
歷經超過2年的發展,機器學習工具包Kubeflow終於發布了第一個主要版本,Kubeflow是第一個針對Kubernetes,提供可移植與可擴展的機器學習解決方案,讓用戶利用機器學習工作管線,調度Kubernetes上執行的複雜工作流程。Kubeflow原本稱為TensorFlow Extended,是Google內部用來部署TensorFlow模型到Kubernetes的方法。
Kubeflow初始專案的開發者來自Google、思科、IBM、紅帽、CoreOS以及CaiCloud,在2017年底在美國Kubecon中對外開源,之後專案便蓬勃發展,現在有來自30個組織上百位的貢獻者,參與Kubeflow專案的開發。
官方提到,應用Kubeflow,用戶不需要學習新概念或是平臺來部署應用程式,也不需要處理Ingress或是網路憑證等問題。Kubeflow的目標是要讓機器學習工程師和資料科學家,能夠更容易地使用雲端資源,處理機器學習工作負載。
Kubeflow 1.0提供了一組穩定版本的應用程式,提高開發者在Kubernetes上進行開發、建置、訓練和部署模型的效率(下圖)。這些應用程式包括Kubeflow的使用者介面Central Dashboard以及Jupyter筆記本控制器,還有用於分散式訓練的Tensorflow和PyTorch運算子,同時也提供管理多重使用者的配置文件管理器,和部署升級工具kfctl。
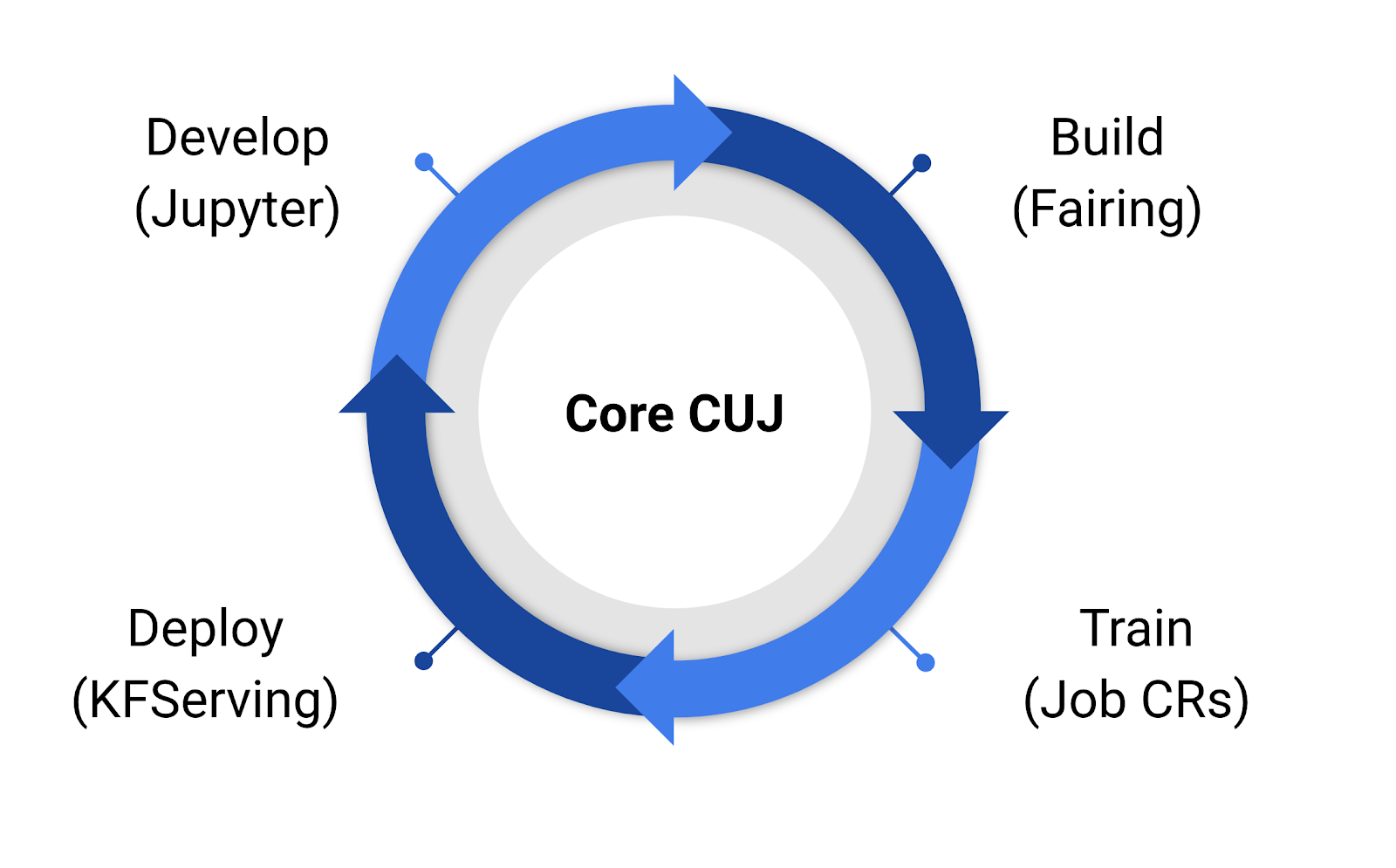
Jupyter筆記本是資料科學家重要工具,而且為了提升實驗效率,Jupyter筆記本需要與Kubernetes雲端運算資源整合,以使用GPU訓練更大的模型,或是平行執行多個實驗。Kubeflow簡化了以Kubernetes管理資源的方法,每個資料科學家或團隊都可以擁有自己的命名空間,執行各自的工作負載。命名空間提供了安全性與資源隔離,在使用Kubernetes資源配額時,管理員還可以限制個人或是團隊使用量。
Kubeflow還讓用戶能夠簡單地進行分散式訓練,官方提到,當他們啟動Kubeflow這個專案時,動機之一便是要利用Kubernetes簡化分散式訓練。Kubeflow提供了Kubernetes自定義資源,而這些資源會讓使用TensorFlow和PyTorch進行分散式訓練工作變得簡單,只要定義TFJob或是PyTorch資源,自定義控制器便會自動啟動並且管理所有獨立的程序,並且使這些程序能夠互相溝通。
接下來還會有許多工具在Kubeflow中成熟,像是建置在無伺服器管理平臺Knative之上的自定義資源KFServing,可幫助用戶部署和管理機器學習模型,其模型可解釋性功能則正在Alpha測試中,另外,可用來定義複雜機器學習工作流程的工具Pipelines;可追蹤資料集、工作和模型的Metadata;超參數調校工具Katib,這些工具都正在beta測試中,在未來的發布版本會陸續加入Kubeflow 1.0。
熱門新聞


2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23