
GraphPipe是甲骨文用來部署機器學習模型的工具,現在對外開源。GraphPipe解決了部署模型面臨的3個問題,框架傳輸標準不一、複雜的模型部署工作以及解決方案效能低落。目前GraphPipe高效能伺服器支援TensorFlow、PyTorch、mxnet、CNTK和caffe2內建的模型。
雖然近年機器學習的發展有長足進步,現存不少框架,都可以幫助開發者快速的產生出機器學習模型,不過,甲骨文指出,要將機器學習模型部署到生產環境中,才是挑戰的開始。由於機器學習模型提供服務的API並沒有統一標準,可能是透過協定緩衝區(Protocol Buffers)或是自定義的JSON格式的方式,因此開發者經常會在框架操作上遇到困難。一般來說,應用程式需要一個特製的客戶端,負責與部署的模型溝通,而這個情況會因為程式架構使用多個框架,情況變得更加複雜,開發者勢必要撰寫自定義的程式碼,來整合多個框架。
此外,建構機器學習模型伺服器也並非一件簡單的事,訓練模型的方法通常比部署要來的受人矚目,部署模型的資源相對較少,甲骨文表示,開箱即用的機器學習解決方案很少,並舉例,像是開發者要使用TensorFlow的GPU版本提供服務,最好有戰鬥數天的心理準備。部署模型還有另一個問題,甲骨文認為,不少現有的解決方案並不關注效能表現,對於特定應用情境影響大。
而GraphPipe能夠解決上述的各種問題,GraphPipe為傳輸張量資料,提供了標準高效能協定,並且簡化客戶端與伺服器部署的工作,讓任何框架部署和機器學習查詢的工作變得簡單。甲骨文提到,GraphPipe的高效能協定,目的在簡化和標準化遠端與近端間的機器學習資料傳輸,目前在深度學習的架構中,傳輸張量資料並沒有主流標準,開發人員可能會使用效能低落的JSON協定,抑或是TensorFlow協定緩衝區,效能雖然較好卻又帶有TensorFlow的包袱。
GraphPipe以二進位記憶體映射格式,提升傳輸效率,並且維持簡單的相依性。GraphPipe內含一組Flatbuffer定義,以及根據Flatbuffer定義提供模型服務的指南,並且含有TensorFlow、ONNX和caffe2的使用範例,另外,也提供了透過GraphPipe查詢模型服務的客戶端函式庫。本質上,GraphPipe請求行為類似於TensorFlow預測請求,只不過使用Flatbuffers作為訊息格式,而Flatbuffers則是類似Google協定緩衝區,具備在反序列化步驟避免記憶體複製好處。
甲骨文展示了GraphPipe的高效能表現,首先比較了自定義ujson API、TensorFlow預測請求協定緩衝區以及GraphPipe遠端請求,在Python中浮點數張量資料的序列化和反序列化速度。請求包含了1,900萬個浮點數值,並且收到回應的320萬個浮點數值,GraphPipe無論在請求或是收到回應花的秒數都是最低的,即便較耗時的序列化請求也花費不到0.1秒,但是Json在請求上都花了超過1.4秒的時間,甲骨文解釋,之所以GraphPipe可以表現的這麼快速,是因為Flatbuffers不需要記憶體複製。

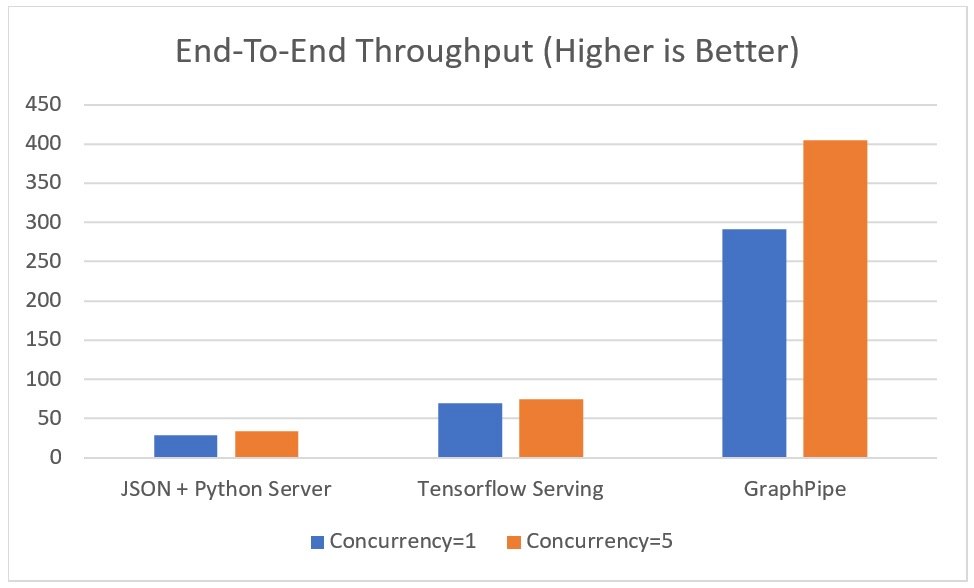
接著,甲骨文把Python-JSON TensorFlow、TensorFlow以及GraphPipe-go TensorFlow模型伺服器,比較其端對端資料吞吐量。三種的後端模型都是相同的,使用單一和5個執行緒不停的對伺服器發出大量請求,並計算模型每秒可以處理的資料行數。由圖中可以看出,Python-JSON和TensorFlow在單一和多執行緒的表現沒有太大的差異,約在每秒50行上下,但GraphPipe的表現卻可以是其他組的5倍以上。
GraphPipe的資料都可以在GitHub中找到,伺服器目前提供了Python和Go版本,而客戶端也有Python和Go版本,之後會再支援Java。
熱門新聞

2026-03-06

2026-03-06

2026-03-09

2026-03-09


2026-03-06

