
推特最近把原本內部開發的Pub/Sub系統EventBus更換成Apache Kafka,除了在成本上,當有許多使用者都要轉推發文的情況下(資料處理上稱為fan-out),能節省高達75%的資源外,由於Kafka龐大社群的資源,修復錯誤和增加新功能更快,也更容易找到系統維護工程師人選。
Apache Kafka是一個開源分散式串流平臺,能以高吞吐量低延遲方式傳輸資料。Kafka的核心是基於日誌建構的Pub/Sub系統,具有可水平伸縮和容錯性,是用來打造即時新聞系統的理想選擇。但其實推特在幾年前就已經使用過Kafka,推特發現當時Kafka 0.7版本,有幾個不適合他們使用情境的缺點,主要是在追趕讀取(Catchup Reads)期間的I/O操作數限制,也欠缺耐久性和複製功能。
由於當時使用Kafka的這些限制,推特基於Apache DistributedLog,打造了自己的Pub/Sub系統EventBus,以應付推特快速發布突發新聞、對使用者提供相關廣告,以及其他即時使用案例的需求。
時至今日,硬體和Kafka專案在經過時間的發展,推特之前遇到的問題,都已經獲得解決。SSD的價格已經足夠低廉,有助於解決之前在HDD上遇到隨機讀取先前I/O的問題,而且伺服器NICs具有更大的頻寬,使得EventBus的分割服務和儲存層的好處消失。新版的Kafka現在還支援資料複製,提供推特需要的資料耐久性保證。推特表示,驅動他們把Pub/Sub系統從EventBus搬遷到Kafka上,主要是考量成本以及社群兩個原因。
在推特決定要搬遷Pub/Sub系統到Kafka之前,團隊花了數個月評估,他們在Kafka上運作相近於EventBus上的工作負載,包括耐久寫入、長尾讀取(Tailing reads)、追趕讀取以及高扇出讀取(High Hanout Reads),還有一些灰色故障的情境。從資料串流消費者讀取訊息的時間戳差異來衡量,無論吞吐量如何,Kafka的延遲都明顯較低,推特提到,這可以歸因成三個原因,第一個,由於在推特原本使用的EventBus,服務層和存儲層是分離的,因此產生額外的跳躍(Hop),而Kafka只用一個程序處理儲存和請求服務。
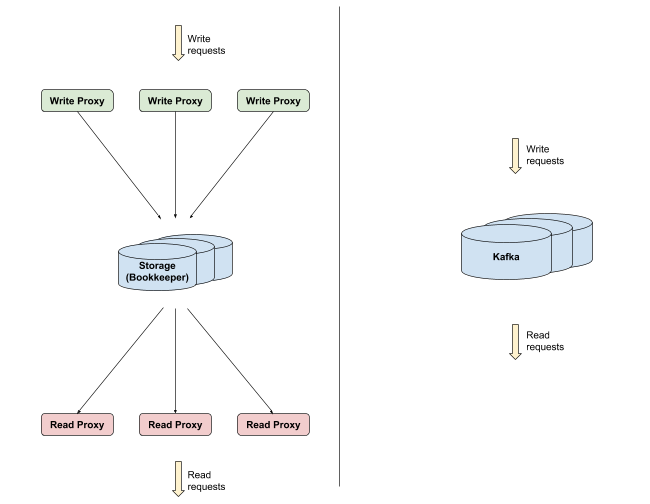
第二個原因,EventBus明顯地阻止對fsync()呼叫寫入,但是Kafka卻仰賴作業系統背景進行fsync()呼叫。第三個原因是,Kafka使用零複製(Zero-copy)。因此從成本的角度來看,EventBus需要服務層和存儲層的硬體,分別針對高網路吞吐量和硬碟進行最佳化,但Kafka只需要使用單一主機,推特提到,顯然EventBus需要更多的機器才能達到和Kafka相同的工作負載。
單一資料串流消費者的使用案例,Kafka可以節省68%的資源,當有多個使用者發文並轉推給他們所有友人時的fan-out情況下,推特估計,則能節省高達75%的資源。推特表示,由於他們使用案例fan-out效應不夠極端,在實作中不值得分離服務層,特別是考慮到現代硬體上的可用頻寬,否則在理論上EventBus應該更有效率。
除了成本上的考量,Kafka龐大的支援社群也是一大優勢。在推特中,維護EventBus系統的只有8名工程師,但是Kafka專案現在卻有數百人進行維護,幫忙修復錯誤和增加新功能。推特預計在EventBus增加的新功能,像是串流函式庫、至少一次HDFS工作管線以及一次性處理都已經在Kafka中具備了。
此外,在客戶端或是伺服器發生問題時,開發人員可以參考其他團隊的經驗,快速的解決問題,而且也因為Kafka是一個熱門專案,因此了解Kafka的工程師數量也比較多,方便招聘系統工程師。在接下來的幾個月內,推特計畫開始把使用者從EventBus遷移到Kafka上,以降低營運成本,並且讓使用者獲得Kafka提供的其他功能。
熱門新聞

2026-03-06


2026-03-11




2026-03-06

2026-03-09