
在re:Invent 2017大會的主題演講上,AWS執行長Andy Jassy列出他們現在提供的所有資料庫服務,涵蓋主流與商用的關聯式資料庫、非關聯式資料庫。
一般而言,資料庫系統是企業建置與維運應用系統所必備的,對於雲端服務業者而言,這是持續吸引企業將IT基礎架構遷移上去的關鍵,而AWS本身當然也提供這樣的服務,涵蓋現行主流的關聯式資料庫平臺,以及各種非關聯式資料庫,同時,他們也有市占極高的雲端儲存服務,可供企業作為大數據分析的資料湖。
而在2017年底舉行的全球用戶大會re:Invent上,AWS也針對這三種資料儲存應用領域,推出了多種新的服務與功能,以求徹底發揮雲端服務的優勢,顛覆當前企業資料應用架構的既有格局。
關聯式資料庫:運用跨資料中心架構,挑戰甲骨文資料庫殺手級應用
在2009年,AWS開始推出Amazon Relational Database Service(RDS),之後,陸續支援多種資料庫引擎,例如,MySQL、Oracle Database、微軟SQL Server、PostgreSQL、MariaDB,以及他們自行發展的資料庫服務Aurora(相容於MySQL與PostgreSQL),針對社群偏好開源軟體、商用等級資料平臺,以及兼具兩者特色等需求,提供多樣選擇。
而AWS在自家的2017 re:Invent大會上,對於關聯式資料庫雲端服務的部分,特別主打的訴求是「自由」,強調用戶不該遭受特定廠商的粗魯對待與綑綁,或是只能選擇以一體適用所有需求的產品。
該公司執行長Andy Jassy在主題演講過程時,更是火力全開。他強烈批評Oracle產品昂貴、架構專屬且緊密綑綁,毫不關心用戶,因為今年初,他們將執行在AWS、Azure等雲端服務上的軟體價格,提高了1倍,使得用戶想儘快遷移到其他開放的資料庫引擎,像是MySQL、PostgreSQL、MariaDB。
若要以這些引擎來達到商業等級資料庫的要求,技術上雖然可行,但有一定困難度,由於用戶也期望AWS的相關服務,能提供如此等級的效能,兼具成本效益,並且對於開放資料庫引擎保持友好的關係,因此,他們耗費幾年的功夫來發展自有的資料庫引擎Amazon Aurora。
Andy Jassy強調,這套可完整相容於MySQL、PostgreSQL的資料庫雲端服務,效能比這些軟體的標準版本要快上好幾倍,系統的耐用度與高可用性,能與商業等級資料庫並駕齊驅,價格卻只有十分之一。同時,他也相當自豪地表示,Aurora是AWS旗下眾多雲端服務當中,用戶成長速度最快的——2015年已有數千家用戶,代表性客戶包括:Yahoo!、聯合國、NBC環球集團;到了2016年,Aurora用戶數量增加到3.5倍,像是Netflix、Ticketmaster、Redfin等公司,都開始採用;而在2017年,這套關聯資料庫服務的用戶,數量成長2.5倍,達到1萬家的採用規模,舉凡Verizon、Hulu、道瓊公司、CBS等知名企業,都在使用。
談到Aurora之所以受到歡迎,Andy Jassy認為,在於當中提供了高效能與高可用性,同時,也支援橫向擴展(Scale-out)——目前,在單一Master Node的架構下,Aurora資料庫的運作,已經能夠橫跨3個AWS的可用區域(Availability Zone,AZ),最多可同時執行15個「僅供讀取複本(Read Replica)」,並能根據使用規模的需求變化,自動擴展Read Replica的數量,若發生Read Replica故障情況,也能自動進行復原。
然而,Aurora的能耐還不僅止於此,因為,Andy Jassy當場還宣布另一個重大消息,那就是,AWS將進一步推出Aurora Multi-Master,使資料庫的讀取與寫入的作業,都能支援橫向擴展,目前僅支援單一可用區域,預計在2018年支援多個可用區域。
這意味著,Aurora能夠同時橫跨多個可用區域(AZ),建立支援讀寫的Master Node的架構,因此,應用程式在存取這樣的資料庫環境時,就算面臨單一節點、甚至單一AZ損毀的狀況,都能夠以這種相互備援的方式,維持正常運作,並在一秒內從故障中還原。
而這樣的架構,不禁讓人聯想到企業級資料庫軟體大廠甲骨文(Oracle),因為,長期以來,他們持續在大型的應用環境,持續提倡採用Real Application Cluster(RAC)的架構,而Andy Jassy認為,Aurora Multi-Master的優勢,在於同時橫跨多個資料中心,而且由於Aurora本身就是SQL相容的關聯式資料庫,所以用戶不需要重新撰寫應用程式。
關於Aurora,AWS在這次的用戶大會上,接著還發布了另一套相當特別的資料庫雲端服務,稱為Aurora Serverless。
之所以推出這樣的服務,因為AWS觀察到很多用戶的關聯式資料庫,並不是處於全天候使用的狀態,有時可能在進行測試,或是突然遇上尖峰存取,工作負載的起伏變化很大,對於資料庫雲端服務的用戶來說,很難決定該租用到多少用量才足夠又不浪費,而Aurora Serverless,正是希望提供可隨需使用、自動擴展使用規模的資料庫,而且,是架構在Serverless的運作模式上。
Andy Jassy強調,在這套服務下,不需要產生虛擬機器,系統將根據實際的用量,自動調整執行規模,隨時會依據需求的出現而啟動,若不需要時,也能夠自動關閉,而且,用戶支付的成本是以秒計費,並且是只針對資料庫使用容量的部分。
.png)
Aurora Multi-Master運作架構比一比
左圖是Aurora目前的運作架構,支援自動擴展使用規模,並可橫跨3個可用區域(資料中心),最多可同時執行15個讀取副本(read-only replicas),在資料讀取的作業上,具有高度的可用性與使用效率,但具有讀取與寫入能力的主節點只有1個。
而右圖則是即將登場的Aurora Multi-Master,將資料庫性能提升與備援效益擴及資料寫入作業,可橫跨多個可用區域,並且同時執行多個具有讀取與寫入能力的主節點。在這樣的架構下,資料寫入效能可以顯著提升,同時也能因應單一節點,或是可用區域的故障,避免影響應用程式的執行。
非關聯式資料庫:支援跨資料中心架構,提供資料保護功能
AWS除了積極拓展關聯式資料庫的服務項目,對於非關聯式資料庫的部分,也有布局。例如,他們在2011年推出的ElastiCache,提供了記憶體內(In-Memory)的資料儲存與快取——針對Redis與Memcached這兩套軟體平臺,AWS提供代管的伺服器節點;另一個則是2012年推出的DynamoDB,屬於NoSQL類型的資料庫雲端服務,可存放「鍵-值(Key-Value)」與文件。
而到了2017年底舉行的re:Invent大會上,AWS也特別針對DynamoDB的部分,增加Global Tables、Backup and Restore等特性。
有了Global Tables之後,能帶來的好處很多,因為,這套雲端服務的運作,開始支援多個主節點(Multi-Master)的架構,也就是能夠跨越多個資料中心執行,就如同上述Aurora Multi-Master所強調的特點,所以,用戶憑藉由AWS代管的NoSQL資料庫服務所建立的系統,同樣可達到下列目標:高效能、高可用性,且應用範圍涵蓋全球。
而由於支援跨資料中心、分散式架構,現在DynamoDB資料庫的運作,可受益於多個資料中心彼此之間的災難備援能力,在當地執行資料表的讀寫存取作業時,也能享有低延遲的好處,此外,相關設定也相當簡便,Andy Jassy表示,用戶不需為此改寫應用程式。
至於Backup and Restore,顧名思義是用於資料庫的備份與還原,AWS在2017年底,已開始提供隨需備份(On-Demand Backup)的功能,可協助用戶將存放在DynamoDB服務的資料,進行長期保存與歸檔的作業,以符合法規的要求。而用戶在執行這項功能時,無論所要保護資料的多寡,或執行多個排程備份作業,都能很快完成,不會影響應用系統存取資料庫的效能。
在DynamoDB備份、還原的機制上,2018年初,AWS預計進一步提供時間點還原(Point-in-Time Restore,PITR),保護的目標是用戶近期在DynamoDB儲存的資料——若因應用程式故障而發生資料損毀的狀況,用戶可將資料還原到過去35天內、任何一分鐘的狀態。
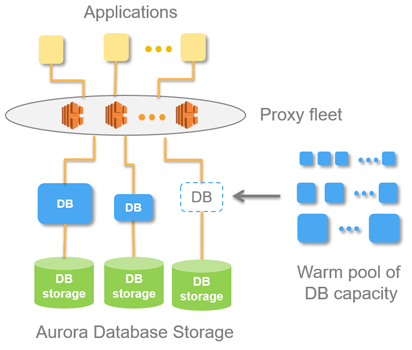
Aurora Serverless運作架構
針對工作負載變化劇烈的關聯式資料庫系統運作環境,AWS新提供了Aurora Serverless的服務組態,用戶付費時,只需根據使用的資料庫資源與期間來計算(以秒計費)。
之所以能透過Serverless的方式提供資料庫服務,主要是因為Aurora本身的運作,就採取了處理層與儲存層彼此區隔的架構,而用戶只需建立資料庫端點,設定需要的最大與最小容量,之後應用程式若要存取Aurora裡面的資料,只需將查詢請求發給這個資料庫端點即可,而端點就像一臺代理伺服器,能夠將查詢請求轉送到資料庫資源裡面,若需要擴展使用規模,5秒之內就可以產生(圖片提供/AWS)。
非關聯式資料庫:新推出圖學資料庫,主打效能、可靠與安全
關於非關聯式資料庫的部分,AWS在2017 re:Invent大會上,還有最後一項重大宣布,那就是他們即將推出圖學資料庫(Graph Database)的雲端服務,稱為Amazon Neptune。
而這套新服務所要管理的資料類型,主要是具有高度連結性的資料(Highly Connected Data)。AWS之所以踏入這個領域,主要是有鑑於相關的資料處理應用,越來越常見,例如,當前我們正在使用的許多系統,需要能夠儲存與了解這些資料之間的關係,以便因應社交新資訊的發送、推薦引擎產生的建議,以及詐欺行為的偵測等需求,發展出更為精準、好用的功能。
相較於現行的圖學資料庫,Andy Jassy認為,Neptune主要特色在於,架構開放且容易使用、服務更為可靠,同時,處理速度快,也易於擴展使用規模。
舉例來說,這套服務支援常見的圖學查詢語言,像是Apache TinkerPop的Gremlin,以及W3C資源描述框架(RDF)的SPARQL,使用者可以快速建立查詢指令,進而更有效率地操控手上的高度連結資料。
在資料的處理能力與存取速度上,Neptune可儲存幾十億個關係,而查詢資料的時間只需幾毫秒。對於Neptune本身使用的查詢處理引擎,AWS也予以最佳化,可支援Property Graph、RDF等資料模型,以及相關的查詢語言(亦即上述的Gremlin和SPARQL)。
至於可靠度的部分,Andy Jassy表示,Neptune儲存的資料有6個副本,並遠端複製到AWS維運的3個可用區域(AZ),也提供完整備份與還原能力。根據AWS網站公布的資料來看,這套資料庫服務提供的可靠性等級,達到99.99%以上,並且採用多種保護機制。
例如,在資料儲存的部分,Neptune具有容錯與自動修復能力,可在背景處理硬碟故障的問題,而不會影響資料庫的可用性;同時,Neptune會自動偵測資料庫是否出現停止運作的狀況,並且予以重新啟動,而不需要修復或重建資料庫快取;就算發生資料庫執行實例故障的情形,Neptune也能夠自動啟動容錯作業,最多可同時啟動15個讀取副本(read replica),而這麼一來,除了維持系統與資料的可靠度,也帶來降低資料庫整體存取延遲的好處。
除了運用多個讀取副本,AWS在這裡採用的資料庫引擎,也緊密整合專屬設計的虛擬儲存層(底層是固態硬碟),而能增加資料的高可用性與存取速度。
在擴展使用規模的彈性上,Neptune能隨著用戶儲存資料量的增長,而自動加大本身的容量,每次可增加10 GB,上限是64 TB。
AWS在Neptune的環境中,也提供多種資料保護功能。例如:資料庫可自動定期持續備份到Amazon Simple Storage Service(S3),備份保存最長為35天;同時,用戶也可以自行在資料庫執行快照,手動備份用戶啟動的資料庫執行實例,而這些快照會存放到S3;而且,Neptune還具備時間點還原(point-in-time recovery)的功能,協助用戶將系統回復到5分鐘內任何一秒的狀態。
此外,用戶也可啟用資料庫加密,搭配AWS Key Management Service產生與控管的金鑰,保護Neptune底層的靜態儲存資料,以及同一個叢集內的備份、快照、遠端複製副本。而在資料傳輸的過程中,Neptune也採用了TLS(AES-256)的加密連線,確保資料移動時的安全性。
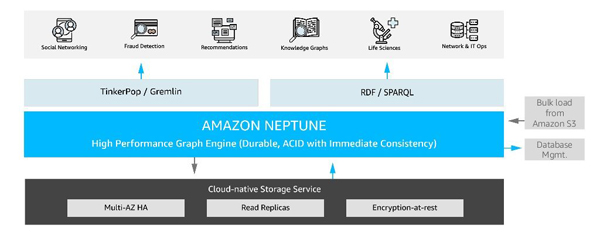
Amazon Neptune運作架構
看好處理與儲存高度連結資料(Highly Connected Data)的需求日增,AWS推出圖學資料庫雲端服務Amazon Neptune,底層儲存具有AWS一貫的特色,能夠跨多個可用區域、支援讀取副本,以及靜態資料加密,而上層可以透過Apache TinkerPop和W3C RDF的中介,讓各種應用程式能夠存取Neptune裡面的圖學資料。
資料湖:針對物件儲存服務的資料,提供更有效率的使用方式
大數據已是當代應用系統不可或缺的一環,若要儲存與運用這類型的數據,我們可能需透過資料湖(Data Lake)來存放,而要獲得這樣的環境,除了用戶自行建置之外,也有不少人會採用現成的雲端儲存服務,像是Amazon S3提供的物件儲存環境就是其中一種選擇。
不過,在S3資料湖的應用上,後續也衍生了多種雲端服務,例如,在2016年12月發表、2017年8月正式推出的Glue,提供了資料的萃取、轉換與載入(ETL)服務,將發現與儲存的資料,以及相關的詮釋資料(metadata),編撰成資料型錄(Data Catalog),整合AWS旗下的多種雲端服務,提供搜尋和查詢功能,像是針對S3儲存資料提供SQL查詢的Athena、提供多種大數據框架代管的EMR,以及用於業務數據分析的QuickSight,都能與其搭配。
上述這些雲端服務,都與S3有密切的關係,然而,在資料處理的效率上,仍有不少能夠改善的部分,例如,用戶在真正執行分析作業時,往往只會處理到每個物件資料裡面的一部分,而不是全部,而AWS也在2017年的re:Invent大會上,宣布新的服務,稱為S3 Select。
透過這套服務,用戶可從S3的物件裡面,透過標準SQL語法取出所要存取的局部資料,而毋須擷取整個物件、接著過濾出需要分析的資料,如此一來,可加速資料存取的過程,大大降低了初期載入的資料量,以及應用程式後續處理的資料量,效能提升的幅度可達到現有作法的4倍。
既然AWS針對許多人常用的S3資料儲存服務,開始提供變通的選擇性查詢,那麼,對於強調成本更低、資料可長期保存的Glacier,是否有對應的服務呢?
果不期然,他們接著就宣布Glacier Select了,用戶現在也能透過SQL語法的運用,查詢存放在Glacier的歸檔資料,可以只擷取出所需要的部份資料。因此,企業若要針對Glacier裡面存放的大量資料,執行稽核與模式比對,就會變得更容易。而這意味著,現在任何應用系統可以查詢Glacier裡面的資料,同時,也使得Glacier這套雲端儲存服務,正式成為資料湖環境的一種選擇。
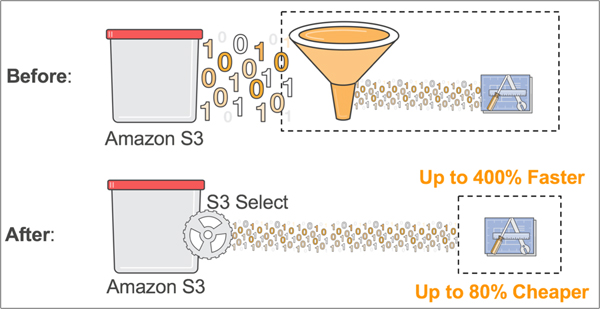
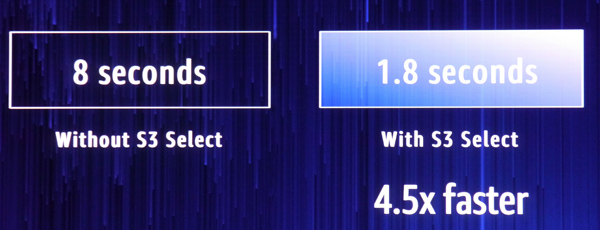
省時省力!AWS提供有效存取S3物件資料的新功能
Amazon S3提供的物件儲存環境,已成為雲端服務資料湖的主要選擇,AWS在2017全球用戶大會上,宣布推出S3 Select,應用程式在存取S3的物件資料時,可以先透過SQL語法來取出所需要的局部資料,毋須存取整個物件資料再行過濾處理,如此可大幅縮短應用程式的資料存取時間,進而改善效能。(圖片提供/AWS)。
熱門新聞

2026-03-06


2026-03-11




2026-03-06

2026-03-09