
AWS
AWS近日宣布在ML自動建置和部署工具SageMaker的平臺中,新增多項新功能,包含語義分割演算法(semantic segmentation)、搜尋ML訓練模型的功能Search,以及自動優化ML模型編譯器Neo。
首先,AWS加入了語義分割演算法,原先該平臺中已內建兩個熱門的電腦視覺演算法,包含影像分類和物件偵測,影像分類演算法將影像分類到預先定義的類別中,而物件偵測演算法則能標示出物體位置定界框(bounding box)並識別該物體。此外,AWS還新增了搜尋ML訓練模型的功能Search,讓開發人員可以從平臺中數千個機器學習模型中,找到最適合的訓練模型,加速企業建置機器學習模型的開發和實驗階段,目前該功能為測試版,使用該功能將不會有額外的收費。最後,為了協助企業提升ML模型效能,AWS還新增了自動優化ML模型的編譯器Neo,利用神經網路,在不減少準確度的情況下,自動將ML模型提升2倍效能。
使電腦視覺模型更加完善,AWS新增語義分割演算法
語義分割是將圖像中每個Pixel,用已標示的資料集來分類,給予每個Pixel標上語義標籤,分割後輸出的結果通常是用不同的RGB值來表示,若分類值小於255,則用灰階值表示,因此,輸出的結果是一個矩陣或是灰階圖,也被稱為分割遮罩,透過AWS的語義分割演算法,企業可以用自己的資料集訓練自家的模型,也能用預先訓練的模型,該語義分割演算法是透過MXNet Gluon框架和Gluon CV工具包打造的,提供3種內建的最新的演算法來訓練語義分割模型,包含全卷積網路分割(FCN)、空間金字塔結構網路(PSP)和Google開源的語義分割模型DeepLab-V3。
上述的所有演算法都包含編碼器和解碼器,編碼器是負責產生圖像特徵圖的網路,而解碼器則是用特徵圖建置分割遮罩,編譯器的部分,AWS提供在ImageNet分類器預先訓練的ResNet50和ResNet101給開發人員選擇,這些是已經經過優化的FCN和PSP,另外,使用者也可以選擇未經訓練的網路,自己從頭做起。
該語義分割演算法能透過P2/P3種類的AWS EC2實例,在一台機器的配置下訓練,模型其實能在所有AWS SageMaker支援的CPU和GPU實例中訓練,但是,由於卷積式網路能夠在GPU機器上充分地利用數學函式庫,在CPU機器訓練會比GPU機器昂貴許多,因此,AWS限制只能在GPU機器上訓練。
加速建置ML模型開發與實驗時程,AWS新增搜尋最相關訓練模型功能Search
除了新增語義分割演算法之外,為了能夠加速企業建置ML模型的開發和實驗工作,AWS還新增了搜尋ML訓練模型的功能Search,讓開發人員可以從平臺中數千個機器學習模型中,找出相關的訓練模型,該功能透過Management Console和AWS SDK APIs推出,並不會額外收取其他費用。
AWS表示,開發機器學習模型需要不間斷地實驗和觀察,舉例來說,當企業嘗試用新的學習演算法,或是調整模型的超參數時,必須持續觀察模型準確度和效能的變化,反覆的優化過程,可能會產上數百個版本的模型,最後還得找出最佳的模型,導致拖延到部署模型的時程。
這次推出的搜尋功能,能夠讓企業利用定義的屬性,快速找出最相關的模型進行訓練,像是使用的學習演算法、超參數的設定、訓練資料集,甚至是企業為訓練模型工作標上的標籤等,透過搜尋功能,企業和研究團隊都能夠快速找到與特定業務相關的模型,除此之外,還能根據效能指標進行排名,找出最佳的模型。
圖片來源:AWS
提升2倍效能,AWS推出編譯器Neo自動優化ML模型
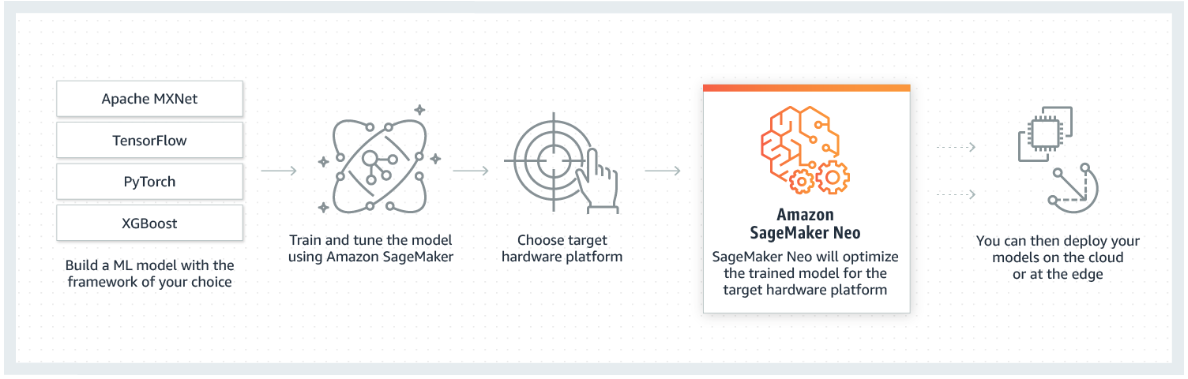
最後,AWS將機器學習分為兩個階段訓練和推斷,訓練的過程是利用ML演算法建置模型,找出有意義的模式,而這個過程通常需要大量的儲存空間和計算資源,推斷則是用訓練過的模型,產生模型未處理過資料的預測結果,開發者對推斷過程主要的疑慮是優化延遲和生產力問題,也就是產生一次預測結果需要多少時間,以及平行處一次可以執行多少預測工作,針對這兩個問題,預測環境所用的硬體架構是最大的影響因素,雖然可以針對硬體架構調整模型,但是調整的工具耗時且容易出錯,因此,多數開發人員即使面對不同的硬體架構,還是會部署相同的模型,而犧牲效能。
針對這個問題,AWS於ML自動建置和部署工具SageMaker的平臺中,推出自動優化ML模型的編譯器Neo,使ML模型經過一次訓練,就能達到最佳效能,AWS表示,能夠在不影響模型準確度的情況下,將效能提升為2倍。Neo支援TensorFlow、Apache MXNet、PyTorch、ONNX和XGBoost等框架,硬體架構的部分支援ARM、Intel和Nvidia,此外,Neo已透過Apache軟體授權方式開源釋出,允許硬體廠商訂做支援Neo的處理器和裝置。
圖片來源:AWS
熱門新聞

2026-02-23

2026-02-23

2026-02-20


2026-02-23

2026-02-23

2026-02-23

2026-02-23