字摘要。雖然NLG類神經網路系統能以流暢的文字表達,但仍會產生幻覺,讓這些系統難以用於講究文字精確性的領域。為改善這個問題,Google用結構化表格,來評估生成文字是否終於源語,並要求註釋者分階段修改現有維基百科的句子,讓句子乾淨又自然。
進一步來說,ToTTo目前有121,000個訓練樣本,還有7,500個用於開發、測試的樣本,也就是除了多組表格和相對應的文字,還有一系列受控的生成任務,該任務會提供維基百科表格和一組選定的資料格,作為生成摘要的材料。由於ToTTo資料集擁有高精確性的標註,因此很適合當作Benchmark,用來測試高精確文字生成研究成果。目前,ToTTo資料集和程式碼已於GitHub上開源。(詳全文)
臉書 文字生成 圖片說明
臉書AI不只解讀圖片,還能唸給視障同胞聽
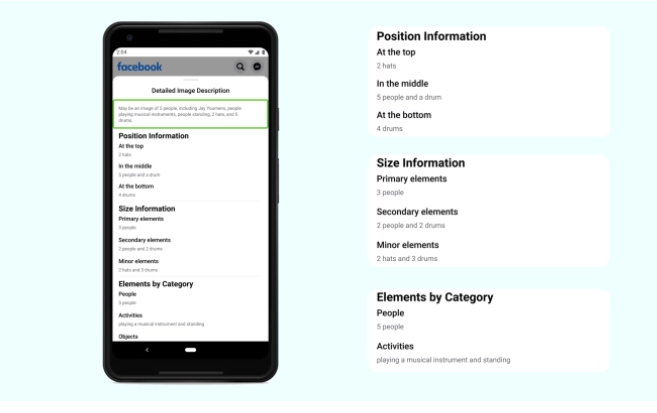
為讓視障同胞更理解圖片內容,臉書改善了用來說明圖片的自動替代文字(AAT)技術,將能偵測和辨識的概念擴大10倍,可對更多類型的圖片加上描述,而且描述也多了許多細節,包括相對位置、主要和次要物體等額外資訊。
臉書在2016年導入AAT技術,透過影像辨識來產生照片描述,讓視障同胞也能理解臉書上的圖片。而這次改版,可生成相對位置資訊等額外描述,比如,過去照片描述可能簡單地以一棟房子和一座山,來描述風景優美的照片,而新AAT技術能夠強調山和房子的相對大小,來強調山才是照片中的主體。
這次新模型採弱監督方法,以數十億張Instagram公開照片和Hashtag組成的資料訓練而成,有別於過往的監督式學習。臉書也微調模型,從所有地理位置採樣訓練用照片和多種語言的主題標籤,同時,臉書還評估了性別、膚色和年齡來評估概念,讓模型更加準確。新版AAT模型可辨識1,200多種概念,是2016年版本的10倍多,即便AAT模型僅會提供高閾值的結果,但仍存在誤差,因此臉書會在每個描述的開頭,都加上「可能」字樣。(詳全文)
圖片來源/加州大學Irvine分校、史丹佛大學、Google、臉書
AI趨勢近期新聞
1. Amazon對外輸出Alexa技術,供企業打造客製化智慧助理
2. 臉書與紐約大學合作以AI預測COVID-19患者病情發展
資料來源:iThome整理,2021年1月
熱門新聞

2026-03-06


2026-03-06


2026-03-09

2026-03-09

2026-03-09

2026-03-06