
臉書部署了最新的文字轉語音(TTS)系統,除了能維持既有的音訊品質之外,其語音生成速度比基準快了160倍,而且更特別的是,整個服務都是使用一般的CPU進行運算,不需要用到GPU或是專用的硬體。
臉書提到,為了產生相似人的聲音,光一秒鐘的語音,文字轉語音系統可能就需要輸出24,000個樣本,有時候甚至需要更多,由於新興的模型,其大小和複雜性越來越高,因此也需要更大量的運算能力,而這些運算通常會放到GPU或是專用硬體上來加速運算。
而臉書新的文字轉語音系統則經過模型最佳化,利用一般的CPU進行運算,就能即時產生語音,臉書提到,這個系統具有高靈活性,可創建和擴展更人性化和更具表達性的語音,並能在應用程式中呈現更好的語音效果,目前這個新系統被應用在臉書的視訊通話裝置Portal上,可以讓其上的應用程式提供閱讀和虛擬實境等語音應用。
這個系統主要由4個主要部分組成,第一部分是將輸入的文字轉換成語言功能序列,輸出像是人類語言中可區別意義的最小單位音位(Phoneme)和句子類型,第二部分是可用來預測節奏和旋律,創建自然語音表現力的韻律模型(Prosody Model),第三是生成語音模型頻譜表示的聲學模型,而最後則是可根據韻律和頻譜特徵,產生24 kHz語音波形的神經聲碼器(Vocoder)。

臉書提到,神經聲碼器的特性需要按順序生成樣本,而這對於即時合成語音來說是一大障礙。在臉書一開始的實驗,產生音訊的速度約是80 RTF(Real-Time Factor ),也就是單個CPU核心產生1秒鐘的音訊需要花費80秒,但是要在Portal這類的系統上提供即時語音服務,則必須要將速度提升到1 RTF。
為此,臉書對模型進行了一連串的最佳化,包括使用PyTorch JIT,將原先訓練導向的PyTorch設定,轉為預測最佳化環境,並使用經編譯的運算子以及各類張量層級的最佳化,榨出額外的運算加速,而且臉書還透過訓練模型,達到非結構化模型稀疏化,降低預測運算的複雜度,除了4%非零模型參數,臉書實現了96%的非結構化模型稀疏度,這代表模型在不降低音訊品質的情況下,速度運算將提高5倍。
另外,臉書還應用了區塊稀疏化,將非零參數限制在固定大小的區塊,並儲存在連續的記憶體區塊中,因此能夠進一步簡化模型,而這將會使記憶體以緊湊的布局儲存參數資料,並且花費最少的間接尋址時間,大幅提高記憶體頻寬利用率和快取利用率。臉書也將運算負載繁重的運算子,分配到多個CPU核心同時進行處理,進一步提高速度。
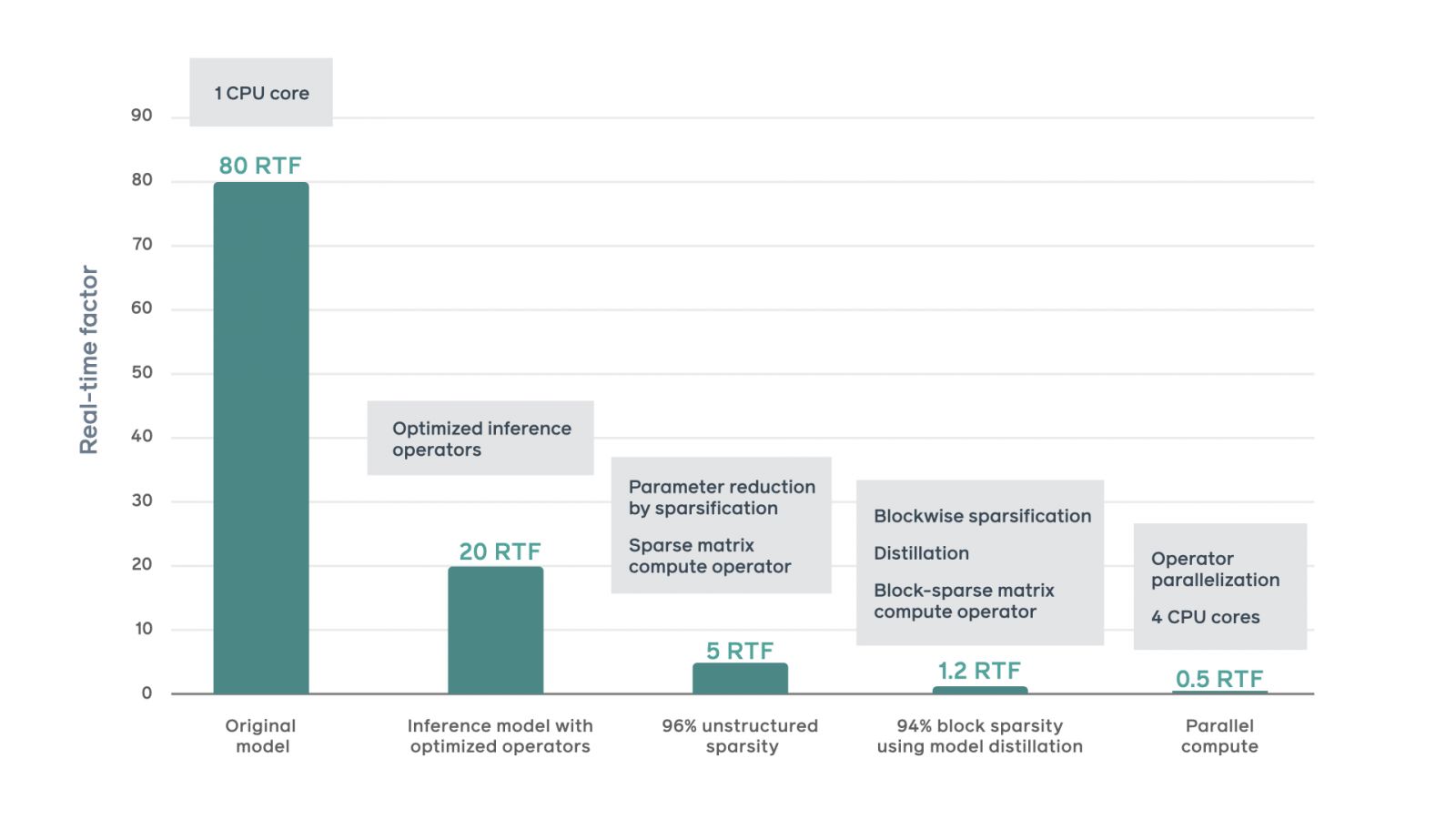
最終的文字轉語音系統運用4個CPU核心運算可達0.5 RTF,也就是合成速度是一開始基準的160倍,臉書提到,由於語音助理的應用越來越普及,而且要了讓語音助理與人的互動更加自然,需要應用區域方言個人化系統,因此接下來臉書會借助新的文字轉語音系統的靈活性,在語音產品組合添加更多語言和口音,並讓更小的裝置也能運作這個系統。
熱門新聞

2026-02-23

2026-02-23

2026-02-20



2026-02-23

2026-02-23

2026-02-23