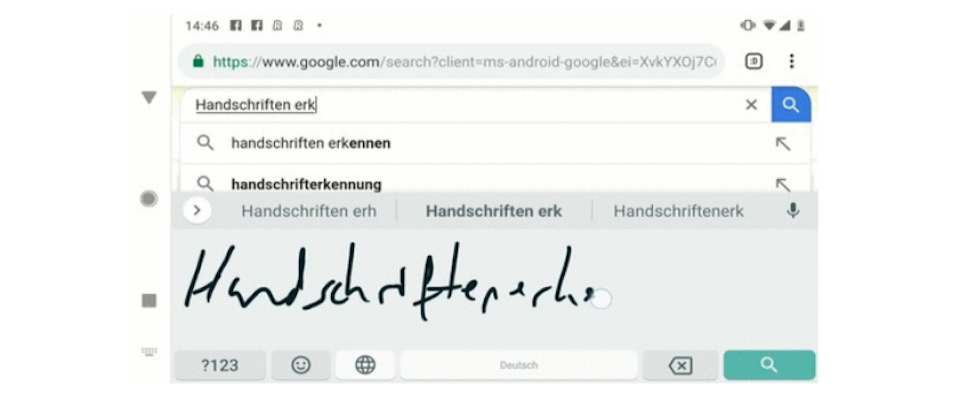
Google AI研究團隊透過遞歸神經網路(RNN),將Gboard手寫輸入辨識模型的錯誤率降低了20%~40%,Google也為所有以拉丁字母書寫的語言,推出新版的辨識模型,並發表相關的研究論文,詳細解釋該版本模型背後的技術。
過去,Google採用的辨識方法是將手寫輸入切割成單個字符,再針對字符進行解碼,Google解釋,對每個手寫辨識系統而言,接觸點是開端,系統將一序列的點視為筆畫,而手寫輸入就是用筆畫序列來表示,且每個點都會附有時間戳,由於Gboard被用於多種不同的設備,也意味著有著不同的螢幕解析度,因此,Google的第一步即是要將接觸點座標正規化,接著,為了正確地擷取手寫輸入的形狀,Google將接觸點組成的序列,轉換三次貝茲曲線(cubic Bézier curves)序列,再將其序列作為遞歸神經網路的輸入資料。
Google表示,雖然用貝茲曲線作為手寫辨識的資料已經行之有年,但是將其當作AI模型的輸入資料卻是非常新穎的,如此一來,也能夠在不同樣本數量和正確率的多種設備中,提供一致的輸入資料,有別於過去切割和解碼的辨識方法,Google現在則是創建多個如何將筆畫分解字符的不同假設,接著從這些分解後的序列中,找出最適合的字符序列。
這個新方法的另外一個優點是,貝茲曲線的序列比接觸點序列來得小,使模型更容易取得輸入資料的時間依賴性,也就是每條曲線都是由起始點、終點,以及兩個額外的控制點所定義的多項式來表示,透過迭代的方式將輸入座標和曲線之間的平方距離最小化,來找出準確表示手寫輸入的三次貝茲曲線序列。
找出手寫輸入的三次貝茲曲線序列之後,還需要將曲線序列轉譯為真實寫作字符,為此,Google利用多層遞歸神經網路來處理曲線序列,並針對每個曲線搜索所有可能字符的機率分布,再將該機率分布輸出成矩陣。
在研究的過程中,Google嘗試過多種不同種類的遞歸神經網路,最後選擇雙向版本的準遞歸神經網路(quasi-recurrent neural networks),準遞歸神經網路能夠在卷積層和遞迴層之間交替,提供有效的預測能力,同時也能夠維持相對較少的權重數量,權重數量會直接影響模型的大小,模型越小效能就越好。
此外,為了提供最佳的用戶體驗,模型不但要準確也要快速,因此,Google將在TensorFlow訓練好的模型轉換成行動裝置版的TensorFlow Lite模型,在模型訓練的過程中量化所有權重,同時,TensorFlow Lite針對二進制進行優化的特型,能夠減少APK的大小。
熱門新聞

2026-02-23

2026-02-20

2026-02-23

2026-02-23
2026-02-20