Google透過將文本挖空,訓練模型生成挖空間隙的字句,藉以改善抽象摘要模型的效能,這個名為PEGASUS的新模型,是Google以網路爬抓的資料預訓練後,再以12個摘要資料集進行微調,只要使用少量的監督範例資料進行訓練,就能達到和人類摘要能力相似的效能。Google現在將訓練程式碼以及模型,開源在GitHub上。
研究人員提到,抽象文本摘要是自然語言處理任務中,非常困難的工作,因為這要求模型要能夠理解長篇文章,並且還要進行資訊壓縮以及語言生成。目前要訓練機器模型做到這一點,主要是用seq2seq學習方法,讓神經網路學習把輸入序列映射到輸出序列;seq2seq使用遞迴神經網路技術,但因為Transformer編碼和解碼器,在處理長序列中的相依關係表現更好,因此逐漸變得熱門。
Transformer模型和自我監督式預訓練技術相結合,研究人員認為,這是一個非常有效解決各種語言任務的框架。而在之前的研究中,預訓練的自我監督目標是較為通用性目的,而現在Google想要讓自我監督目標,可以更緊密地反映最終任務,以達到更好的效能。
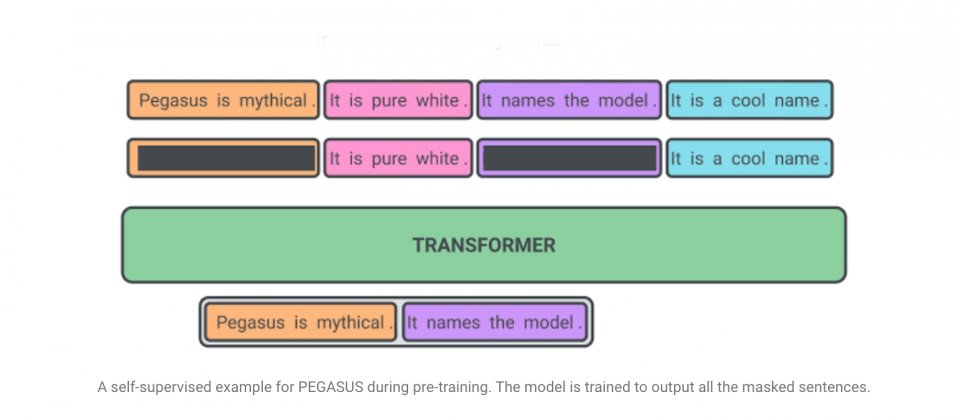
Google假設預訓練自我監督的目標,越接近最終的任務則效能就越好,因此在PEGASUS預訓練中,研究人員將文件裡的幾個完整句子刪除,而模型的工作便是要恢復這些句子,也就是說,用來預訓練的範例輸入,是有缺少句子的文件,而輸出則是缺失句子的串連。
Google提到,這是一個非常困難的工作,對人類來說也一樣,不過,這項任務可以促使模型學習語言和一般事實,還有為了要生成摘要,而學習從文件中提取資訊的能力,這種自我監督方法的優點在於,研究人員可以創建不需要人工註解的大量範例。
而文件中移除的句子,則是越重要的句子越好,自我監督的範例的輸出,最好就相當於摘要,Google利用了一種稱為ROUGE的度量標準,自動找出這些重要的句子。一開始Google會先以網路爬抓的大量文件預訓練PEGASUS,接著才以12個公共抽象摘要資料集微調PEGASUS,這些資料集分別有新聞、科學論文、專利、短篇小說、電子郵件和法律文件等各種主題。
事實上,經過大型資料集預訓練的PEGASUS模型,效能已經相當良好,僅需要非常少量的範例進行微調即可。Google以類似圖靈測試的方法,讓評分人員從PEGASUS模型與人工產生的摘要二選一,而評分人員並非總是選擇人工產生的摘要,而且PEGASUS模型只要以1,000個範例進行微調訓練,效能表現就能與人類相去不遠。
研究人員提到,這樣的成果代表摘要模型不再需要大量監督範例資料集,因此可以大幅降低訓練成本。
熱門新聞

2026-03-02

2026-03-02

2026-02-26



2026-02-27

2026-03-02

2026-02-27