
Flink專案核心開發者戴資力表示,串流分析處理最大的問題,就是難以確認產出的數據是否正確,若處理過程中產生任何錯誤,開發者無法確認後續的資料會否受到影響。
iThome
大數據分析熱門話題,近幾年從批次分析,轉而聚焦在串流分析技術和架構,不只Hadoop推出Lambda雙資料流架構,新一代大數據平臺Spark爆紅,新興開源串流分析框架Flink也成為Apache頂級專案之一,阿里巴巴、Uber及Netflix等大型公司相繼採用Flink來打造大數據分析引擎。臺灣也不落人後,參與了這一波大數據技術演進的過程,其中,任職於臺灣新創公司VMFive軟體工程師戴資力,正是全球 23位維護Flink專案的核心開發者(Committer)之一。
戴資力表示,為了加強企業系統即時分析的需求,「必須重新探討Lambda架構是否存在問題,以及進行改善的空間。」例如,如何修改Lambda架構,滿足即時分析有態(Stateful)資料的需求,或是對有態資料進行常見資料庫的資料查詢操作。
不僅如此,甚至在國外也有人提出新觀念,試圖將資料庫元件抽離於大數據平臺中,直接利用串流處理器作為資料儲存媒介。
戴資力引用Twitter的營運數據作為例子,每月活躍使用人數超過3億,站方每秒必須處理超過1百萬則曝光(Impression)推文,在1小時內,使用者更會產生出破1億則不重複的曝光訊息。
而後端系統除了以1小時為單位,整合平臺上所有的訊息,並且將統計數據儲存至Key Value資料庫外,也要滿足即時串流需求,讓開發者可以產生任意時間區間內的統計報表。為了一次滿足批次處理、即時串流的需要,「大多都會採用Lambda架構。」
常見的批次處理流程中,通常資料會先利用Aka、Kafka等元件處理成便於批次處理的格式後,進一步引入HDFS等分散式檔案系統,透過Spark、Hadoop等大數據引擎,對資料進行映射(Map)、簡化(Reduce)的批次處理,最後儲存在Key Value資料庫中,讓使用者可以從前端介面撈取資料,執行Query服務。
而即時串流分析程序中,常常使用Kafka作為前端資料的接收器,經過Apache Storm、Spark等即時串流計算引擎,完成資料處理後,系統也會不停更新資料庫的內容,將最新結果儲存在資料庫快取區中,「經過1小時之後,快取區內儲存的數值就會歸零,重新計算。」
過去架構中,即時串流分析只是輔助
在設計大數據架構處理資料時,企業往往會利用Lambda架構讓資料進行雙分流處理,同時滿足批次程序以及串流分析的需求。但是,這個常見的架構,過去考量的設計理念,在於以批次處理為主,而串流分析作為輔助角色。
而在Lambda雙資料流架構的批次處理、即時串流分析流程,戴資力分別從每秒查詢次數(QPS,Queries Per Second)、容錯能力,以及計算結果正確性這三大面向,進行剖析、評估。
在批次任務中,雖然平臺得應付大量載入(Bulk Load)的工作任務,只要先前定義資料處理的時間區間,以及預先準備足夠運算資料,大致都能順利完成任務,「因為它算是容易掌握的工作,可以被歸類爲批次處理優點。」
在系統容錯方面,雖然Spark、Hadoop內建的機制相當完善,即便中間資料處理過程有誤,系統也都能確保程序正常執行。
「不過,批次處理系統所產出的統計結果,究竟是否正確?」戴資力舉例,像是資料流入分散式檔案系統時,表面上資料是按照使用者需求,以每小時為單位切分,「實際上資料不停地流入,只是開發者讓系統周期性地執行批次工作。」而部分Log資料,經過許多不同批次程序處理後,會產生一批當下無法處理的中介資料(Intermediate Data),「系統得要區分出這些中介資料,並將它們派送到另外的批次處理程序中運算。」
此外,批次處理先天不適合處理串流資料的特性,也會造成產出結果有誤。例如,當開發者明確定義以1小時為單位進行批次處理,可是「應該要整點到達的資料,卻延遲5分鐘後才到。」因此,按時啟動的批次處理程式,就無法及時處理到遲到的這批資料。
串流分析的先天不足
不止批次處理,即時串流分析也是存在不少問題。戴資力表示,串流程序處理的資料本身並不會記錄狀態(Stateless),而是儲存在外部的快取資料庫中。假設數據處理過程中產生任何錯誤,開發者無法確認後續的資料是否受到影響,「串流分析處理最大的問題,就是難以確認產出的數據是否正確。」也因此,在Lambda架構問世後,串流分析被認為較為不穩定,多半視它作為輔助角色,除了不能保障串流分析產出的結果全為正確,「即使快取資料失效,批次處理架構也有額外一份備份資料。」戴資力說。
另外,快取資料儲存的工作流量,與即時串流資料的流入量成正比,「要付出非常高的處理成本,而且系統很難進行水平擴充。」戴資力認為,這個弱點,對於Twitter這樣規模的網路公司,遲早會衍生出嚴重的效能瓶頸問題。
串流分析是Flink的核心
那麼現有的Lambda架構,究竟要如何利用同時支援批次處理、即時串流分析的Flink改善?戴資力認為,Flink的設計理念以資料串流(Data Stream)為核心,應將批次處理視為特例,採取有限串流(Bounded Streams)的作法。
先從批次處理的產生的困難切入,改善它先天不適合處理即時分析的特性,「如果無法支援處理有態資料的即時分析,很難把批次處理架構替換掉」,在此就要借助Flink支援有態資料的即時分析能力。
戴資力舉例,利用Kafka作為前端的資料收集器,再搭配Flink,同樣也可以完成資料的映射、簡化處理。而Flink底層每個運算子(Operator)皆為有態,「Kafka讀取到哪筆資料的記錄,都會儲存在Flink內部,不會另外將狀態資料儲存在外部資料庫。」
不過,這樣的架構還不足以替換掉Lambda架構,因為使用者並沒辦法即時取得資料,而且每隔一段時間所累積的資料,仍然要儲存在外部,「這樣就回到一個問題,使用者是否需要建置快取資料庫?」
假使有4筆相異的資料A、B、C及D,經過分流,資料A及B的狀態已經儲存在甲節點上;資料C與D則儲存在乙節點上,「其實Flink內部的State Management,已經默默內建了儲存Key Value的資料庫。」
既然Flink如此設計,同時它也支援有態資料即時串流分析,開發者就可直接執行Query操作,不需要建立額外的快取儲存。「執行Query、資料傳送都需要額外的I/O。」戴資力認為,如此就可以完整地取代Lambda架構,「Key Value儲存一樣存在,但不是只有特定時間才能取得資料」,即使批次處理還沒結束,使用者照樣可以執行Query操作,取得想要的資料。他也預告,在今年會推出的Flink 1.2版中,將會釋出可查詢狀態功能(Queryable State)。
雖然過去也有人提出Kappa架構,標榜所有資料全都是即時串流處理,然而,戴資力認為,當時串流處理器的技術還沒有很成熟,「還無法全面引入串流分析。」戴資力說。
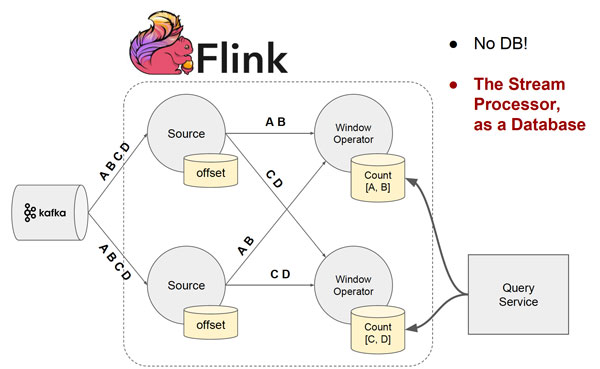
Flink專案核心開發者戴資力表示,雖然透過Flink,已經可以達到相當精簡架構,但是在更極端的設計中,還可以把Key Value資料庫定期儲存的資料,轉移到Flink,讓串流處理器做為資料庫。圖片來源/戴資力
精簡架構新思維:將串流處理器變成資料庫
不過這個看似已經非常精簡的架構,其實還是有修改空間。目前仍然需要建立Key Value資料庫及Query服務,才能讀取資料,「如果更極端的設計,把Key Value資料庫定期儲存的資料,轉移到Flink呢?」他笑說,目前他沒有辦法保證如此架構實作上沒有問題,但這也是國外IT界近年逐漸興起的概念:串流處理器即資料庫(Stream Processor as Database)。戴資力表示,如此一來,幾乎不需要外部資料庫元件存在了。
熱門新聞

2026-03-06

2026-03-06

2026-03-09


2026-03-09

2026-03-06

